 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdered Momentum for Asynchronous SGD
Jul 27, 2024



Distributed learning is indispensable for training large-scale deep models. Asynchronous SGD~(ASGD) and its variants are commonly used distributed learning methods in many scenarios where the computing capabilities of workers in the cluster are heterogeneous. Momentum has been acknowledged for its benefits in both optimization and generalization in deep model training. However, existing works have found that naively incorporating momentum into ASGD can impede the convergence. In this paper, we propose a novel method, called ordered momentum (OrMo), for ASGD. In OrMo, momentum is incorporated into ASGD by organizing the gradients in order based on their iteration indexes. We theoretically prove the convergence of OrMo for non-convex problems. To the best of our knowledge, this is the first work to establish the convergence analysis of ASGD with momentum without relying on the bounded delay assumption. Empirical results demonstrate that OrMo can achieve better convergence performance compared with ASGD and other asynchronous methods with momentum.
Buffered Asynchronous Secure Aggregation for Cross-Device Federated Learning
Jun 05, 2024



Asynchronous federated learning (AFL) is an effective method to address the challenge of device heterogeneity in cross-device federated learning. However, AFL is usually incompatible with existing secure aggregation protocols used to protect user privacy in federated learning because most existing secure aggregation protocols are based on synchronous aggregation. To address this problem, we propose a novel secure aggregation protocol named buffered asynchronous secure aggregation (BASA) in this paper. Compared with existing protocols, BASA is fully compatible with AFL and provides secure aggregation under the condition that each user only needs one round of communication with the server without relying on any synchronous interaction among users. Based on BASA, we propose the first AFL method which achieves secure aggregation without extra requirements on hardware. We empirically demonstrate that BASA outperforms existing secure aggregation protocols for cross-device federated learning in terms of training efficiency and scalability.
On the Optimal Batch Size for Byzantine-Robust Distributed Learning
May 23, 2023



Byzantine-robust distributed learning (BRDL), in which computing devices are likely to behave abnormally due to accidental failures or malicious attacks, has recently become a hot research topic. However, even in the independent and identically distributed (i.i.d.) case, existing BRDL methods will suffer from a significant drop on model accuracy due to the large variance of stochastic gradients. Increasing batch sizes is a simple yet effective way to reduce the variance. However, when the total number of gradient computation is fixed, a too-large batch size will lead to a too-small iteration number (update number), which may also degrade the model accuracy. In view of this challenge, we mainly study the optimal batch size when the total number of gradient computation is fixed in this work. In particular, we theoretically and empirically show that when the total number of gradient computation is fixed, the optimal batch size in BRDL increases with the fraction of Byzantine workers. Therefore, compared to the case without attacks, the batch size should be set larger when under Byzantine attacks. However, for existing BRDL methods, large batch sizes will lead to a drop on model accuracy, even if there is no Byzantine attack. To deal with this problem, we propose a novel BRDL method, called Byzantine-robust stochastic gradient descent with normalized momentum (ByzSGDnm), which can alleviate the drop on model accuracy in large-batch cases. Moreover, we theoretically prove the convergence of ByzSGDnm for general non-convex cases under Byzantine attacks. Empirical results show that ByzSGDnm has a comparable performance to existing BRDL methods under bit-flipping failure, but can outperform existing BRDL methods under deliberately crafted attacks.
FedREP: A Byzantine-Robust, Communication-Efficient and Privacy-Preserving Framework for Federated Learning
Mar 09, 2023



