 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCourteous Behavior of Automated Vehicles at Unsignalized Intersections via Reinforcement Learning
Jun 11, 2021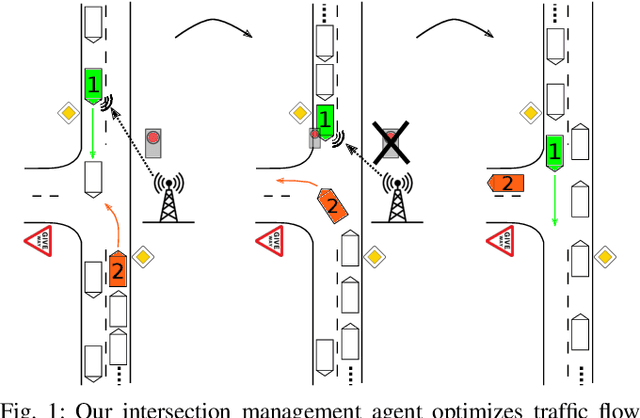
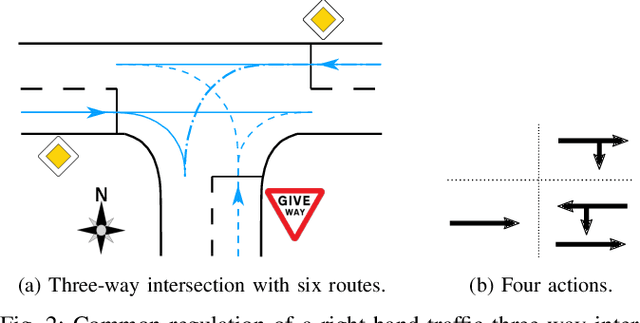
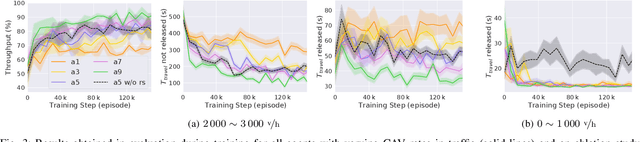
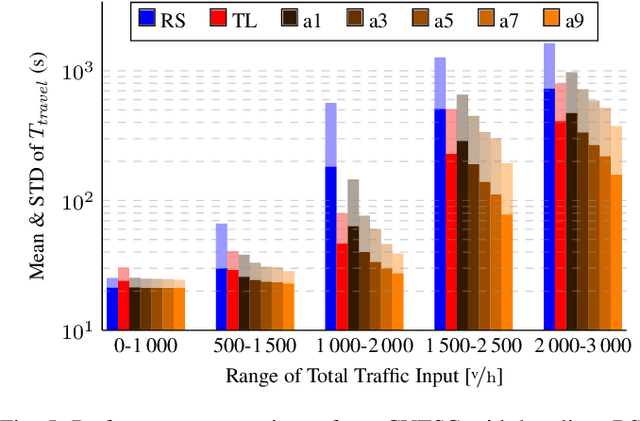
The transition from today's mostly human-driven traffic to a purely automated one will be a gradual evolution, with the effect that we will likely experience mixed traffic in the near future. Connected and automated vehicles can benefit human-driven ones and the whole traffic system in different ways, for example by improving collision avoidance and reducing traffic waves. Many studies have been carried out to improve intersection management, a significant bottleneck in traffic, with intelligent traffic signals or exclusively automated vehicles. However, the problem of how to improve mixed traffic at unsignalized intersections has received less attention. In this paper, we propose a novel approach to optimizing traffic flow at intersections in mixed traffic situations using deep reinforcement learning. Our reinforcement learning agent learns a policy for a centralized controller to let connected autonomous vehicles at unsignalized intersections give up their right of way and yield to other vehicles to optimize traffic flow. We implemented our approach and tested it in the traffic simulator SUMO based on simulated and real traffic data. The experimental evaluation demonstrates that our method significantly improves traffic flow through unsignalized intersections in mixed traffic settings and also provides better performance on a wide range of traffic situations compared to the state-of-the-art traffic signal controller for the corresponding signalized intersection.
