 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Neural Machine Translation:Can Linguistic Hierarchies Help?
Oct 15, 2021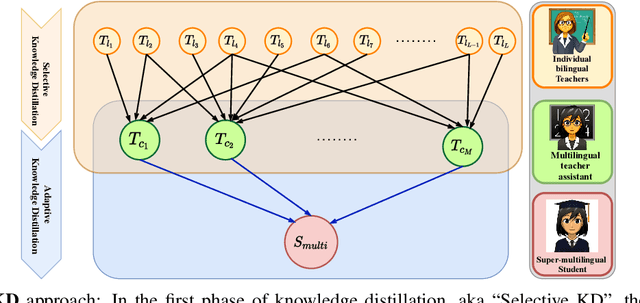
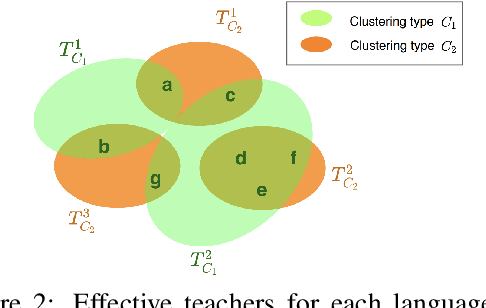

Multilingual Neural Machine Translation (MNMT) trains a single NMT model that supports translation between multiple languages, rather than training separate models for different languages. Learning a single model can enhance the low-resource translation by leveraging data from multiple languages. However, the performance of an MNMT model is highly dependent on the type of languages used in training, as transferring knowledge from a diverse set of languages degrades the translation performance due to negative transfer. In this paper, we propose a Hierarchical Knowledge Distillation (HKD) approach for MNMT which capitalises on language groups generated according to typological features and phylogeny of languages to overcome the issue of negative transfer. HKD generates a set of multilingual teacher-assistant models via a selective knowledge distillation mechanism based on the language groups, and then distils the ultimate multilingual model from those assistants in an adaptive way. Experimental results derived from the TED dataset with 53 languages demonstrate the effectiveness of our approach in avoiding the negative transfer effect in MNMT, leading to an improved translation performance (about 1 BLEU score on average) compared to strong baselines.
The Neglected Sibling: Isotropic Gaussian Posterior for VAE
Oct 14, 2021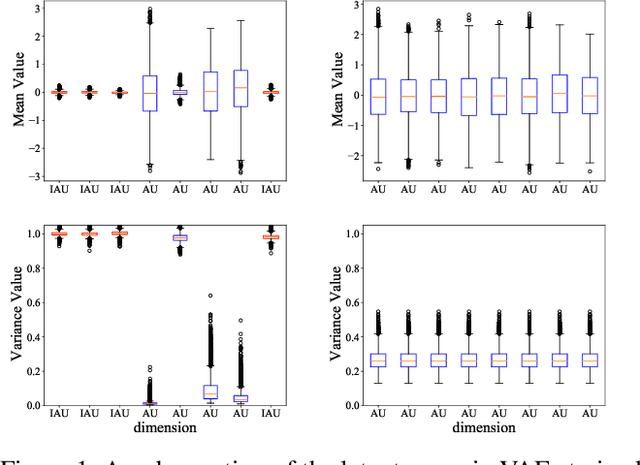
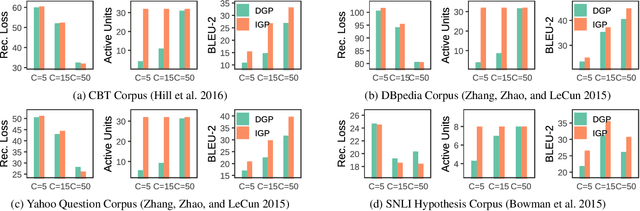
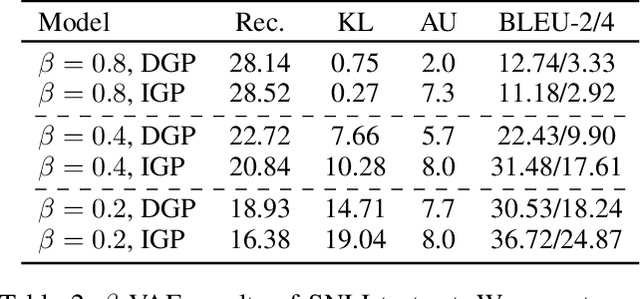
Deep generative models have been widely used in several areas of NLP, and various techniques have been proposed to augment them or address their training challenges. In this paper, we propose a simple modification to Variational Autoencoders (VAEs) by using an Isotropic Gaussian Posterior (IGP) that allows for better utilisation of their latent representation space. This model avoids the sub-optimal behavior of VAEs related to inactive dimensions in the representation space. We provide both theoretical analysis, and empirical evidence on various datasets and tasks that show IGP leads to consistent improvement on several quantitative and qualitative grounds, from downstream task performance and sample efficiency to robustness. Additionally, we give insights about the representational properties encouraged by IGP and also show that its gain generalises to image domain as well.
