 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
May 01, 2024



Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.
InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning
Apr 03, 2024Continual learning requires the model to learn multiple tasks sequentially. In continual learning, the model should possess the ability to maintain its performance on old tasks (stability) and the ability to adapt to new tasks continuously (plasticity). Recently, parameter-efficient fine-tuning (PEFT), which involves freezing a pre-trained model and injecting a small number of learnable parameters to adapt to downstream tasks, has gained increasing popularity in continual learning. Although existing continual learning methods based on PEFT have demonstrated superior performance compared to those not based on PEFT, most of them do not consider how to eliminate the interference of the new task on the old tasks, which inhibits the model from making a good trade-off between stability and plasticity. In this work, we propose a new PEFT method, called interference-free low-rank adaptation (InfLoRA), for continual learning. InfLoRA injects a small number of parameters to reparameterize the pre-trained weights and shows that fine-tuning these injected parameters is equivalent to fine-tuning the pre-trained weights within a subspace. Furthermore, InfLoRA designs this subspace to eliminate the interference of the new task on the old tasks, making a good trade-off between stability and plasticity. Experimental results show that InfLoRA outperforms existing state-of-the-art continual learning methods on multiple datasets.
UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming
Jul 31, 2023



Deep learning models have demonstrated impressive performance in various domains. However, the prolonged training time of these models remains a critical problem. Manually designed parallel training strategies could enhance efficiency but require considerable time and deliver little flexibility. Hence, automatic parallelism is proposed to automate the parallel strategy searching process. Even so, existing approaches suffer from sub-optimal strategy space because they treat automatic parallelism as two independent stages, namely inter- and intra-layer parallelism. To address this issue, we propose UniAP, which utilizes mixed integer quadratic programming to unify inter- and intra-layer automatic parallelism. To the best of our knowledge, UniAP is the first work to unify these two categories to search for a globally optimal strategy. The experimental results show that UniAP outperforms state-of-the-art methods by up to 1.70$\times$ in throughput and reduces strategy searching time by up to 16$\times$ across four Transformer-like models.
On the Optimal Batch Size for Byzantine-Robust Distributed Learning
May 23, 2023



Byzantine-robust distributed learning (BRDL), in which computing devices are likely to behave abnormally due to accidental failures or malicious attacks, has recently become a hot research topic. However, even in the independent and identically distributed (i.i.d.) case, existing BRDL methods will suffer from a significant drop on model accuracy due to the large variance of stochastic gradients. Increasing batch sizes is a simple yet effective way to reduce the variance. However, when the total number of gradient computation is fixed, a too-large batch size will lead to a too-small iteration number (update number), which may also degrade the model accuracy. In view of this challenge, we mainly study the optimal batch size when the total number of gradient computation is fixed in this work. In particular, we theoretically and empirically show that when the total number of gradient computation is fixed, the optimal batch size in BRDL increases with the fraction of Byzantine workers. Therefore, compared to the case without attacks, the batch size should be set larger when under Byzantine attacks. However, for existing BRDL methods, large batch sizes will lead to a drop on model accuracy, even if there is no Byzantine attack. To deal with this problem, we propose a novel BRDL method, called Byzantine-robust stochastic gradient descent with normalized momentum (ByzSGDnm), which can alleviate the drop on model accuracy in large-batch cases. Moreover, we theoretically prove the convergence of ByzSGDnm for general non-convex cases under Byzantine attacks. Empirical results show that ByzSGDnm has a comparable performance to existing BRDL methods under bit-flipping failure, but can outperform existing BRDL methods under deliberately crafted attacks.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023



Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
FedREP: A Byzantine-Robust, Communication-Efficient and Privacy-Preserving Framework for Federated Learning
Mar 09, 2023



Federated learning (FL) has recently become a hot research topic, in which Byzantine robustness, communication efficiency and privacy preservation are three important aspects. However, the tension among these three aspects makes it hard to simultaneously take all of them into account. In view of this challenge, we theoretically analyze the conditions that a communication compression method should satisfy to be compatible with existing Byzantine-robust methods and privacy-preserving methods. Motivated by the analysis results, we propose a novel communication compression method called consensus sparsification (ConSpar). To the best of our knowledge, ConSpar is the first communication compression method that is designed to be compatible with both Byzantine-robust methods and privacy-preserving methods. Based on ConSpar, we further propose a novel FL framework called FedREP, which is Byzantine-robust, communication-efficient and privacy-preserving. We theoretically prove the Byzantine robustness and the convergence of FedREP. Empirical results show that FedREP can significantly outperform communication-efficient privacy-preserving baselines. Furthermore, compared with Byzantine-robust communication-efficient baselines, FedREP can achieve comparable accuracy with the extra advantage of privacy preservation.
Asymmetric Learning for Graph Neural Network based Link Prediction
Mar 01, 2023



