 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Differential Filters for Fast and Communication-Efficient Federated Learning
Apr 09, 2022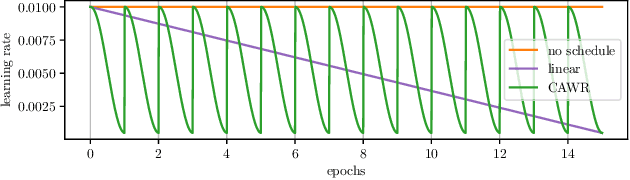
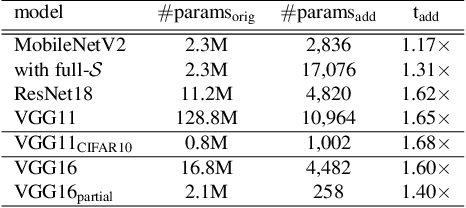
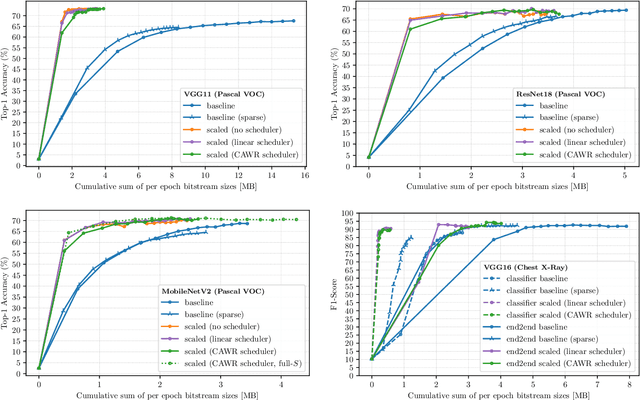
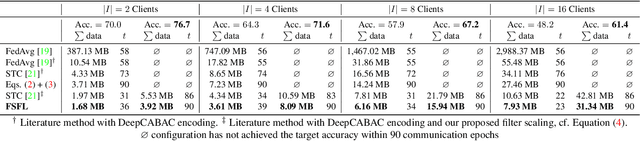
Federated learning (FL) scenarios inherently generate a large communication overhead by frequently transmitting neural network updates between clients and server. To minimize the communication cost, introducing sparsity in conjunction with differential updates is a commonly used technique. However, sparse model updates can slow down convergence speed or unintentionally skip certain update aspects, e.g., learned features, if error accumulation is not properly addressed. In this work, we propose a new scaling method operating at the granularity of convolutional filters which 1) compensates for highly sparse updates in FL processes, 2) adapts the local models to new data domains by enhancing some features in the filter space while diminishing others and 3) motivates extra sparsity in updates and thus achieves higher compression ratios, i.e., savings in the overall data transfer. Compared to unscaled updates and previous work, experimental results on different computer vision tasks (Pascal VOC, CIFAR10, Chest X-Ray) and neural networks (ResNets, MobileNets, VGGs) in uni-, bidirectional and partial update FL settings show that the proposed method improves the performance of the central server model while converging faster and reducing the total amount of transmitted data by up to 377 times.
Beyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement
Mar 15, 2022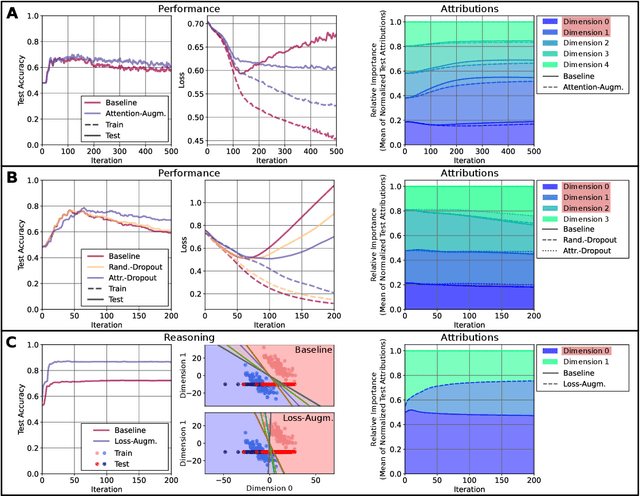
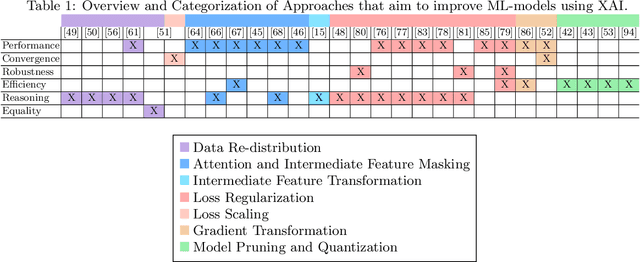
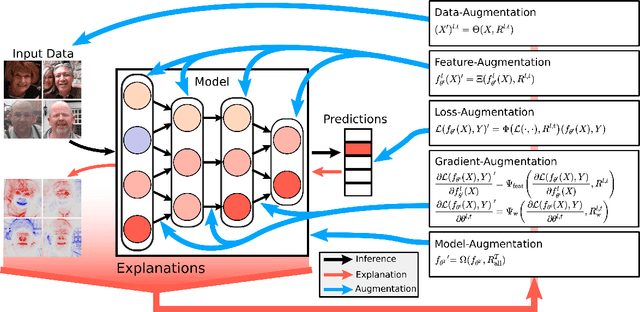
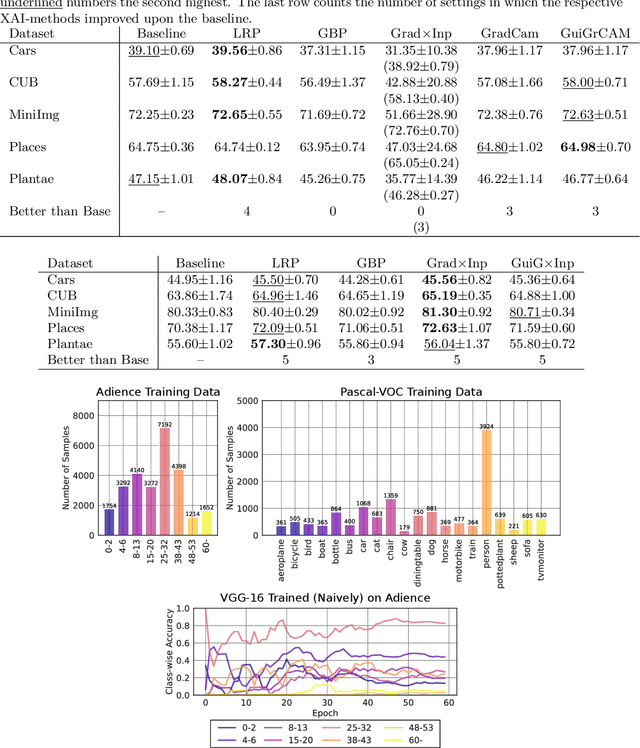
Explainable Artificial Intelligence (XAI) is an emerging research field bringing transparency to highly complex and opaque machine learning (ML) models. Despite the development of a multitude of methods to explain the decisions of black-box classifiers in recent years, these tools are seldomly used beyond visualization purposes. Only recently, researchers have started to employ explanations in practice to actually improve models. This paper offers a comprehensive overview over techniques that apply XAI practically for improving various properties of ML models, and systematically categorizes these approaches, comparing their respective strengths and weaknesses. We provide a theoretical perspective on these methods, and show empirically through experiments on toy and realistic settings how explanations can help improve properties such as model generalization ability or reasoning, among others. We further discuss potential caveats and drawbacks of these methods. We conclude that while model improvement based on XAI can have significant beneficial effects even on complex and not easily quantifyable model properties, these methods need to be applied carefully, since their success can vary depending on a multitude of factors, such as the model and dataset used, or the employed explanation method.
Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations
Feb 14, 2022
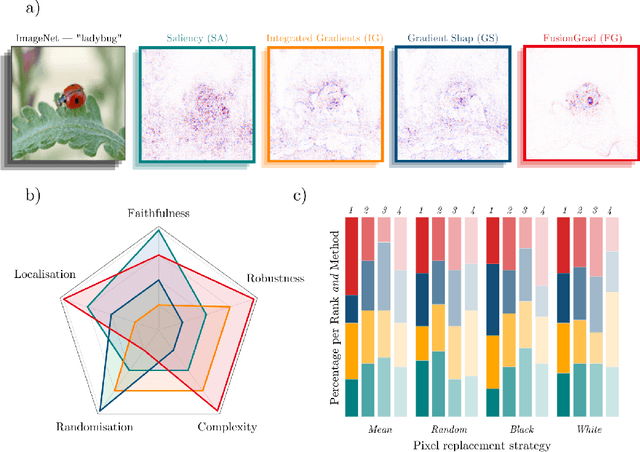
The evaluation of explanation methods is a research topic that has not yet been explored deeply, however, since explainability is supposed to strengthen trust in artificial intelligence, it is necessary to systematically review and compare explanation methods in order to confirm their correctness. Until now, no tool exists that exhaustively and speedily allows researchers to quantitatively evaluate explanations of neural network predictions. To increase transparency and reproducibility in the field, we therefore built Quantus - a comprehensive, open-source toolkit in Python that includes a growing, well-organised collection of evaluation metrics and tutorials for evaluating explainable methods. The toolkit has been thoroughly tested and is available under open source license on PyPi (or on https://github.com/understandable-machine-intelligence-lab/quantus/).
PatClArC: Using Pattern Concept Activation Vectors for Noise-Robust Model Debugging
Feb 07, 2022



State-of-the-art machine learning models are commonly (pre-)trained on large benchmark datasets. These often contain biases, artifacts, or errors that have remained unnoticed in the data collection process and therefore fail in representing the real world truthfully. This can cause models trained on these datasets to learn undesired behavior based upon spurious correlations, e.g., the existence of a copyright tag in an image. Concept Activation Vectors (CAV) have been proposed as a tool to model known concepts in latent space and have been used for concept sensitivity testing and model correction. Specifically, class artifact compensation (ClArC) corrects models using CAVs to represent data artifacts in feature space linearly. Modeling CAVs with filters of linear models, however, causes a significant influence of the noise portion within the data, as recent work proposes the unsuitability of linear model filters to find the signal direction in the input, which can be avoided by instead using patterns. In this paper we propose Pattern Concept Activation Vectors (PCAV) for noise-robust concept representations in latent space. We demonstrate that pattern-based artifact modeling has beneficial effects on the application of CAVs as a means to remove influence of confounding features from models via the ClArC framework.
Toward Explainable AI for Regression Models
Dec 21, 2021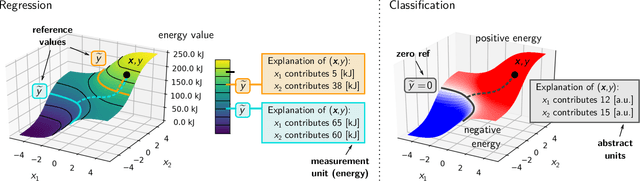
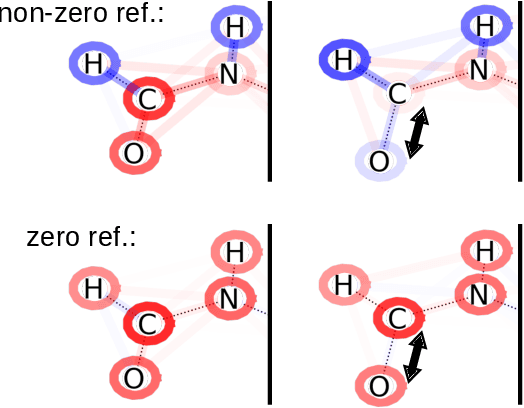