Neural Attention-Aware Hierarchical Topic Model
Oct 14, 2021
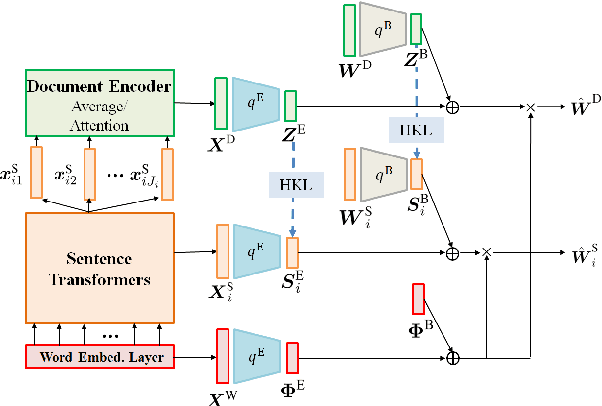
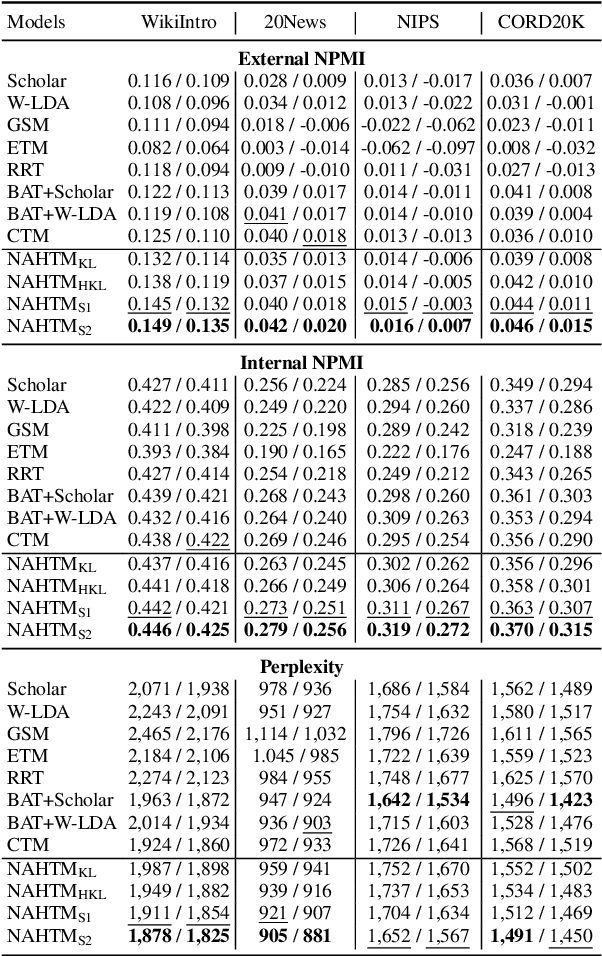
Neural topic models (NTMs) apply deep neural networks to topic modelling. Despite their success, NTMs generally ignore two important aspects: (1) only document-level word count information is utilized for the training, while more fine-grained sentence-level information is ignored, and (2) external semantic knowledge regarding documents, sentences and words are not exploited for the training. To address these issues, we propose a variational autoencoder (VAE) NTM model that jointly reconstructs the sentence and document word counts using combinations of bag-of-words (BoW) topical embeddings and pre-trained semantic embeddings. The pre-trained embeddings are first transformed into a common latent topical space to align their semantics with the BoW embeddings. Our model also features hierarchical KL divergence to leverage embeddings of each document to regularize those of their sentences, thereby paying more attention to semantically relevant sentences. Both quantitative and qualitative experiments have shown the efficacy of our model in 1) lowering the reconstruction errors at both the sentence and document levels, and 2) discovering more coherent topics from real-world datasets.
