 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGFuse: Interactive 3D Gaussian Scene Reconstruction via Multi-Scans Fusion
Aug 18, 2025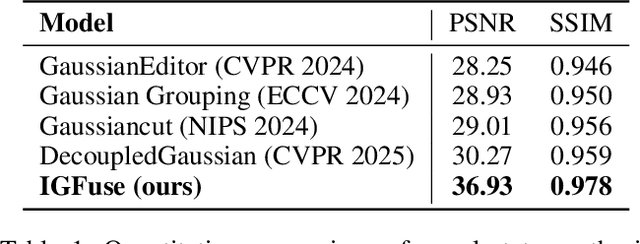
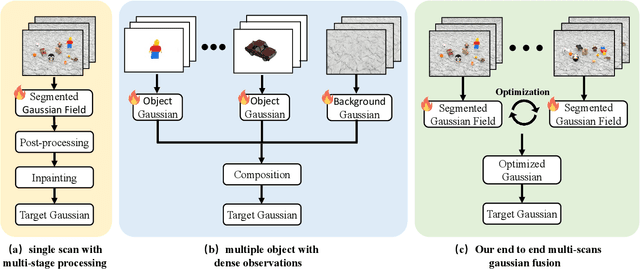
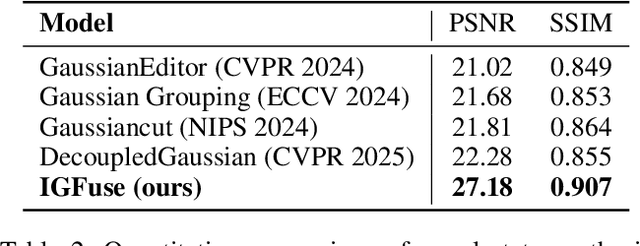
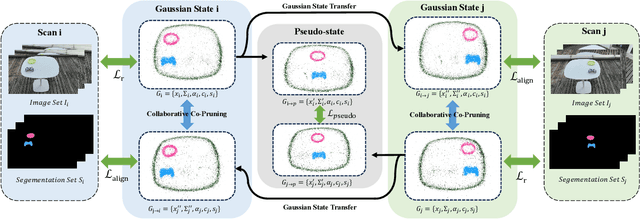
Reconstructing complete and interactive 3D scenes remains a fundamental challenge in computer vision and robotics, particularly due to persistent object occlusions and limited sensor coverage. Multiview observations from a single scene scan often fail to capture the full structural details. Existing approaches typically rely on multi stage pipelines, such as segmentation, background completion, and inpainting or require per-object dense scanning, both of which are error-prone, and not easily scalable. We propose IGFuse, a novel framework that reconstructs interactive Gaussian scene by fusing observations from multiple scans, where natural object rearrangement between captures reveal previously occluded regions. Our method constructs segmentation aware Gaussian fields and enforces bi-directional photometric and semantic consistency across scans. To handle spatial misalignments, we introduce a pseudo-intermediate scene state for unified alignment, alongside collaborative co-pruning strategies to refine geometry. IGFuse enables high fidelity rendering and object level scene manipulation without dense observations or complex pipelines. Extensive experiments validate the framework's strong generalization to novel scene configurations, demonstrating its effectiveness for real world 3D reconstruction and real-to-simulation transfer. Our project page is available online.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025



The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
Long-Tailed Distribution-Aware Router For Mixture-of-Experts in Large Vision-Language Model
Jul 02, 2025The mixture-of-experts (MoE), which replaces dense models with sparse architectures, has gained attention in large vision-language models (LVLMs) for achieving comparable performance with fewer activated parameters. Existing MoE frameworks for LVLMs focus on token-to-expert routing (TER), encouraging different experts to specialize in processing distinct tokens. However, these frameworks often rely on the load balancing mechanism, overlooking the inherent distributional differences between vision and language. To this end, we propose a Long-Tailed Distribution-aware Router (LTDR) for vision-language TER, tackling two challenges: (1) Distribution-aware router for modality-specific routing. We observe that language TER follows a uniform distribution, whereas vision TER exhibits a long-tailed distribution. This discrepancy necessitates distinct routing strategies tailored to each modality. (2) Enhancing expert activation for vision tail tokens. Recognizing the importance of vision tail tokens, we introduce an oversampling-like strategy by increasing the number of activated experts for these tokens. Experiments on extensive benchmarks validate the effectiveness of our approach.