Lane Graph Estimation for Scene Understanding in Urban Driving
May 01, 2021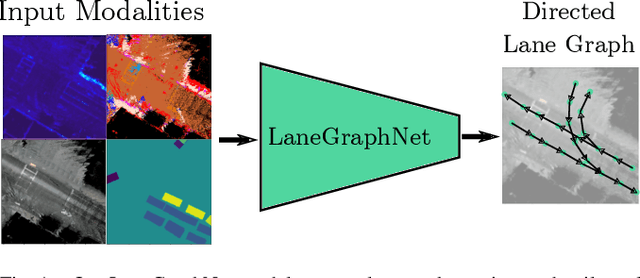
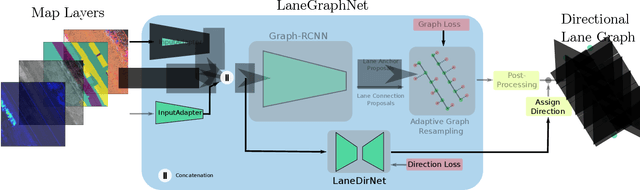


Lane-level scene annotations provide invaluable data in autonomous vehicles for trajectory planning in complex environments such as urban areas and cities. However, obtaining such data is time-consuming and expensive since lane annotations have to be annotated manually by humans and are as such hard to scale to large areas. In this work, we propose a novel approach for lane geometry estimation from bird's-eye-view images. We formulate the problem of lane shape and lane connections estimation as a graph estimation problem where lane anchor points are graph nodes and lane segments are graph edges. We train a graph estimation model on multimodal bird's-eye-view data processed from the popular NuScenes dataset and its map expansion pack. We furthermore estimate the direction of the lane connection for each lane segment with a separate model which results in a directed lane graph. We illustrate the performance of our LaneGraphNet model on the challenging NuScenes dataset and provide extensive qualitative and quantitative evaluation. Our model shows promising performance for most evaluated urban scenes and can serve as a step towards automated generation of HD lane annotations for autonomous driving.
Pre-training of Deep RL Agents for Improved Learning under Domain Randomization
Apr 29, 2021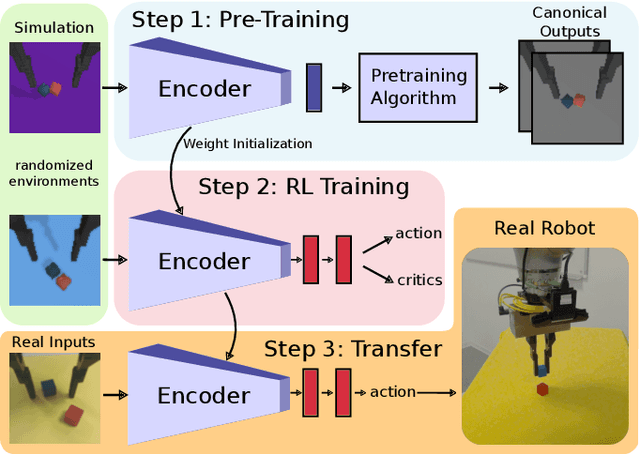

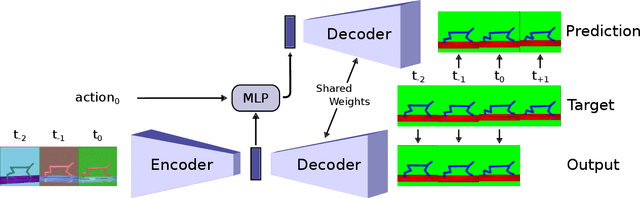
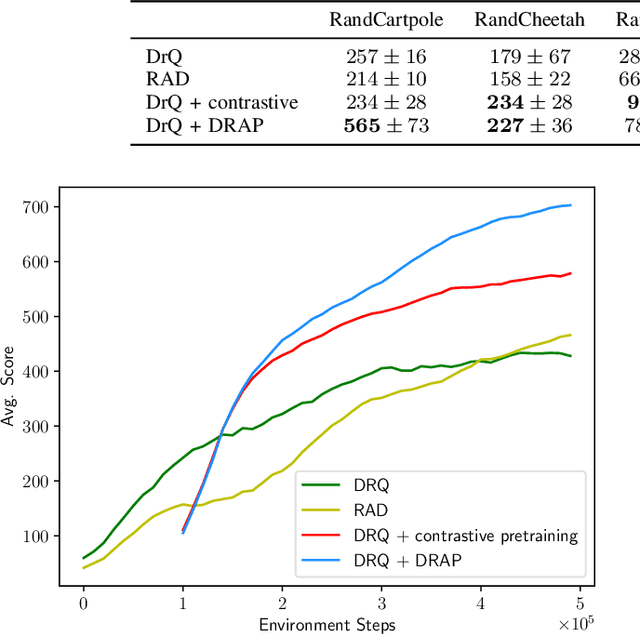
Visual domain randomization in simulated environments is a widely used method to transfer policies trained in simulation to real robots. However, domain randomization and augmentation hamper the training of a policy. As reinforcement learning struggles with a noisy training signal, this additional nuisance can drastically impede training. For difficult tasks it can even result in complete failure to learn. To overcome this problem we propose to pre-train a perception encoder that already provides an embedding invariant to the randomization. We demonstrate that this yields consistently improved results on a randomized version of DeepMind control suite tasks and a stacking environment on arbitrary backgrounds with zero-shot transfer to a physical robot.
Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion
Mar 30, 2021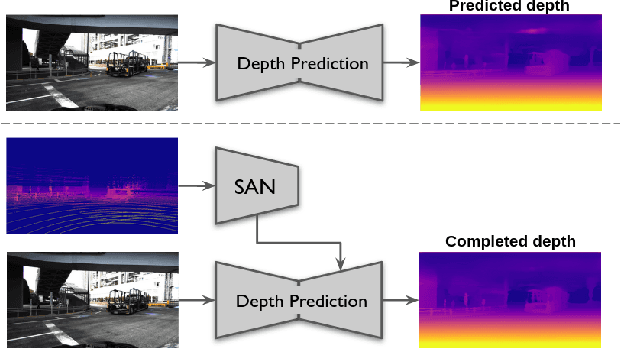
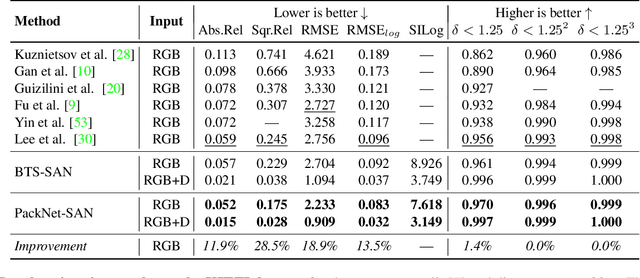
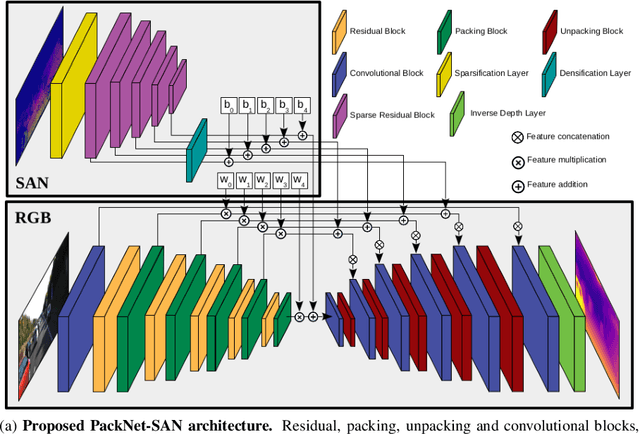
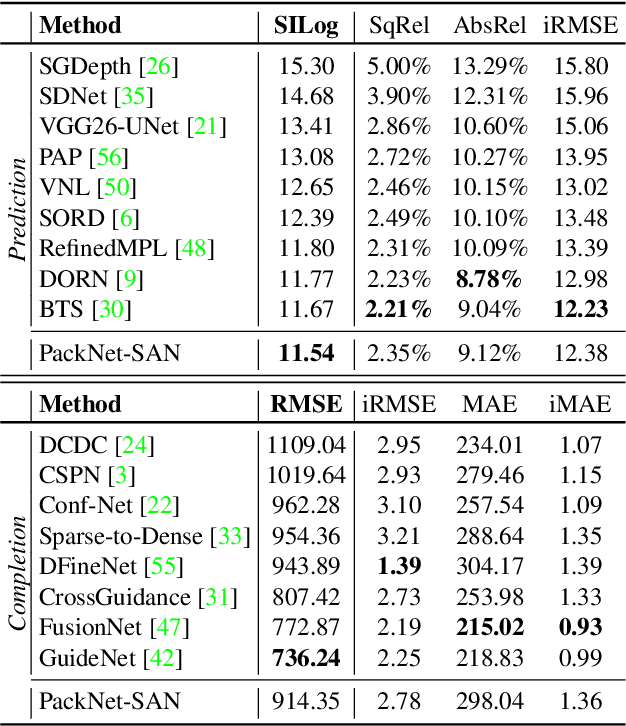
Estimating scene geometry from data obtained with cost-effective sensors is key for robots and self-driving cars. In this paper, we study the problem of predicting dense depth from a single RGB image (monodepth) with optional sparse measurements from low-cost active depth sensors. We introduce Sparse Auxiliary Networks (SANs), a new module enabling monodepth networks to perform both the tasks of depth prediction and completion, depending on whether only RGB images or also sparse point clouds are available at inference time. First, we decouple the image and depth map encoding stages using sparse convolutions to process only the valid depth map pixels. Second, we inject this information, when available, into the skip connections of the depth prediction network, augmenting its features. Through extensive experimental analysis on one indoor (NYUv2) and two outdoor (KITTI and DDAD) benchmarks, we demonstrate that our proposed SAN architecture is able to simultaneously learn both tasks, while achieving a new state of the art in depth prediction by a significant margin.
