 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Robust Rubric Rewards
May 28, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) is effective for deterministically checkable tasks, many vision-language tasks are partially verifiable, demanding multi-criteria supervision (e.g., perceptual details, reasoning steps, and constraints). Rubrics provide a natural interface for this fine-grained supervision, but their effectiveness depends on the execution accuracy during online RL. We propose Reinforcement Learning with Robust Rubric Rewards ($\text{RLR}^3$), extending RLVR from task-level verification to criterion-level verification. $\text{RLR}^3$ routes instance-specific rubrics through two execution paths: an LLM-as-an-extractor paired with a deterministic verifier, or an LLM-as-a-Judge for non-verifiable criteria. To ensure faithful scoring, $\text{RLR}^3$ introduce a minimal exposure strategy that masks ground truths from extractors and images from judges. Furthermore, $\text{RLR}^3$ employs hierarchical aggregation to prioritize essential criteria over additional criteria, and mitigates score saturation within rollout groups. Evaluated on Qwen3-VL-30B-A3B across 15 benchmarks, $\text{RLR}^3$ consistently outperforms RLVR, yielding a 4.7-point improvement over the base model and exceeding the official instruct-to-thinking model gap. Controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives.
Visual Preference Optimization with Rubric Rewards
Apr 14, 2026The effectiveness of Direct Preference Optimization (DPO) depends on preference data that reflect the quality differences that matter in multimodal tasks. Existing pipelines often rely on off-policy perturbations or coarse outcome-based signals, which are not well suited to fine-grained visual reasoning. We propose rDPO, a preference optimization framework based on instance-specific rubrics. For each image-instruction pair, we create a checklist-style rubric of essential and additional criteria to score responses from any possible policies. The instruction-rubric pool is built offline and reused during the construction of on-policy data. On public reward modeling benchmarks, rubric-based prompting massively improves a 30B-A3B judge and brings it close to GPT-5.4. On public downstream benchmarks, rubric-based filtering raises the macro average to 82.69, whereas outcome-based filtering drops it to 75.82 from 81.14. When evaluating scalability on a comprehensive benchmark, rDPO achieves 61.01, markedly outperforming the style-constrained baseline (52.36) and surpassing the 59.48 base model. Together, these results show that visual preference optimization benefits from combining on-policy data construction with instance-specific criterion-level feedback.
Deep-XFCT: Deep learning 3D-mineral liberation analysis with micro X-ray fluorescence and computed tomography
May 26, 2022
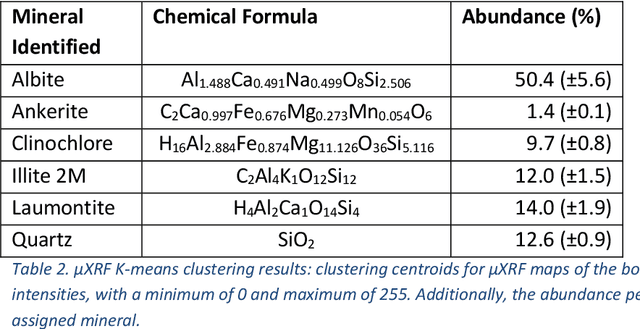
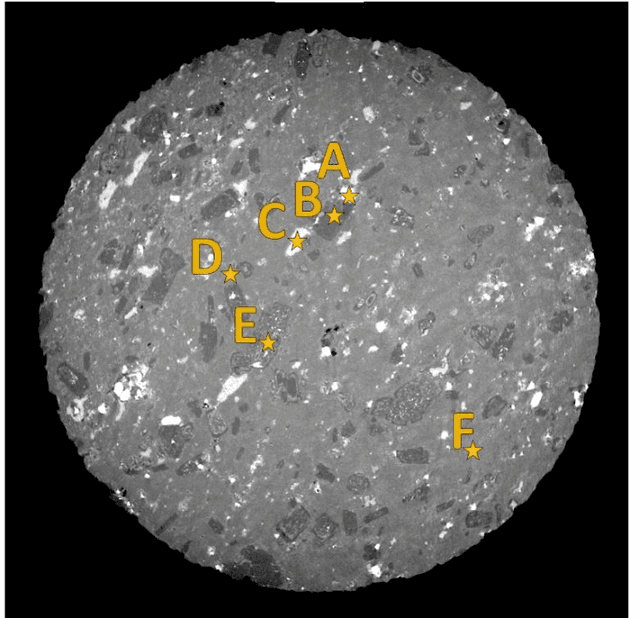