SphereDrag: Spherical Geometry-Aware Panoramic Image Editing
Jun 13, 2025Image editing has made great progress on planar images, but panoramic image editing remains underexplored. Due to their spherical geometry and projection distortions, panoramic images present three key challenges: boundary discontinuity, trajectory deformation, and uneven pixel density. To tackle these issues, we propose SphereDrag, a novel panoramic editing framework utilizing spherical geometry knowledge for accurate and controllable editing. Specifically, adaptive reprojection (AR) uses adaptive spherical rotation to deal with discontinuity; great-circle trajectory adjustment (GCTA) tracks the movement trajectory more accurate; spherical search region tracking (SSRT) adaptively scales the search range based on spherical location to address uneven pixel density. Also, we construct PanoBench, a panoramic editing benchmark, including complex editing tasks involving multiple objects and diverse styles, which provides a standardized evaluation framework. Experiments show that SphereDrag gains a considerable improvement compared with existing methods in geometric consistency and image quality, achieving up to 10.5% relative improvement.
DSG-World: Learning a 3D Gaussian World Model from Dual State Videos
Jun 05, 2025Building an efficient and physically consistent world model from limited observations is a long standing challenge in vision and robotics. Many existing world modeling pipelines are based on implicit generative models, which are hard to train and often lack 3D or physical consistency. On the other hand, explicit 3D methods built from a single state often require multi-stage processing-such as segmentation, background completion, and inpainting-due to occlusions. To address this, we leverage two perturbed observations of the same scene under different object configurations. These dual states offer complementary visibility, alleviating occlusion issues during state transitions and enabling more stable and complete reconstruction. In this paper, we present DSG-World, a novel end-to-end framework that explicitly constructs a 3D Gaussian World model from Dual State observations. Our approach builds dual segmentation-aware Gaussian fields and enforces bidirectional photometric and semantic consistency. We further introduce a pseudo intermediate state for symmetric alignment and design collaborative co-pruning trategies to refine geometric completeness. DSG-World enables efficient real-to-simulation transfer purely in the explicit Gaussian representation space, supporting high-fidelity rendering and object-level scene manipulation without relying on dense observations or multi-stage pipelines. Extensive experiments demonstrate strong generalization to novel views and scene states, highlighting the effectiveness of our approach for real-world 3D reconstruction and simulation.
NeuroGen: Neural Network Parameter Generation via Large Language Models
May 18, 2025Acquiring the parameters of neural networks (NNs) has been one of the most important problems in machine learning since the inception of NNs. Traditional approaches, such as backpropagation and forward-only optimization, acquire parameters via iterative data fitting to gradually optimize them. This paper aims to explore the feasibility of a new direction: acquiring NN parameters via large language model generation. We propose NeuroGen, a generalized and easy-to-implement two-stage approach for NN parameter generation conditioned on descriptions of the data, task, and network architecture. Stage one is Parameter Reference Knowledge Injection, where LLMs are pretrained on NN checkpoints to build foundational understanding of parameter space, whereas stage two is Context-Enhanced Instruction Tuning, enabling LLMs to adapt to specific tasks through enriched, task-aware prompts. Experimental results demonstrate that NeuroGen effectively generates usable NN parameters. Our findings highlight the feasibility of LLM-based NN parameter generation and suggest a promising new paradigm where LLMs and lightweight NNs can coexist synergistically
PeerGuard: Defending Multi-Agent Systems Against Backdoor Attacks Through Mutual Reasoning
May 16, 2025Multi-agent systems leverage advanced AI models as autonomous agents that interact, cooperate, or compete to complete complex tasks across applications such as robotics and traffic management. Despite their growing importance, safety in multi-agent systems remains largely underexplored, with most research focusing on single AI models rather than interacting agents. This work investigates backdoor vulnerabilities in multi-agent systems and proposes a defense mechanism based on agent interactions. By leveraging reasoning abilities, each agent evaluates responses from others to detect illogical reasoning processes, which indicate poisoned agents. Experiments on LLM-based multi-agent systems, including ChatGPT series and Llama 3, demonstrate the effectiveness of the proposed method, achieving high accuracy in identifying poisoned agents while minimizing false positives on clean agents. We believe this work provides insights into multi-agent system safety and contributes to the development of robust, trustworthy AI interactions.