Learning to Track with Object Permanence
Mar 26, 2021

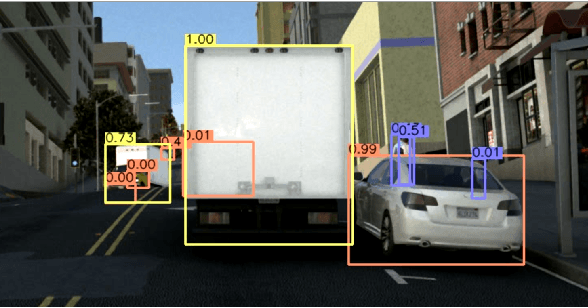
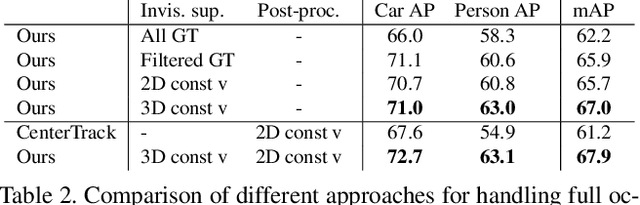
Tracking by detection, the dominant approach for online multi-object tracking, alternates between localization and re-identification steps. As a result, it strongly depends on the quality of instantaneous observations, often failing when objects are not fully visible. In contrast, tracking in humans is underlined by the notion of object permanence: once an object is recognized, we are aware of its physical existence and can approximately localize it even under full occlusions. In this work, we introduce an end-to-end trainable approach for joint object detection and tracking that is capable of such reasoning. We build on top of the recent CenterTrack architecture, which takes pairs of frames as input, and extend it to videos of arbitrary length. To this end, we augment the model with a spatio-temporal, recurrent memory module, allowing it to reason about object locations and identities in the current frame using all the previous history. It is, however, not obvious how to train such an approach. We study this question on a new, large-scale, synthetic dataset for multi-object tracking, which provides ground truth annotations for invisible objects, and propose several approaches for supervising tracking behind occlusions. Our model, trained jointly on synthetic and real data, outperforms the state of the art on KITTI, and MOT17 datasets thanks to its robustness to occlusions.
EfficientLPS: Efficient LiDAR Panoptic Segmentation
Mar 02, 2021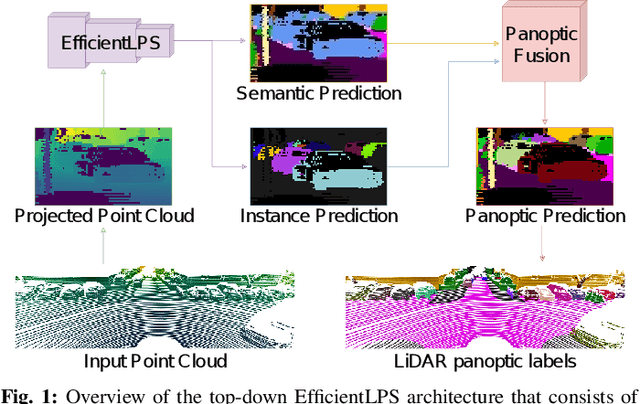

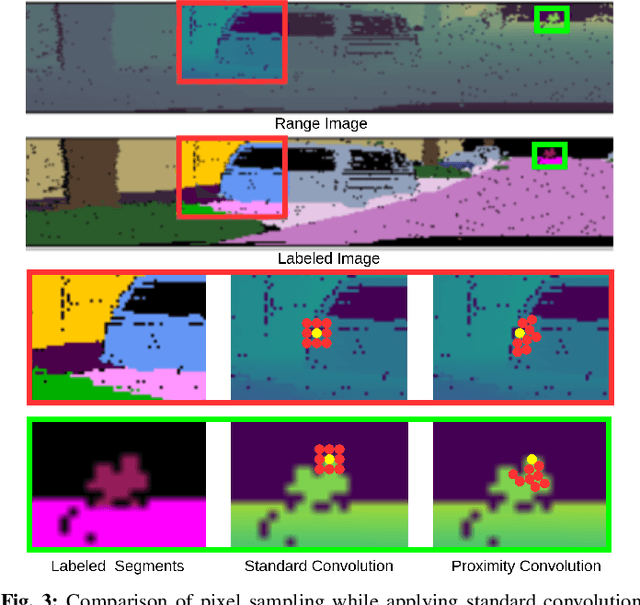
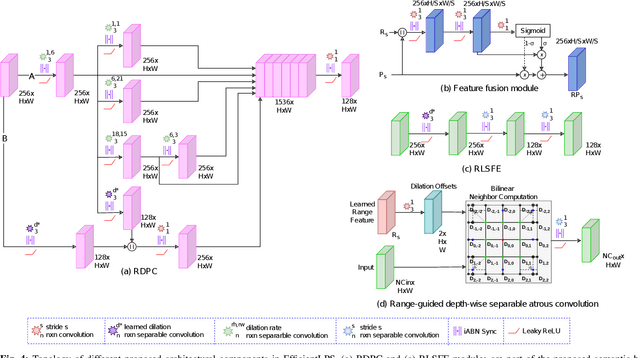