Transformer over Pre-trained Transformer for Neural Text Segmentation with Enhanced Topic Coherence
Oct 14, 2021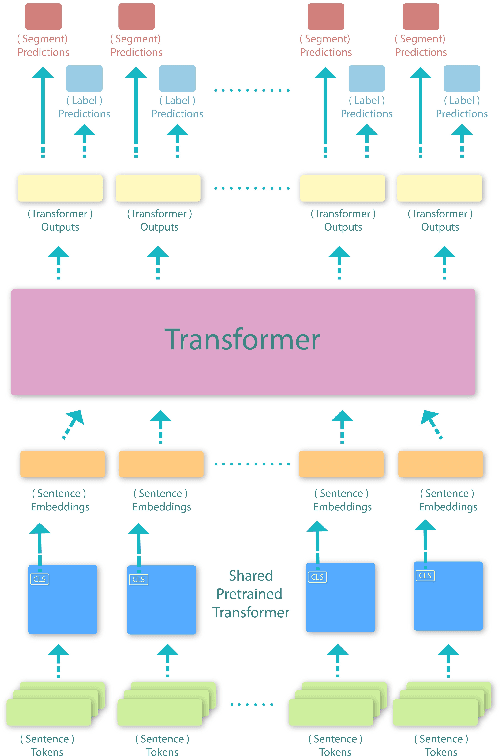


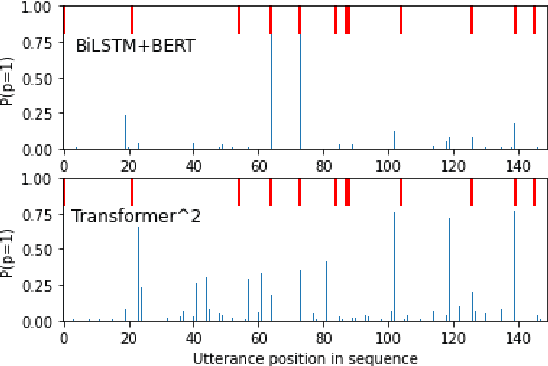
This paper proposes a transformer over transformer framework, called Transformer$^2$, to perform neural text segmentation. It consists of two components: bottom-level sentence encoders using pre-trained transformers, and an upper-level transformer-based segmentation model based on the sentence embeddings. The bottom-level component transfers the pre-trained knowledge learned from large external corpora under both single and pair-wise supervised NLP tasks to model the sentence embeddings for the documents. Given the sentence embeddings, the upper-level transformer is trained to recover the segmentation boundaries as well as the topic labels of each sentence. Equipped with a multi-task loss and the pre-trained knowledge, Transformer$^2$ can better capture the semantic coherence within the same segments. Our experiments show that (1) Transformer$^2$ manages to surpass state-of-the-art text segmentation models in terms of a commonly-used semantic coherence measure; (2) in most cases, both single and pair-wise pre-trained knowledge contribute to the model performance; (3) bottom-level sentence encoders pre-trained on specific languages yield better performance than those pre-trained on specific domains.