Link prediction is a fundamental problem in many graph based applications, such as protein-protein interaction prediction. Graph neural network (GNN) has recently been widely used for link prediction. However, existing GNN based link prediction (GNN-LP) methods suffer from scalability problem during training for large-scale graphs, which has received little attention by researchers. In this paper, we first give computation complexity analysis of existing GNN-LP methods, which reveals that the scalability problem stems from their symmetric learning strategy adopting the same class of GNN models to learn representation for both head and tail nodes. Then we propose a novel method, called asymmetric learning (AML), for GNN-LP. The main idea of AML is to adopt a GNN model for learning head node representation while using a multi-layer perceptron (MLP) model for learning tail node representation. Furthermore, AML proposes a row-wise sampling strategy to generate mini-batch for training, which is a necessary component to make the asymmetric learning strategy work for training speedup. To the best of our knowledge, AML is the first GNN-LP method adopting an asymmetric learning strategy for node representation learning. Experiments on three real large-scale datasets show that AML is 1.7X~7.3X faster in training than baselines with a symmetric learning strategy, while having almost no accuracy loss.
Optimizing Class Distribution in Memory for Multi-Label Online Continual Learning
Sep 23, 2022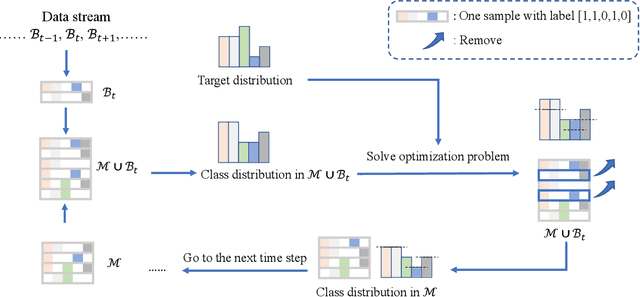
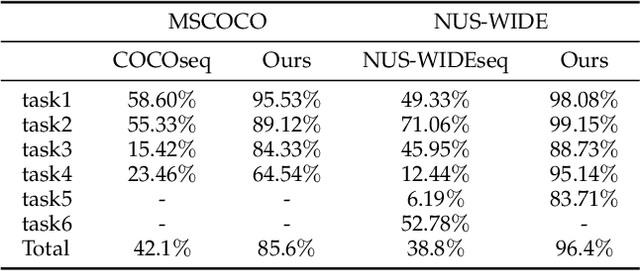
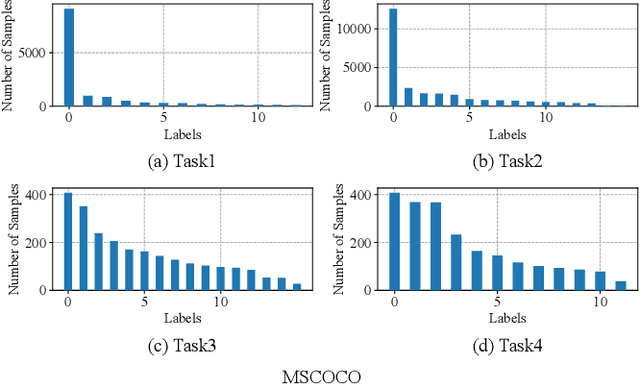
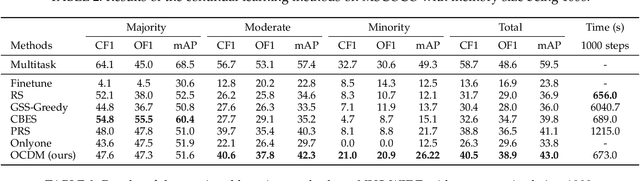
Online continual learning, especially when task identities and task boundaries are unavailable, is a challenging continual learning setting. One representative kind of methods for online continual learning is replay-based methods, in which a replay buffer called memory is maintained to keep a small part of past samples for overcoming catastrophic forgetting. When tackling with online continual learning, most existing replay-based methods focus on single-label problems in which each sample in the data stream has only one label. But multi-label problems may also happen in the online continual learning setting in which each sample may have more than one label. In the online setting with multi-label samples, the class distribution in data stream is typically highly imbalanced, and it is challenging to control class distribution in memory since changing the number of samples belonging to one class may affect the number of samples belonging to other classes. But class distribution in memory is critical for replay-based memory to get good performance, especially when the class distribution in data stream is highly imbalanced. In this paper, we propose a simple but effective method, called optimizing class distribution in memory (OCDM), for multi-label online continual learning. OCDM formulates the memory update mechanism as an optimization problem and updates the memory by solving this problem. Experiments on two widely used multi-label datasets show that OCDM can control the class distribution in memory well and can outperform other state-of-the-art methods.
State-based Episodic Memory for Multi-Agent Reinforcement Learning
Oct 19, 2021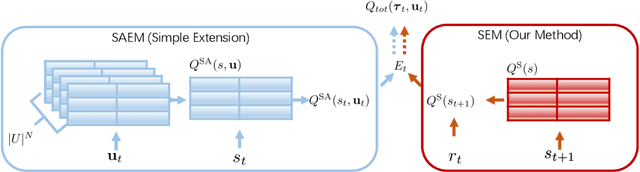