Panoptic segmentation of point clouds is a crucial task that enables autonomous vehicles to comprehend their vicinity using their highly accurate and reliable LiDAR sensors. Existing top-down approaches tackle this problem by either combining independent task-specific networks or translating methods from the image domain ignoring the intricacies of LiDAR data and thus often resulting in sub-optimal performance. In this paper, we present the novel top-down Efficient LiDAR Panoptic Segmentation (EfficientLPS) architecture that addresses multiple challenges in segmenting LiDAR point clouds including distance-dependent sparsity, severe occlusions, large scale-variations, and re-projection errors. EfficientLPS comprises of a novel shared backbone that encodes with strengthened geometric transformation modeling capacity and aggregates semantically rich range-aware multi-scale features. It incorporates new scale-invariant semantic and instance segmentation heads along with the panoptic fusion module which is supervised by our proposed panoptic periphery loss function. Additionally, we formulate a regularized pseudo labeling framework to further improve the performance of EfficientLPS by training on unlabelled data. We benchmark our proposed model on two large-scale LiDAR datasets: nuScenes, for which we also provide ground truth annotations, and SemanticKITTI. Notably, EfficientLPS sets the new state-of-the-art on both these datasets.
Composing Pick-and-Place Tasks By Grounding Language
Feb 16, 2021
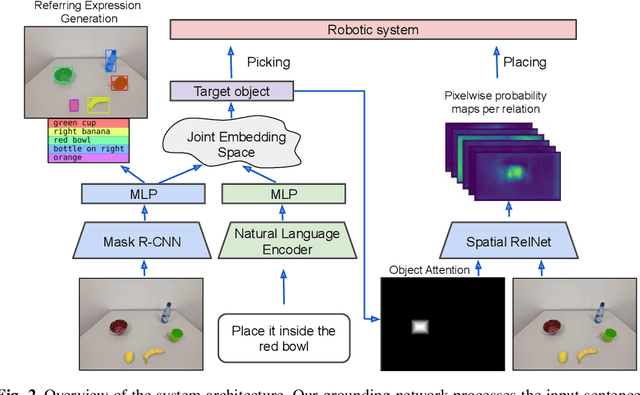
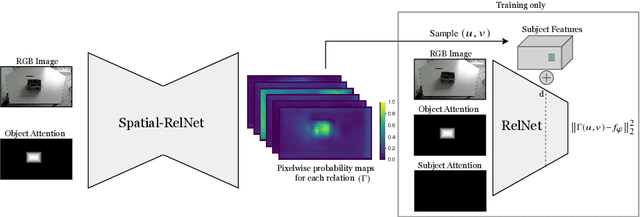
Controlling robots to perform tasks via natural language is one of the most challenging topics in human-robot interaction. In this work, we present a robot system that follows unconstrained language instructions to pick and place arbitrary objects and effectively resolves ambiguities through dialogues. Our approach infers objects and their relationships from input images and language expressions and can place