All Labels Are Not Created Equal: Enhancing Semi-supervision via Label Grouping and Co-training
Apr 12, 2021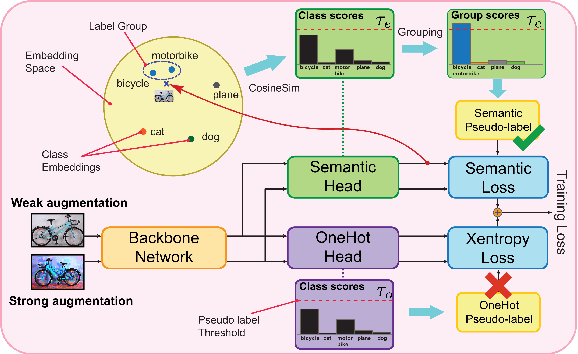
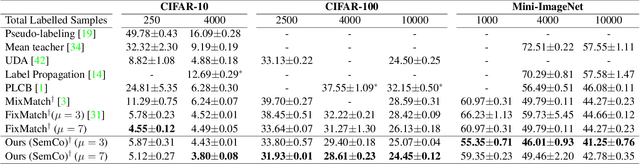
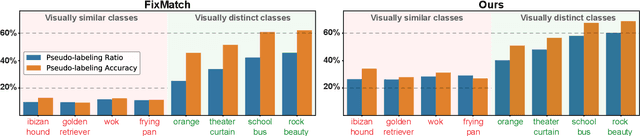
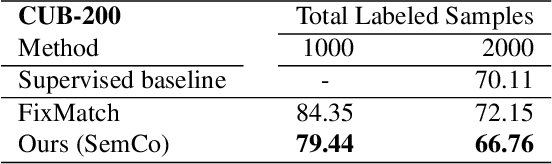
Pseudo-labeling is a key component in semi-supervised learning (SSL). It relies on iteratively using the model to generate artificial labels for the unlabeled data to train against. A common property among its various methods is that they only rely on the model's prediction to make labeling decisions without considering any prior knowledge about the visual similarity among the classes. In this paper, we demonstrate that this degrades the quality of pseudo-labeling as it poorly represents visually similar classes in the pool of pseudo-labeled data. We propose SemCo, a method which leverages label semantics and co-training to address this problem. We train two classifiers with two different views of the class labels: one classifier uses the one-hot view of the labels and disregards any potential similarity among the classes, while the other uses a distributed view of the labels and groups potentially similar classes together. We then co-train the two classifiers to learn based on their disagreements. We show that our method achieves state-of-the-art performance across various SSL tasks including 5.6% accuracy improvement on Mini-ImageNet dataset with 1000 labeled examples. We also show that our method requires smaller batch size and fewer training iterations to reach its best performance. We make our code available at https://github.com/islam-nassar/semco.
Topic Modelling Meets Deep Neural Networks: A Survey
Feb 28, 2021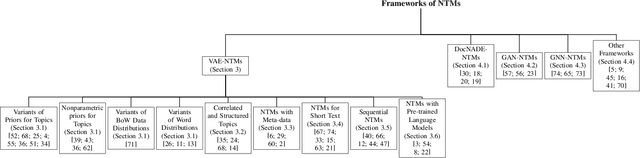
Topic modelling has been a successful technique for text analysis for almost twenty years. When topic modelling met deep neural networks, there emerged a new and increasingly popular research area, neural topic models, with over a hundred models developed and a wide range of applications in neural language understanding such as text generation, summarisation and language models. There is a need to summarise research developments and discuss open problems and future directions. In this paper, we provide a focused yet comprehensive overview of neural topic models for interested researchers in the AI community, so as to facilitate them to navigate and innovate in this fast-growing research area. To the best of our knowledge, ours is the first review focusing on this specific topic.
SQAPlanner: Generating Data-InformedSoftware Quality Improvement Plans
Feb 19, 2021
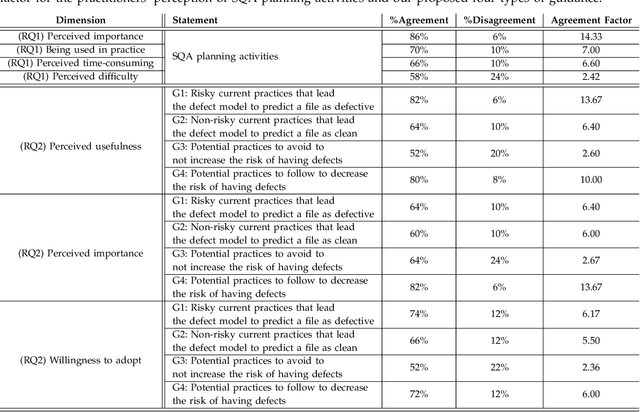
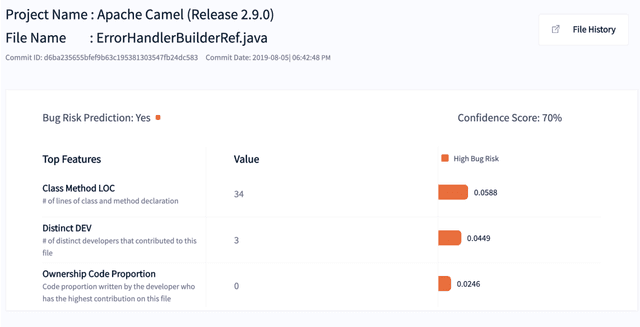
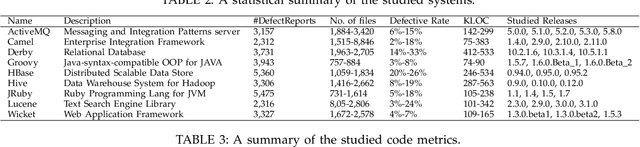
