 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGA-MCTS: Decoupling Planning from Execution via Training-Free Atomic Experience Retrieval
Apr 16, 2026LLM-powered systems require complex multi-step decision-making abilities to solve real-world tasks, yet current planning approaches face a trade-off between the high latency of inference-time search and the limited generalization of supervised fine-tuning. To address this limitation, we introduce \textbf{SGA-MCTS}, a framework that casts LLM planning as non-parametric retrieval. Offline, we leverage Monte Carlo Tree Search (MCTS) to explore the solution space and distill high-fidelity trajectories into State-Goal-Action (SGA) atoms. These atoms are de-lexicalized primitives that abstract concrete entities into symbolic slots, preserving reusable causal logic while discarding domain-specific noise. Online, a retrieval-augmented agent employs a hybrid symbolic-semantic mechanism to fetch relevant SGAs and re-ground them into the current context as soft reasoning hints. Empirical results on complex benchmarks demonstrate that this paradigm enables frozen, open-weights models to match the performance of SOTA systems (e.g., GPT-5) without task-specific fine-tuning. By effectively amortizing the heavy computational cost of search, SGA-MCTS achieves System 2 reasoning depth at System 1 inference speeds, rendering autonomous planning both scalable and real-time feasible.
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Apr 06, 2026Learning from experience is critical for building capable large language model (LLM) agents, yet prevailing self-evolving paradigms remain inefficient: agents learn in isolation, repeatedly rediscover similar behaviors from limited experience, resulting in redundant exploration and poor generalization. To address this problem, we propose SkillX, a fully automated framework for constructing a \textbf{plug-and-play skill knowledge base} that can be reused across agents and environments. SkillX operates through a fully automated pipeline built on three synergistic innovations: \textit{(i) Multi-Level Skills Design}, which distills raw trajectories into three-tiered hierarchy of strategic plans, functional skills, and atomic skills; \textit{(ii) Iterative Skills Refinement}, which automatically revises skills based on execution feedback to continuously improve library quality; and \textit{(iii) Exploratory Skills Expansion}, which proactively generates and validates novel skills to expand coverage beyond seed training data. Using a strong backbone agent (GLM-4.6), we automatically build a reusable skill library and evaluate its transferability on challenging long-horizon, user-interactive benchmarks, including AppWorld, BFCL-v3, and $τ^2$-Bench. Experiments show that SkillKB consistently improves task success and execution efficiency when plugged into weaker base agents, highlighting the importance of structured, hierarchical experience representations for generalizable agent learning. Our code will be publicly available soon at https://github.com/zjunlp/SkillX.
Accelerating Monte Carlo Bayesian Inference via Approximating Predictive Uncertainty over Simplex
May 29, 2019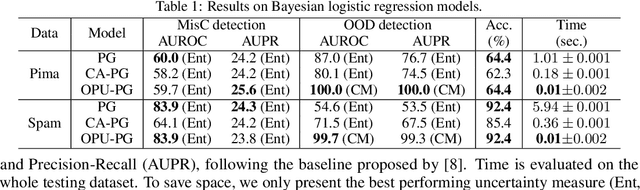
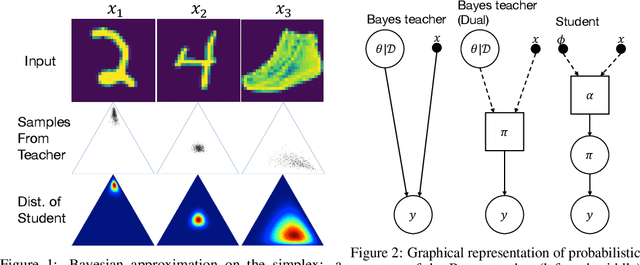
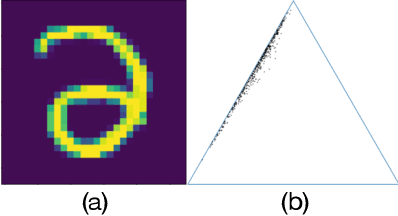
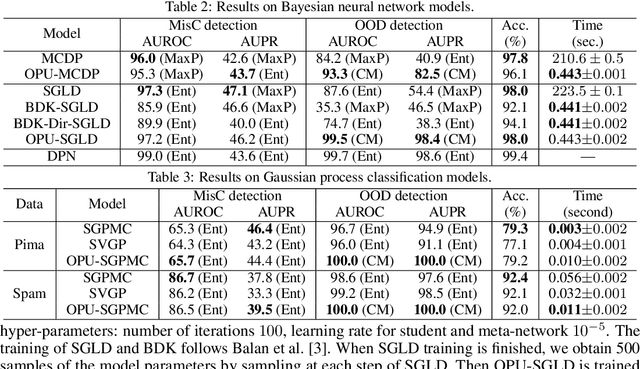
Estimating the uncertainty of a Bayesian model has been investigated for decades. The model posterior is almost always intractable, such that approximation is necessary. In many real-world cases, even though a decent estimation of the model posterior is obtained, another approximation is required to compute the predictive distribution over the desired output. A common accurate solution is to use Monte Carlo (MC) integration. However, it needs to maintain a large number of samples, evaluate the model repeatedly and average multiple model outputs. In this paper, we propose a method to approximate the probability distribution over the simplex induced by model posterior, enabling tractable computation of the predictive distribution for classification. The aim is to approximate the induced uncertainty of a specific Bayesian model, meanwhile alleviating the heavy workload of MC integration in testing time. Methodologically, we adapt Wasserstein distance to learn the induced conditional distributions, which is novel for Bayesian learning. The proposed method is universally applicable to Bayesian classification models that allow for posterior sampling. Empirical results validate the strong practical performance of our approach.