objects in accordance with the spatial relations expressed by the user. Unlike previous approaches, we consider grounding not only for the picking but also for the placement of everyday objects from language. Specifically, by grounding objects and their spatial relations, we allow specification of complex placement instructions, e.g. "place it behind the middle red bowl". Our results obtained using a real-world PR2 robot demonstrate the effectiveness of our method in understanding pick-and-place language instructions and sequentially composing them to solve tabletop manipulation tasks. Videos are available at http://speechrobot.cs.uni-freiburg.de
Modality-Buffet for Real-Time Object Detection
Nov 17, 2020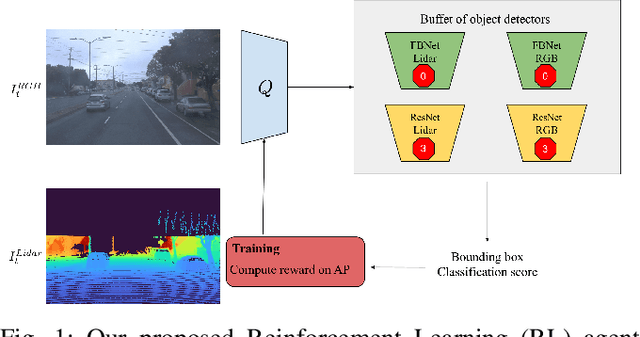
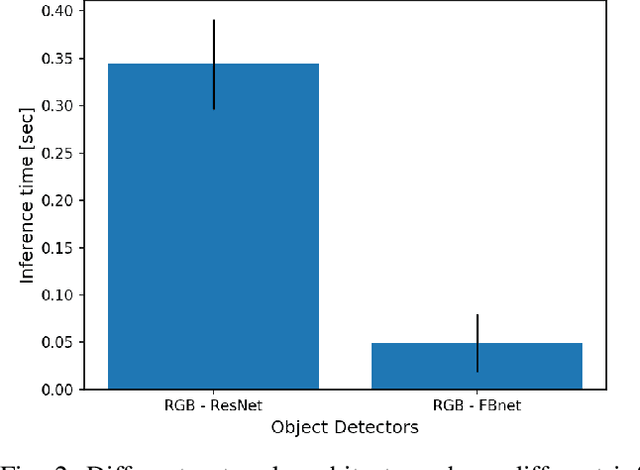
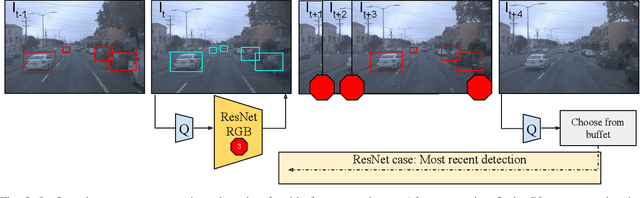
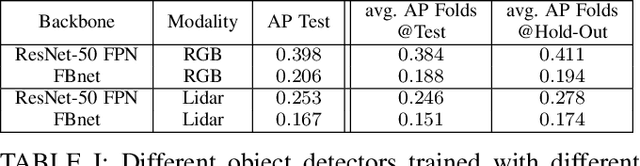
Real-time object detection in videos using lightweight hardware is a crucial component of many robotic tasks. Detectors using different modalities and with varying computational complexities offer different trade-offs. One option is to have a very lightweight model that can predict from all modalities at once for each frame. However, in some situations (e.g., in static scenes) it might be better to have a more complex but more accurate model and to extrapolate from previous predictions for the frames coming in at processing time. We formulate this task as a sequential decision making problem and use reinforcement learning (RL) to generate a policy that decides from the RGB input which detector out of a portfolio of different object detectors to take for the next prediction. The objective of the RL agent is to maximize the accuracy of the predictions per image. We evaluate the approach on the Waymo Open Dataset and show that it exceeds the performance of each single detector.