Software Quality Assurance (SQA) planning aims to define proactive plans, such as defining maximum file size, to prevent the occurrence of software defects in future releases. To aid this, defect prediction models have been proposed to generate insights as the most important factors that are associated with software quality. Such insights that are derived from traditional defect models are far from actionable-i.e., practitioners still do not know what they should do or avoid to decrease the risk of having defects, and what is the risk threshold for each metric. A lack of actionable guidance and risk threshold can lead to inefficient and ineffective SQA planning processes. In this paper, we investigate the practitioners' perceptions of current SQA planning activities, current challenges of such SQA planning activities, and propose four types of guidance to support SQA planning. We then propose and evaluate our AI-Driven SQAPlanner approach, a novel approach for generating four types of guidance and their associated risk thresholds in the form of rule-based explanations for the predictions of defect prediction models. Finally, we develop and evaluate an information visualization for our SQAPlanner approach. Through the use of qualitative survey and empirical evaluation, our results lead us to conclude that SQAPlanner is needed, effective, stable, and practically applicable. We also find that 80% of our survey respondents perceived that our visualization is more actionable. Thus, our SQAPlanner paves a way for novel research in actionable software analytics-i.e., generating actionable guidance on what should practitioners do and not do to decrease the risk of having defects to support SQA planning.
Temporal Cascade and Structural Modelling of EHRs for Granular Readmission Prediction
Feb 04, 2021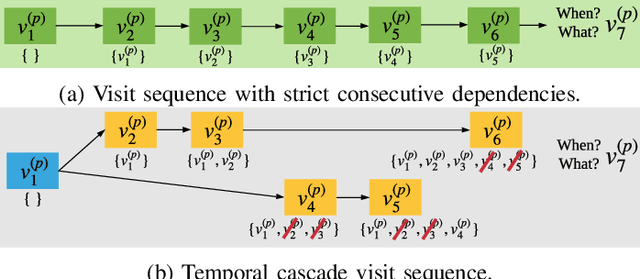
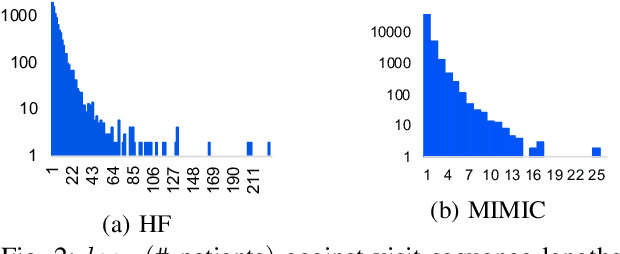
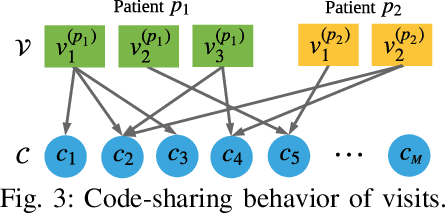
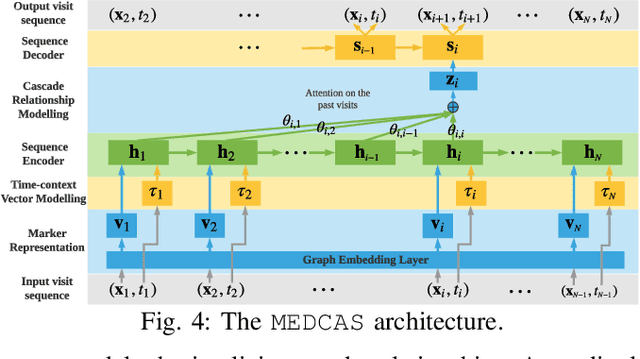
Predicting (1) when the next hospital admission occurs and (2) what will happen in the next admission about a patient by mining electronic health record (EHR) data can provide granular readmission predictions to assist clinical decision making. Recurrent neural network (RNN) and point process models are usually employed in modelling temporal sequential data. Simple RNN models assume that sequences of hospital visits follow strict causal dependencies between consecutive visits. However, in the real-world, a patient may have multiple co-existing chronic medical conditions, i.e., multimorbidity, which results in a cascade of visits where a non-immediate historical visit can be most influential to the next visit. Although a point process (e.g., Hawkes process) is able to model a cascade temporal relationship, it strongly relies on a prior generative process assumption. We propose a novel model, MEDCAS, to address these challenges. MEDCAS combines the strengths of RNN-based models and point processes by integrating point processes in modelling visit types and time gaps into an attention-based sequence-to-sequence learning model, which is able to capture the temporal cascade relationships. To supplement the patients with short visit sequences, a structural modelling technique with graph-based methods is used to construct the markers of the point process in MEDCAS. Extensive experiments on three real-world EHR datasets have been performed and the results demonstrate that \texttt{MEDCAS} outperforms state-of-the-art models in both tasks.