Mitigating Image Captioning Hallucinations in Vision-Language Models
May 06, 2025Hallucinations in vision-language models (VLMs) hinder reliability and real-world applicability, usually stemming from distribution shifts between pretraining data and test samples. Existing solutions, such as retraining or fine-tuning on additional data, demand significant computational resources and labor-intensive data collection, while ensemble-based methods incur additional costs by introducing auxiliary VLMs. To address these challenges, we propose a novel test-time adaptation framework using reinforcement learning to mitigate hallucinations during inference without retraining or any auxiliary VLMs. By updating only the learnable parameters in the layer normalization of the language model (approximately 0.003% of the model parameters), our method reduces distribution shifts between test samples and pretraining samples. A CLIP-based hallucination evaluation model is proposed to provide dual rewards to VLMs. Experimental results demonstrate a 15.4% and 17.3% reduction in hallucination rates on LLaVA and InstructBLIP, respectively. Our approach outperforms state-of-the-art baselines with a 68.3% improvement in hallucination mitigation, demonstrating its effectiveness.
Visibility-Uncertainty-guided 3D Gaussian Inpainting via Scene Conceptional Learning
Apr 23, 20253D Gaussian Splatting (3DGS) has emerged as a powerful and efficient 3D representation for novel view synthesis. This paper extends 3DGS capabilities to inpainting, where masked objects in a scene are replaced with new contents that blend seamlessly with the surroundings. Unlike 2D image inpainting, 3D Gaussian inpainting (3DGI) is challenging in effectively leveraging complementary visual and semantic cues from multiple input views, as occluded areas in one view may be visible in others. To address this, we propose a method that measures the visibility uncertainties of 3D points across different input views and uses them to guide 3DGI in utilizing complementary visual cues. We also employ uncertainties to learn a semantic concept of scene without the masked object and use a diffusion model to fill masked objects in input images based on the learned concept. Finally, we build a novel 3DGI framework, VISTA, by integrating VISibility-uncerTainty-guided 3DGI with scene conceptuAl learning. VISTA generates high-quality 3DGS models capable of synthesizing artifact-free and naturally inpainted novel views. Furthermore, our approach extends to handling dynamic distractors arising from temporal object changes, enhancing its versatility in diverse scene reconstruction scenarios. We demonstrate the superior performance of our method over state-of-the-art techniques using two challenging datasets: the SPIn-NeRF dataset, featuring 10 diverse static 3D inpainting scenes, and an underwater 3D inpainting dataset derived from UTB180, including fast-moving fish as inpainting targets.
RealCam-Vid: High-resolution Video Dataset with Dynamic Scenes and Metric-scale Camera Movements
Apr 11, 2025


Recent advances in camera-controllable video generation have been constrained by the reliance on static-scene datasets with relative-scale camera annotations, such as RealEstate10K. While these datasets enable basic viewpoint control, they fail to capture dynamic scene interactions and lack metric-scale geometric consistency-critical for synthesizing realistic object motions and precise camera trajectories in complex environments. To bridge this gap, we introduce the first fully open-source, high-resolution dynamic-scene dataset with metric-scale camera annotations in https://github.com/ZGCTroy/RealCam-Vid.