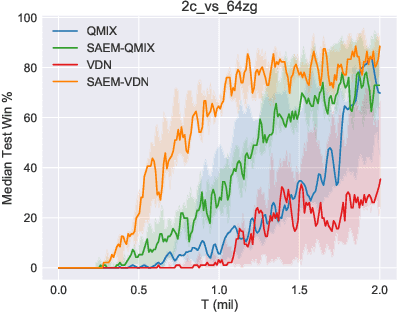
Multi-agent reinforcement learning (MARL) algorithms have made promising progress in recent years by leveraging the centralized training and decentralized execution (CTDE) paradigm. However, existing MARL algorithms still suffer from the sample inefficiency problem. In this paper, we propose a simple yet effective approach, called state-based episodic memory (SEM), to improve sample efficiency in MARL. SEM adopts episodic memory (EM) to supervise the centralized training procedure of CTDE in MARL. To the best of our knowledge, SEM is the first work to introduce EM into MARL. We can theoretically prove that, when using for MARL, SEM has lower space complexity and time complexity than state and action based EM (SAEM), which is originally proposed for single-agent reinforcement learning. Experimental results on StarCraft multi-agent challenge (SMAC) show that introducing episodic memory into MARL can improve sample efficiency and SEM can reduce storage cost and time cost compared with SAEM.
Cross Domain Robot Imitation with Invariant Representation
Sep 13, 2021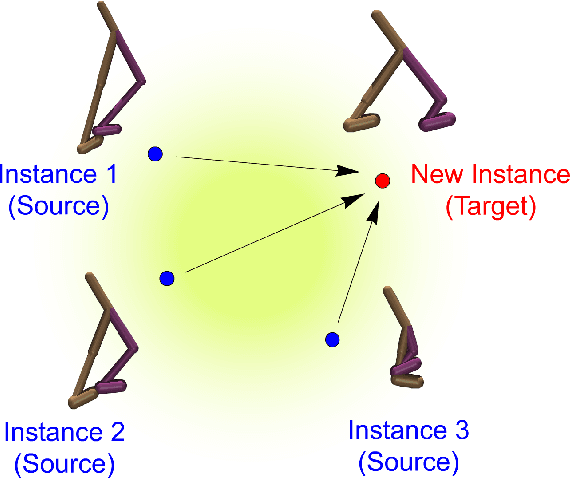
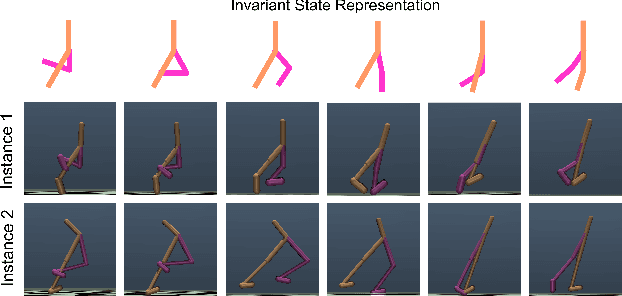
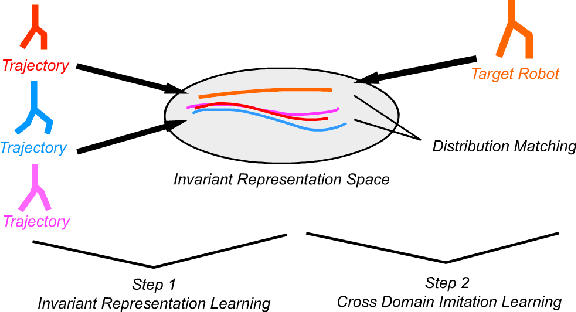
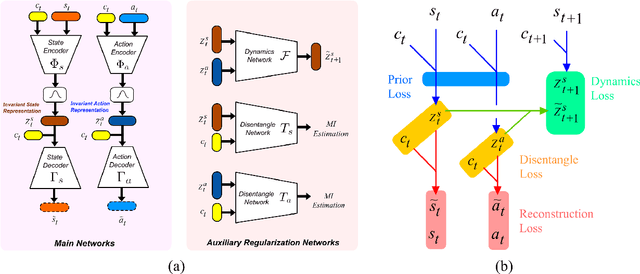
Animals are able to imitate each others' behavior, despite their difference in biomechanics. In contrast, imitating the other similar robots is a much more challenging task in robotics. This problem is called cross domain imitation learning~(CDIL). In this paper, we consider CDIL on a class of similar robots. We tackle this problem by introducing an imitation learning algorithm based on invariant representation. We propose to learn invariant state and action representations, which aligns the behavior of multiple robots so that CDIL becomes possible. Compared with previous invariant representation learning methods for similar purpose, our method does not require human-labeled pairwise data for training. Instead, we use cycle-consistency and domain confusion to align the representation and increase its robustness. We test the algorithm on multiple robots in simulator and show that unseen new robot instances can be trained with existing expert demonstrations successfully. Qualitative results also demonstrate that the proposed method is able to learn similar representations for different robots with similar behaviors, which is essential for successful CDIL.