Discriminative, Generative and Self-Supervised Approaches for Target-Agnostic Learning
Nov 12, 2020
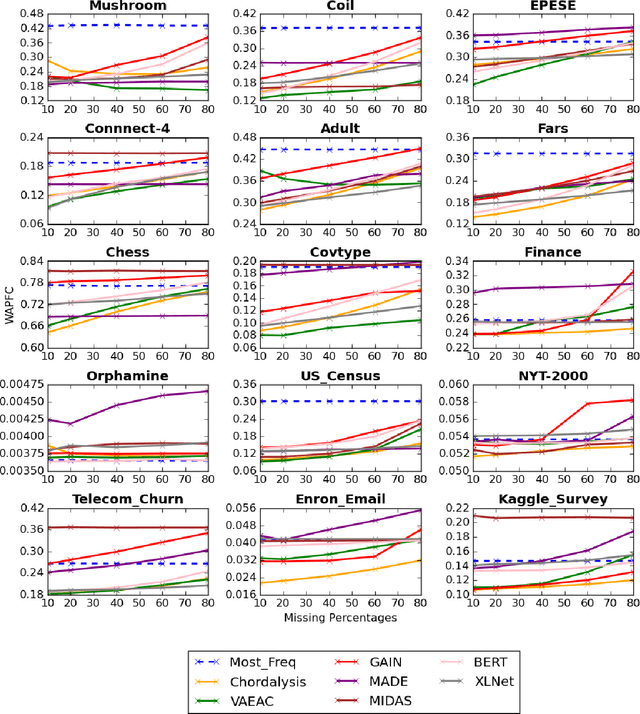
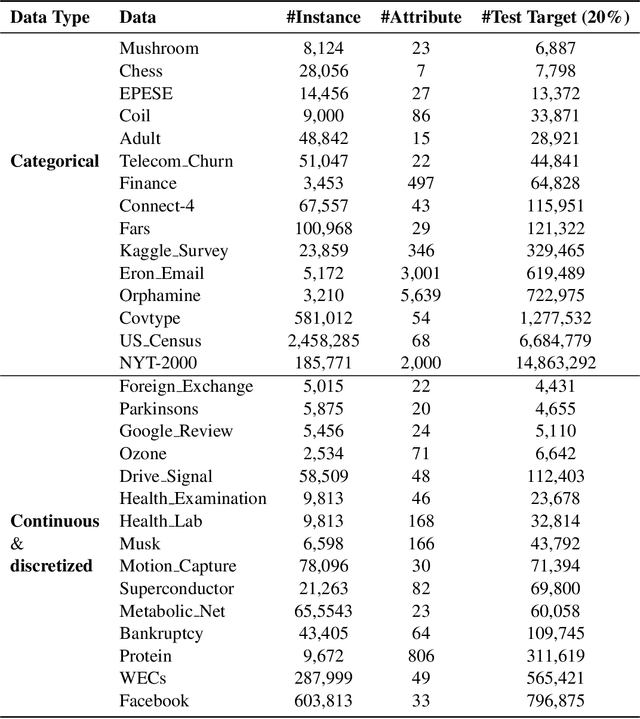
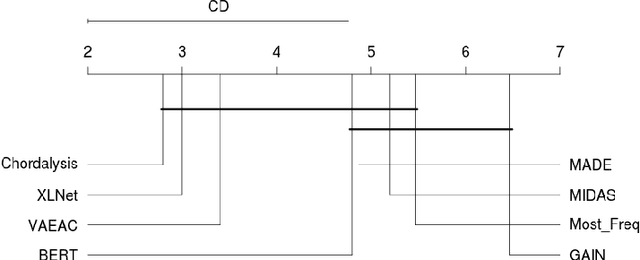
Supervised learning, characterized by both discriminative and generative learning, seeks to predict the values of single (or sometimes multiple) predefined target attributes based on a predefined set of predictor attributes. For applications where the information available and predictions to be made may vary from instance to instance, we propose the task of target-agnostic learning where arbitrary disjoint sets of attributes can be used for each of predictors and targets for each to-be-predicted instance. For this task, we survey a wide range of techniques available for handling missing values, self-supervised training and pseudo-likelihood training, and adapt them to a suite of algorithms that are suitable for the task. We conduct extensive experiments on this suite of algorithms on a large collection of categorical, continuous and discretized datasets, and report their performance in terms of both classification and regression errors. We also report the training and prediction time of these algorithms when handling large-scale datasets. Both generative and self-supervised learning models are shown to perform well at the task, although their characteristics towards the different types of data are quite different. Nevertheless, our derived theorem for the pseudo-likelihood theory also shows that they are related for inferring a joint distribution model based on the pseudo-likelihood training.