An Efficient Real-Time NMPC for Quadrotor Position Control under Communication Time-Delay
Oct 23, 2020
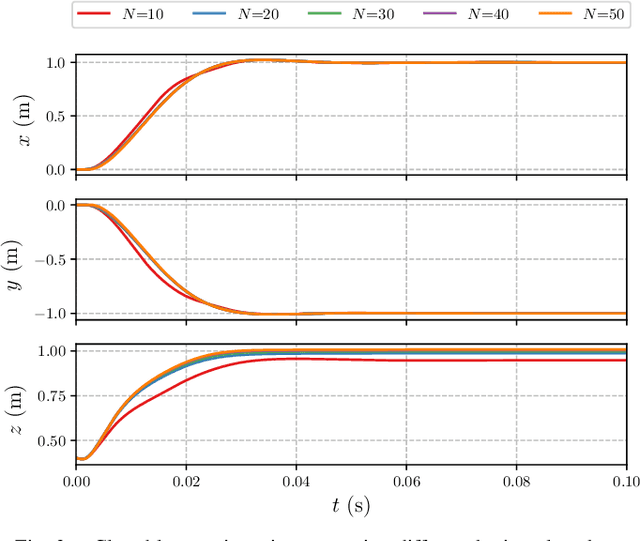
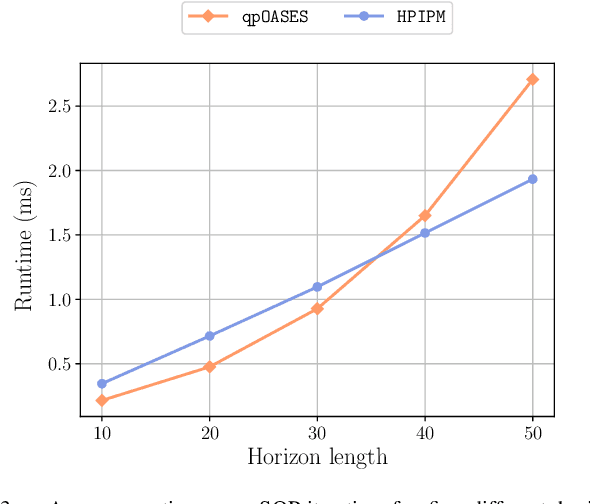
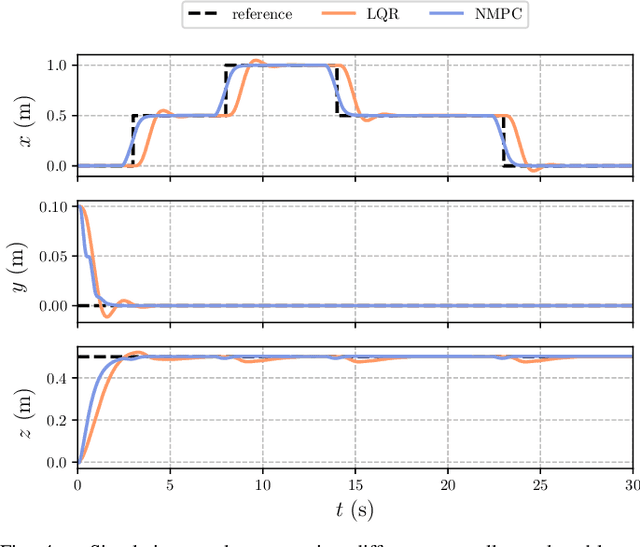
The advances in computer processor technology have enabled the application of nonlinear model predictive control (NMPC) to agile systems, such as quadrotors. These systems are characterized by their underactuation, nonlinearities, bounded inputs, and time-delays. Classical control solutions fall short in overcoming these difficulties and fully exploiting the capabilities offered by such platforms. This paper presents the design and implementation of an efficient position controller for quadrotors based on real-time NMPC with time-delay compensation and bounds enforcement on the actuators. To deal with the limited computational resources onboard, an offboard control architecture is proposed. It is implemented using the high-performance software package acados, which solves optimal control problems and implements a real-time iteration (RTI) variant of a sequential quadratic programming (SQP) scheme with Gauss-Newton Hessian approximation. The quadratic subproblems (QP) in the SQP scheme are solved with HPIPM, an interior-point method solver, built on top of the linear algebra library BLASFEO, finely tuned for multiple CPU architectures. Solution times are further reduced by reformulating the QPs using the efficient partial condensing algorithm implemented in HPIPM. We demonstrate the capabilities of our architecture using the Crazyflie 2.1 nano-quadrotor.