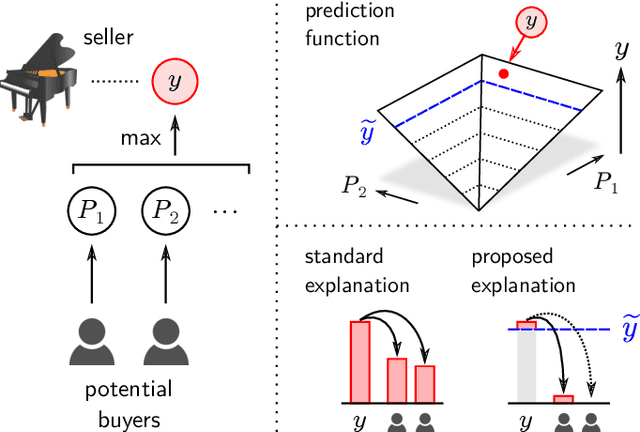
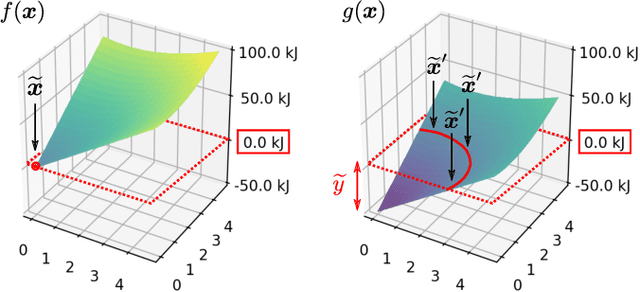
In addition to the impressive predictive power of machine learning (ML) models, more recently, explanation methods have emerged that enable an interpretation of complex non-linear learning models such as deep neural networks. Gaining a better understanding is especially important e.g. for safety-critical ML applications or medical diagnostics etc. While such Explainable AI (XAI) techniques have reached significant popularity for classifiers, so far little attention has been devoted to XAI for regression models (XAIR). In this review, we clarify the fundamental conceptual differences of XAI for regression and classification tasks, establish novel theoretical insights and analysis for XAIR, provide demonstrations of XAIR on genuine practical regression problems, and finally discuss the challenges remaining for the field.
Evaluating deep transfer learning for whole-brain cognitive decoding
Nov 01, 2021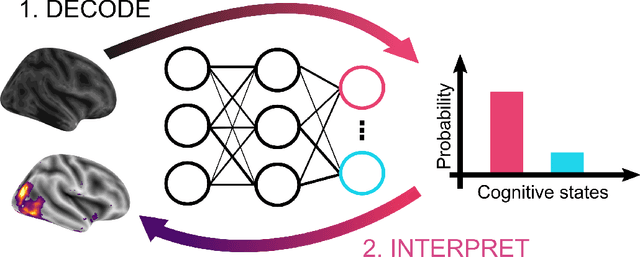
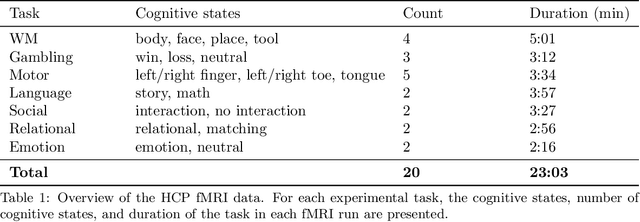

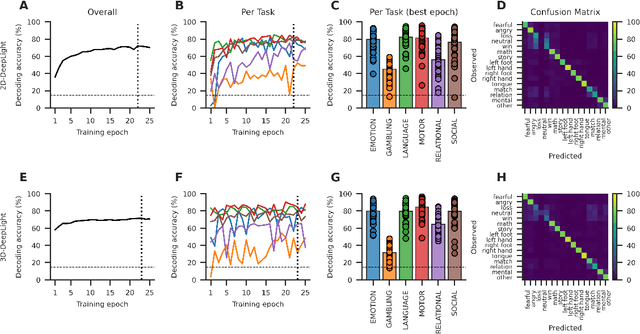
Research in many fields has shown that transfer learning (TL) is well-suited to improve the performance of deep learning (DL) models in datasets with small numbers of samples. This empirical success has triggered interest in the application of TL to cognitive decoding analyses with functional neuroimaging data. Here, we systematically evaluate TL for the application of DL models to the decoding of cognitive states (e.g., viewing images of faces or houses) from whole-brain functional Magnetic Resonance Imaging (fMRI) data. We first pre-train two DL architectures on a large, public fMRI dataset and subsequently evaluate their performance in an independent experimental task and a fully independent dataset. The pre-trained models consistently achieve higher decoding accuracies and generally require less training time and data than model variants that were not pre-trained, clearly underlining the benefits of pre-training. We demonstrate that these benefits arise from the ability of the pre-trained models to reuse many of their learned features when training with new data, providing deeper insights into the mechanisms giving rise to the benefits of pre-training. Yet, we also surface nuanced challenges for whole-brain cognitive decoding with DL models when interpreting the decoding decisions of the pre-trained models, as these have learned to utilize the fMRI data in unforeseen and counterintuitive ways to identify individual cognitive states.