Collective Wisdom: Improving Low-resource Neural Machine Translation using Adaptive Knowledge Distillation
Oct 12, 2020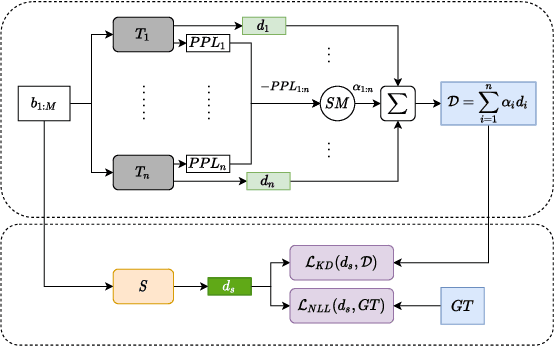
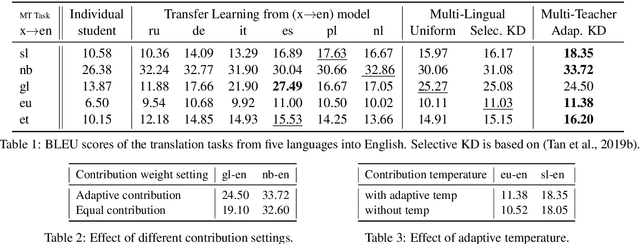
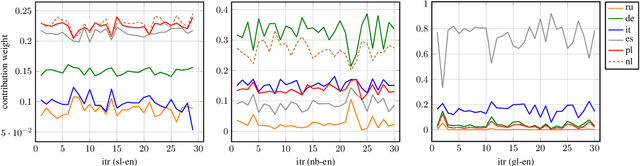
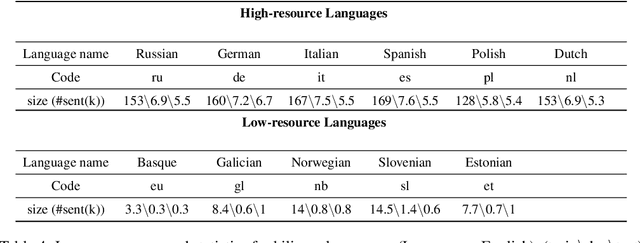
Scarcity of parallel sentence-pairs poses a significant hurdle for training high-quality Neural Machine Translation (NMT) models in bilingually low-resource scenarios. A standard approach is transfer learning, which involves taking a model trained on a high-resource language-pair and fine-tuning it on the data of the low-resource MT condition of interest. However, it is not clear generally which high-resource language-pair offers the best transfer learning for the target MT setting. Furthermore, different transferred models may have complementary semantic and/or syntactic strengths, hence using only one model may be sub-optimal. In this paper, we tackle this problem using knowledge distillation, where we propose to distill the knowledge of ensemble of teacher models to a single student model. As the quality of these teacher models varies, we propose an effective adaptive knowledge distillation approach to dynamically adjust the contribution of the teacher models during the distillation process. Experiments on transferring from a collection of six language pairs from IWSLT to five low-resource language-pairs from TED Talks demonstrate the effectiveness of our approach, achieving up to +0.9 BLEU score improvement compared to strong baselines.