Federated learning (FL) has recently become a hot research topic, in which Byzantine robustness, communication efficiency and privacy preservation are three important aspects. However, the tension among these three aspects makes it hard to simultaneously take all of them into account. In view of this challenge, we theoretically analyze the conditions that a communication compression method should satisfy to be compatible with existing Byzantine-robust methods and privacy-preserving methods. Motivated by the analysis results, we propose a novel communication compression method called consensus sparsification (ConSpar). To the best of our knowledge, ConSpar is the first communication compression method that is designed to be compatible with both Byzantine-robust methods and privacy-preserving methods. Based on ConSpar, we further propose a novel FL framework called FedREP, which is Byzantine-robust, communication-efficient and privacy-preserving. We theoretically prove the Byzantine robustness and the convergence of FedREP. Empirical results show that FedREP can significantly outperform communication-efficient privacy-preserving baselines. Furthermore, compared with Byzantine-robust communication-efficient baselines, FedREP can achieve comparable accuracy with the extra advantage of privacy preservation.
BASGD: Buffered Asynchronous SGD for Byzantine Learning
Mar 03, 2020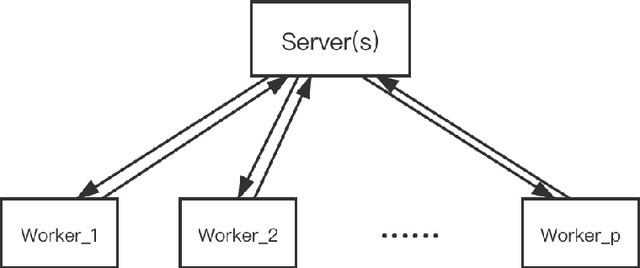
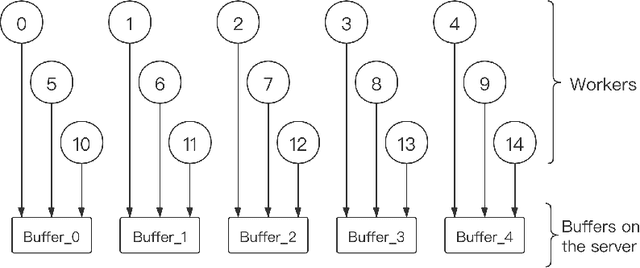
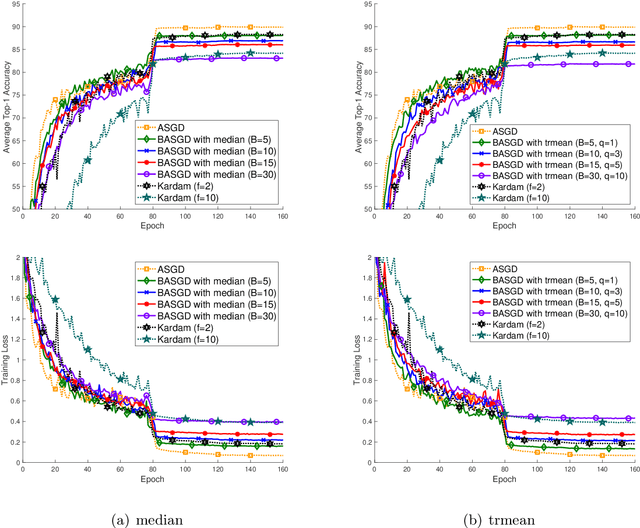
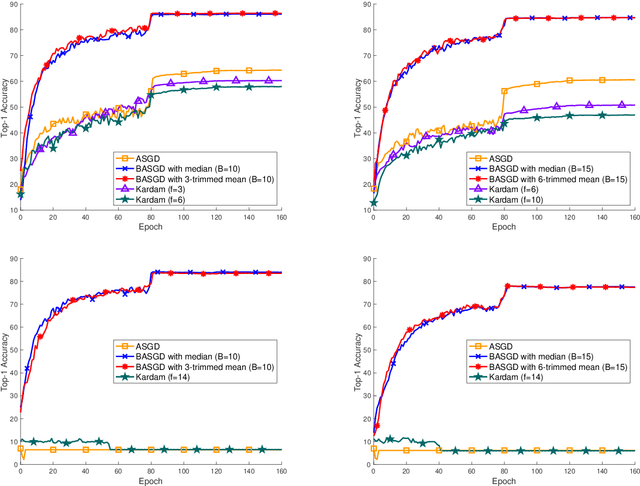
Distributed learning has become a hot research topic, due to its wide application in cluster-based large-scale learning, federated learning, edge computing and so on. Most distributed learning methods assume no error and attack on the workers. However, many unexpected cases, such as communication error and even malicious attack, may happen in real applications. Hence, Byzantine learning (BL), which refers to distributed learning with attack or error, has recently attracted much attention. Most existing BL methods are synchronous, which will result in slow convergence when there exist heterogeneous workers. Furthermore, in some applications like federated learning and edge computing, synchronization cannot even be performed most of the time due to the online workers (clients or edge servers). Hence, asynchronous BL (ABL) is more general and practical than synchronous BL (SBL). To the best of our knowledge, there exist only two ABL methods. One of them cannot resist malicious attack. The other needs to store some training instances on the server, which has the privacy leak problem. In this paper, we propose a novel method, called buffered asynchronous stochastic gradient descent (BASGD), for BL. BASGD is an asynchronous method. Furthermore, BASGD has no need to store any training instances on the server, and hence can preserve privacy in ABL. BASGD is theoretically proved to have the ability of resisting against error and malicious attack. Moreover, BASGD has a similar theoretical convergence rate to that of vanilla asynchronous SGD (ASGD), with an extra constant variance. Empirical results show that BASGD can significantly outperform vanilla ASGD and other ABL baselines, when there exists error or attack on workers.