ECQ$^{\text{x}}$: Explainability-Driven Quantization for Low-Bit and Sparse DNNs
Sep 09, 2021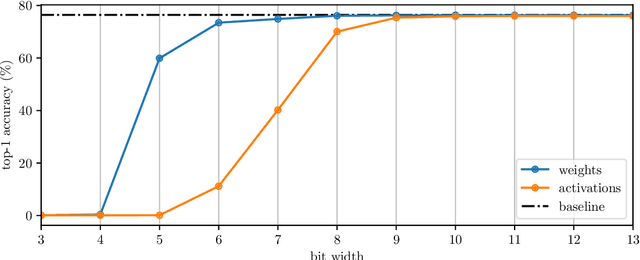
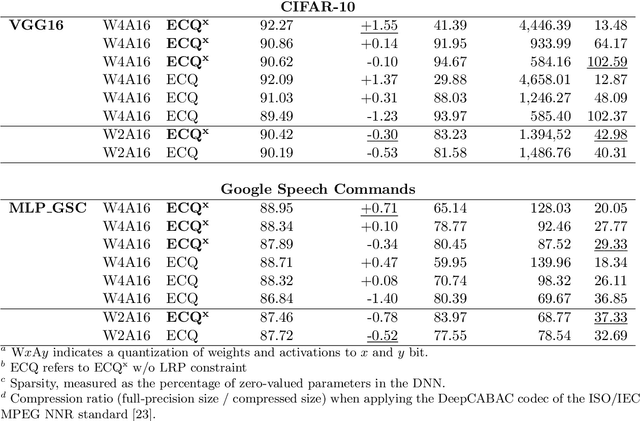
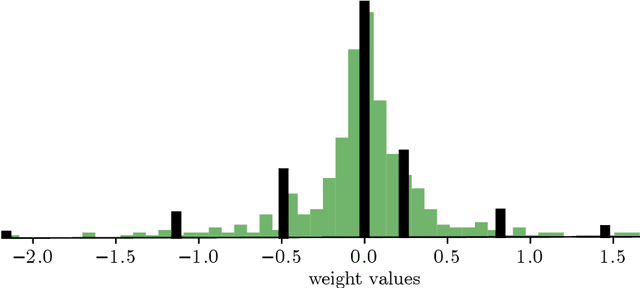
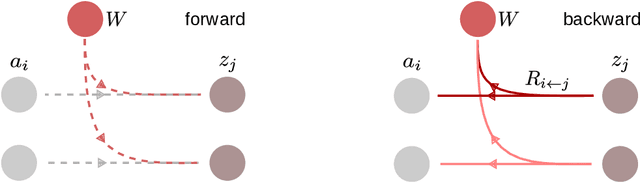
The remarkable success of deep neural networks (DNNs) in various applications is accompanied by a significant increase in network parameters and arithmetic operations. Such increases in memory and computational demands make deep learning prohibitive for resource-constrained hardware platforms such as mobile devices. Recent efforts aim to reduce these overheads, while preserving model performance as much as possible, and include parameter reduction techniques, parameter quantization, and lossless compression techniques. In this chapter, we develop and describe a novel quantization paradigm for DNNs: Our method leverages concepts of explainable AI (XAI) and concepts of information theory: Instead of assigning weight values based on their distances to the quantization clusters, the assignment function additionally considers weight relevances obtained from Layer-wise Relevance Propagation (LRP) and the information content of the clusters (entropy optimization). The ultimate goal is to preserve the most relevant weights in quantization clusters of highest information content. Experimental results show that this novel Entropy-Constrained and XAI-adjusted Quantization (ECQ$^{\text{x}}$) method generates ultra low-precision (2-5 bit) and simultaneously sparse neural networks while maintaining or even improving model performance. Due to reduced parameter precision and high number of zero-elements, the rendered networks are highly compressible in terms of file size, up to $103\times$ compared to the full-precision unquantized DNN model. Our approach was evaluated on different types of models and datasets (including Google Speech Commands and CIFAR-10) and compared with previous work.
