 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Integration of Low-Rank Adaptation for Continual Learning of Language Models
May 21, 2025Continual learning (CL), which requires the model to learn multiple tasks sequentially, is crucial for language models (LMs). Recently, low-rank adaptation (LoRA), one of the most representative parameter-efficient fine-tuning (PEFT) methods, has gained increasing attention in CL of LMs. However, most existing CL methods based on LoRA typically expand a new LoRA branch to learn each new task and force the new and old LoRA branches to contribute equally to old tasks, potentially leading to forgetting. In this work, we propose a new method, called gated integration of low-rank adaptation (GainLoRA), for CL of LMs. GainLoRA expands a new LoRA branch for each new task and introduces gating modules to integrate the new and old LoRA branches. Furthermore, GainLoRA leverages the new gating module to minimize the contribution from the new LoRA branch to old tasks, effectively mitigating forgetting and improving the model's overall performance. Experimental results on CL benchmarks demonstrate that GainLoRA outperforms existing state-of-the-art methods.
InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning
Apr 03, 2024Continual learning requires the model to learn multiple tasks sequentially. In continual learning, the model should possess the ability to maintain its performance on old tasks (stability) and the ability to adapt to new tasks continuously (plasticity). Recently, parameter-efficient fine-tuning (PEFT), which involves freezing a pre-trained model and injecting a small number of learnable parameters to adapt to downstream tasks, has gained increasing popularity in continual learning. Although existing continual learning methods based on PEFT have demonstrated superior performance compared to those not based on PEFT, most of them do not consider how to eliminate the interference of the new task on the old tasks, which inhibits the model from making a good trade-off between stability and plasticity. In this work, we propose a new PEFT method, called interference-free low-rank adaptation (InfLoRA), for continual learning. InfLoRA injects a small number of parameters to reparameterize the pre-trained weights and shows that fine-tuning these injected parameters is equivalent to fine-tuning the pre-trained weights within a subspace. Furthermore, InfLoRA designs this subspace to eliminate the interference of the new task on the old tasks, making a good trade-off between stability and plasticity. Experimental results show that InfLoRA outperforms existing state-of-the-art continual learning methods on multiple datasets.
Optimizing Class Distribution in Memory for Multi-Label Online Continual Learning
Sep 23, 2022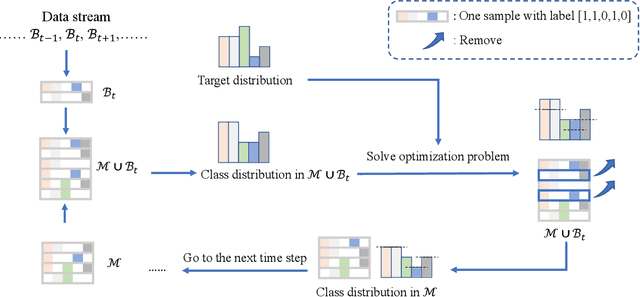
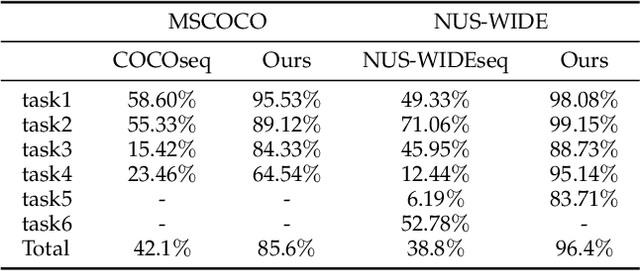
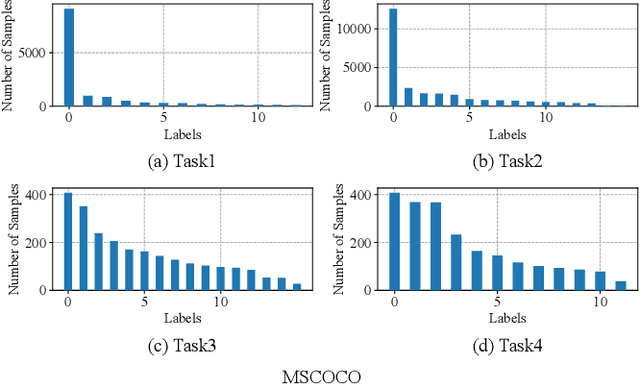
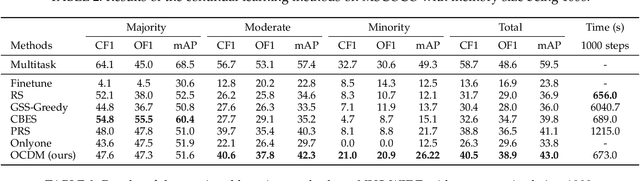
Online continual learning, especially when task identities and task boundaries are unavailable, is a challenging continual learning setting. One representative kind of methods for online continual learning is replay-based methods, in which a replay buffer called memory is maintained to keep a small part of past samples for overcoming catastrophic forgetting. When tackling with online continual learning, most existing replay-based methods focus on single-label problems in which each sample in the data stream has only one label. But multi-label problems may also happen in the online continual learning setting in which each sample may have more than one label. In the online setting with multi-label samples, the class distribution in data stream is typically highly imbalanced, and it is challenging to control class distribution in memory since changing the number of samples belonging to one class may affect the number of samples belonging to other classes. But class distribution in memory is critical for replay-based memory to get good performance, especially when the class distribution in data stream is highly imbalanced. In this paper, we propose a simple but effective method, called optimizing class distribution in memory (OCDM), for multi-label online continual learning. OCDM formulates the memory update mechanism as an optimization problem and updates the memory by solving this problem. Experiments on two widely used multi-label datasets show that OCDM can control the class distribution in memory well and can outperform other state-of-the-art methods.