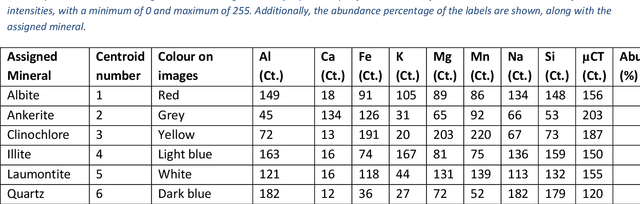
The rapid development of X-ray micro-computed tomography (micro-CT) opens new opportunities for 3D analysis of particle and grain-size characterisation, determination of particle densities and shape factors, estimation of mineral associations and liberation and locking. Current practices in mineral liberation analysis are based on 2D representations leading to systematic errors in the extrapolation to volumetric properties. New quantitative methods based on tomographic data are therefore urgently required for characterisation of mineral deposits, mineral processing, characterisation of tailings, rock typing, stratigraphic refinement, reservoir characterisation for applications in the resource industry, environmental and material sciences. To date, no simple non-destructive method exists for 3D mineral liberation analysis. We present a new development based on combining micro-CT with micro-X-ray fluorescence (micro-XRF) using deep learning. We demonstrate successful semi-automated multi-modal analysis of a crystalline magmatic rock where the new technique overcomes the difficult task of differentiating feldspar from quartz in micro-CT data set. The approach is universal and can be extended to any multi-modal and multi-instrument analysis for further refinement. We conclude that the combination of micro-CT and micro-XRF already provides a new opportunity for robust 3D mineral liberation analysis in both field and laboratory applications.
A Probabilistic End-To-End Task-Oriented Dialog Model with Latent Belief States towards Semi-Supervised Learning
Oct 13, 2020
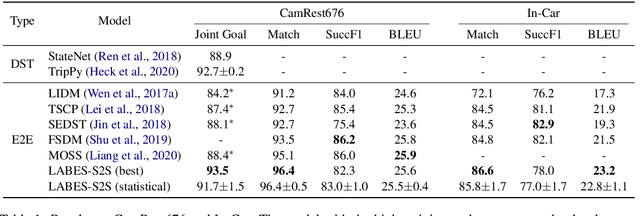
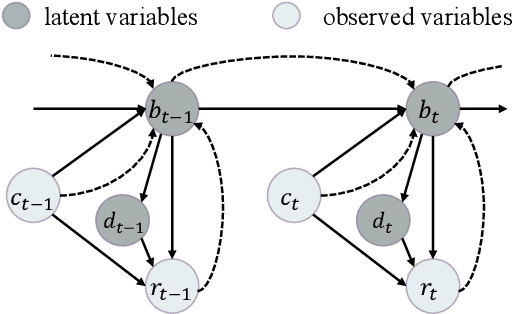
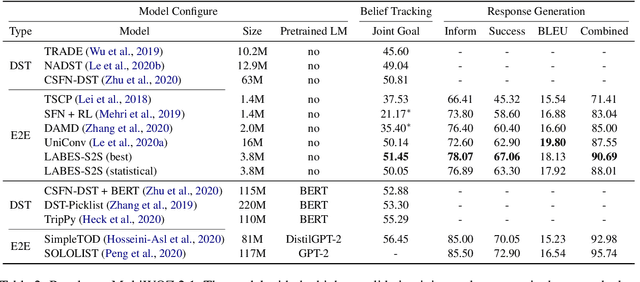
Structured belief states are crucial for user goal tracking and database query in task-oriented dialog systems. However, training belief trackers often requires expensive turn-level annotations of every user utterance. In this paper we aim at alleviating the reliance on belief state labels in building end-to-end dialog systems, by leveraging unlabeled dialog data towards semi-supervised learning. We propose a probabilistic dialog model, called the LAtent BElief State (LABES) model, where belief states are represented as discrete latent variables and jointly modeled with system responses given user inputs. Such latent variable modeling enables us to develop semi-supervised learning under the principled variational learning framework. Furthermore, we introduce LABES-S2S, which is a copy-augmented Seq2Seq model instantiation of LABES. In supervised experiments, LABES-S2S obtains strong results on three benchmark datasets of different scales. In utilizing unlabeled dialog data, semi-supervised LABES-S2S significantly outperforms both supervised-only and semi-supervised baselines. Remarkably, we can reduce the annotation demands to 50% without performance loss on MultiWOZ.