Reward-Based 1-bit Compressed Federated Distillation on Blockchain
Jun 27, 2021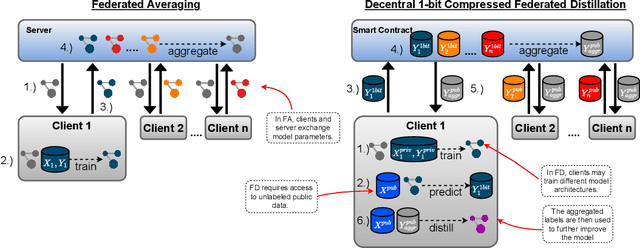
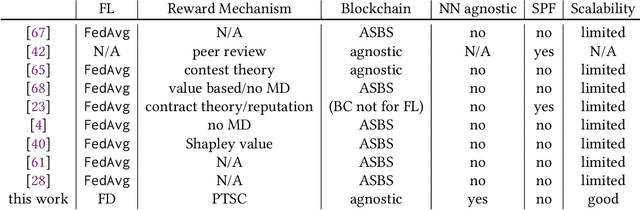

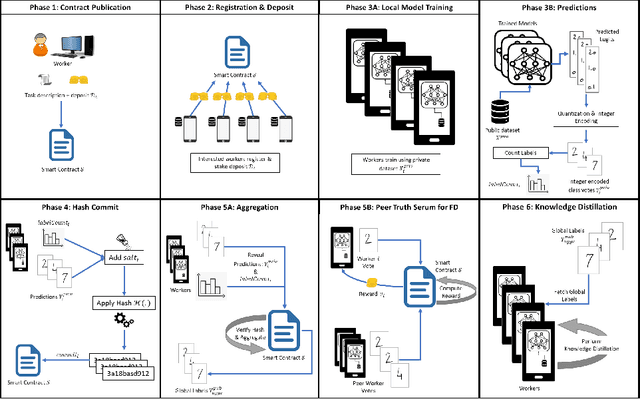
The recent advent of various forms of Federated Knowledge Distillation (FD) paves the way for a new generation of robust and communication-efficient Federated Learning (FL), where mere soft-labels are aggregated, rather than whole gradients of Deep Neural Networks (DNN) as done in previous FL schemes. This security-per-design approach in combination with increasingly performant Internet of Things (IoT) and mobile devices opens up a new realm of possibilities to utilize private data from industries as well as from individuals as input for artificial intelligence model training. Yet in previous FL systems, lack of trust due to the imbalance of power between workers and a central authority, the assumption of altruistic worker participation and the inability to correctly measure and compare contributions of workers hinder this technology from scaling beyond small groups of already entrusted entities towards mass adoption. This work aims to mitigate the aforementioned issues by introducing a novel decentralized federated learning framework where heavily compressed 1-bit soft-labels, resembling 1-hot label predictions, are aggregated on a smart contract. In a context where workers' contributions are now easily comparable, we modify the Peer Truth Serum for Crowdsourcing mechanism (PTSC) for FD to reward honest participation based on peer consistency in an incentive compatible fashion. Due to heavy reductions of both computational complexity and storage, our framework is a fully on-blockchain FL system that is feasible on simple smart contracts and therefore blockchain agnostic. We experimentally test our new framework and validate its theoretical properties.