Holistic Filter Pruning for Efficient Deep Neural Networks
Sep 17, 2020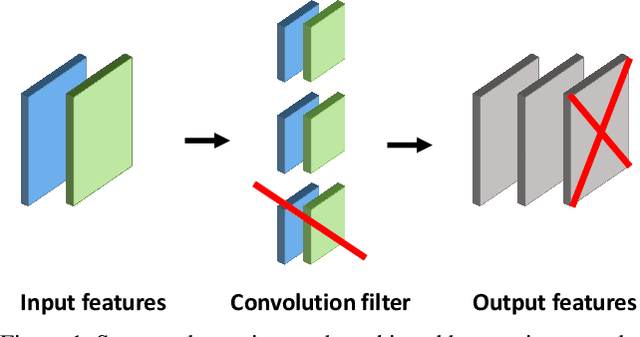
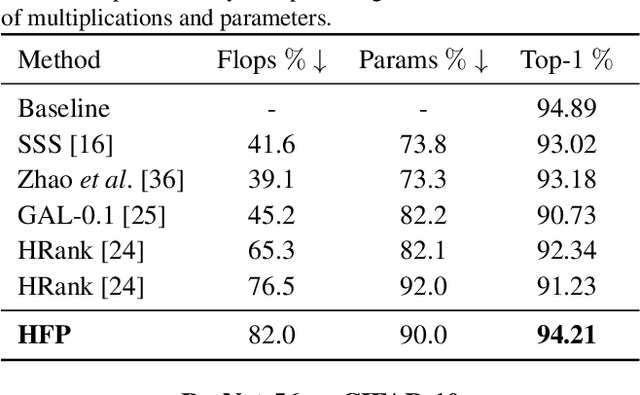
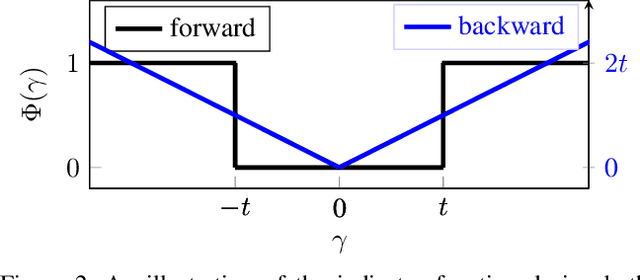
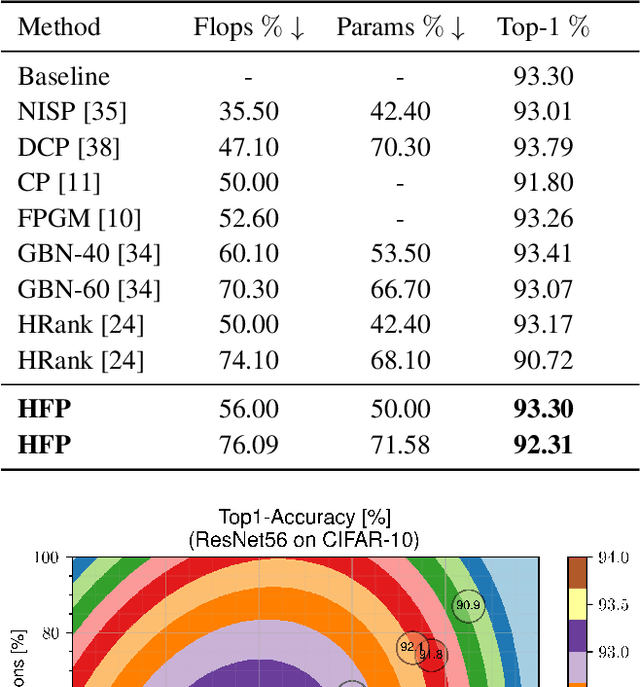
Deep neural networks (DNNs) are usually over-parameterized to increase the likelihood of getting adequate initial weights by random initialization. Consequently, trained DNNs have many redundancies which can be pruned from the model to reduce complexity and improve the ability to generalize. Structural sparsity, as achieved by filter pruning, directly reduces the tensor sizes of weights and activations and is thus particularly effective for reducing complexity. We propose "Holistic Filter Pruning" (HFP), a novel approach for common DNN training that is easy to implement and enables to specify accurate pruning rates for the number of both parameters and multiplications. After each forward pass, the current model complexity is calculated and compared to the desired target size. By gradient descent, a global solution can be found that allocates the pruning budget over the individual layers such that the desired target size is fulfilled. In various experiments, we give insights into the training and achieve state-of-the-art performance on CIFAR-10 and ImageNet (HFP prunes 60% of the multiplications of ResNet-50 on ImageNet with no significant loss in the accuracy). We believe our simple and powerful pruning approach to constitute a valuable contribution for users of DNNs in low-cost applications.