On the Robustness of Pretraining and Self-Supervision for a Deep Learning-based Analysis of Diabetic Retinopathy
Jun 25, 2021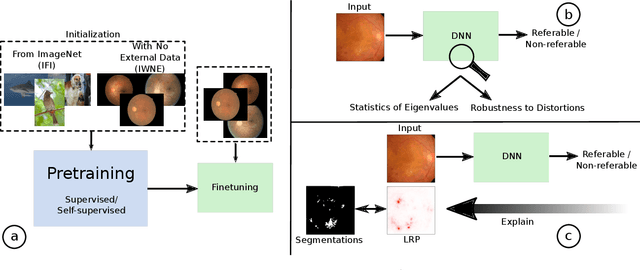

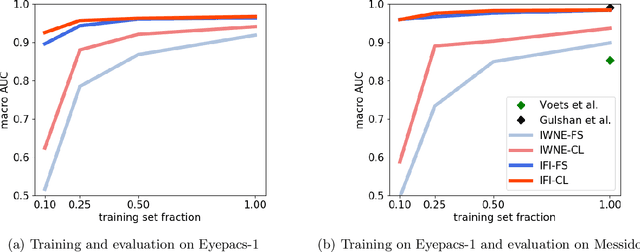
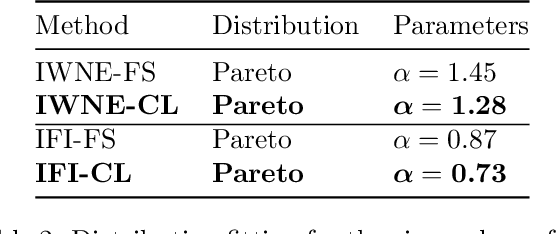
There is an increasing number of medical use-cases where classification algorithms based on deep neural networks reach performance levels that are competitive with human medical experts. To alleviate the challenges of small dataset sizes, these systems often rely on pretraining. In this work, we aim to assess the broader implications of these approaches. For diabetic retinopathy grading as exemplary use case, we compare the impact of different training procedures including recently established self-supervised pretraining methods based on contrastive learning. To this end, we investigate different aspects such as quantitative performance, statistics of the learned feature representations, interpretability and robustness to image distortions. Our results indicate that models initialized from ImageNet pretraining report a significant increase in performance, generalization and robustness to image distortions. In particular, self-supervised models show further benefits to supervised models. Self-supervised models with initialization from ImageNet pretraining not only report higher performance, they also reduce overfitting to large lesions along with improvements in taking into account minute lesions indicative of the progression of the disease. Understanding the effects of pretraining in a broader sense that goes beyond simple performance comparisons is of crucial importance for the broader medical imaging community beyond the use-case considered in this work.
Software for Dataset-wide XAI: From Local Explanations to Global Insights with Zennit, CoRelAy, and ViRelAy
Jun 24, 2021
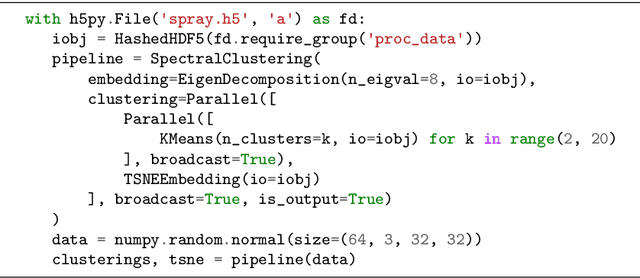
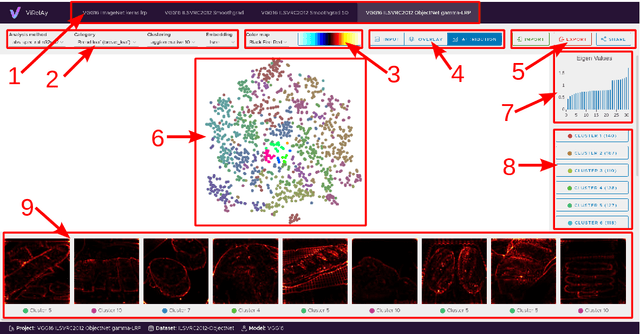
Deep Neural Networks (DNNs) are known to be strong predictors, but their prediction strategies can rarely be understood. With recent advances in Explainable Artificial Intelligence, approaches are available to explore the reasoning behind those complex models' predictions. One class of approaches are post-hoc attribution methods, among which Layer-wise Relevance Propagation (LRP) shows high performance. However, the attempt at understanding a DNN's reasoning often stops at the attributions obtained for individual samples in input space, leaving the potential for deeper quantitative analyses untouched. As a manual analysis without the right tools is often unnecessarily labor intensive, we introduce three software packages targeted at scientists to explore model reasoning using attribution approaches and beyond: (1) Zennit - a highly customizable and intuitive attribution framework implementing LRP and related approaches in PyTorch, (2) CoRelAy - a framework to easily and quickly construct quantitative analysis pipelines for dataset-wide analyses of explanations, and (3) ViRelAy - a web-application to interactively explore data, attributions, and analysis results.