 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visually Explaining Statistical Tests with Applications in Biomedical Imaging
Jan 20, 2026Deep neural two-sample tests have recently shown strong power for detecting distributional differences between groups, yet their black-box nature limits interpretability and practical adoption in biomedical analysis. Moreover, most existing post-hoc explainability methods rely on class labels, making them unsuitable for label-free statistical testing settings. We propose an explainable deep statistical testing framework that augments deep two-sample tests with sample-level and feature-level explanations, revealing which individual samples and which input features drive statistically significant group differences. Our method highlights which image regions and which individual samples contribute most to the detected group difference, providing spatial and instance-wise insight into the test's decision. Applied to biomedical imaging data, the proposed framework identifies influential samples and highlights anatomically meaningful regions associated with disease-related variation. This work bridges statistical inference and explainable AI, enabling interpretable, label-free population analysis in medical imaging.
Beyond Scalars: Concept-Based Alignment Analysis in Vision Transformers
Dec 09, 2024



Vision transformers (ViTs) can be trained using various learning paradigms, from fully supervised to self-supervised. Diverse training protocols often result in significantly different feature spaces, which are usually compared through alignment analysis. However, current alignment measures quantify this relationship in terms of a single scalar value, obscuring the distinctions between common and unique features in pairs of representations that share the same scalar alignment. We address this limitation by combining alignment analysis with concept discovery, which enables a breakdown of alignment into single concepts encoded in feature space. This fine-grained comparison reveals both universal and unique concepts across different representations, as well as the internal structure of concepts within each of them. Our methodological contributions address two key prerequisites for concept-based alignment: 1) For a description of the representation in terms of concepts that faithfully capture the geometry of the feature space, we define concepts as the most general structure they can possibly form - arbitrary manifolds, allowing hidden features to be described by their proximity to these manifolds. 2) To measure distances between concept proximity scores of two representations, we use a generalized Rand index and partition it for alignment between pairs of concepts. We confirm the superiority of our novel concept definition for alignment analysis over existing linear baselines in a sanity check. The concept-based alignment analysis of representations from four different ViTs reveals that increased supervision correlates with a reduction in the semantic structure of learned representations.
Quanda: An Interpretability Toolkit for Training Data Attribution Evaluation and Beyond
Oct 10, 2024

In recent years, training data attribution (TDA) methods have emerged as a promising direction for the interpretability of neural networks. While research around TDA is thriving, limited effort has been dedicated to the evaluation of attributions. Similar to the development of evaluation metrics for traditional feature attribution approaches, several standalone metrics have been proposed to evaluate the quality of TDA methods across various contexts. However, the lack of a unified framework that allows for systematic comparison limits trust in TDA methods and stunts their widespread adoption. To address this research gap, we introduce Quanda, a Python toolkit designed to facilitate the evaluation of TDA methods. Beyond offering a comprehensive set of evaluation metrics, Quanda provides a uniform interface for seamless integration with existing TDA implementations across different repositories, thus enabling systematic benchmarking. The toolkit is user-friendly, thoroughly tested, well-documented, and available as an open-source library on PyPi and under https://github.com/dilyabareeva/quanda.
Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression
Apr 15, 2024



Deep Neural Networks are prone to learning and relying on spurious correlations in the training data, which, for high-risk applications, can have fatal consequences. Various approaches to suppress model reliance on harmful features have been proposed that can be applied post-hoc without additional training. Whereas those methods can be applied with efficiency, they also tend to harm model performance by globally shifting the distribution of latent features. To mitigate unintended overcorrection of model behavior, we propose a reactive approach conditioned on model-derived knowledge and eXplainable Artificial Intelligence (XAI) insights. While the reactive approach can be applied to many post-hoc methods, we demonstrate the incorporation of reactivity in particular for P-ClArC (Projective Class Artifact Compensation), introducing a new method called R-ClArC (Reactive Class Artifact Compensation). Through rigorous experiments in controlled settings (FunnyBirds) and with a real-world dataset (ISIC2019), we show that introducing reactivity can minimize the detrimental effect of the applied correction while simultaneously ensuring low reliance on spurious features.
Manipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024



Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
Finding the right XAI method -- A Guide for the Evaluation and Ranking of Explainable AI Methods in Climate Science
Mar 01, 2023



Explainable artificial intelligence (XAI) methods shed light on the predictions of deep neural networks (DNNs). Several different approaches exist and have partly already been successfully applied in climate science. However, the often missing ground truth explanations complicate their evaluation and validation, subsequently compounding the choice of the XAI method. Therefore, in this work, we introduce XAI evaluation in the context of climate research and assess different desired explanation properties, namely, robustness, faithfulness, randomization, complexity, and localization. To this end we build upon previous work and train a multi-layer perceptron (MLP) and a convolutional neural network (CNN) to predict the decade based on annual-mean temperature maps. Next, multiple local XAI methods are applied and their performance is quantified for each evaluation property and compared against a baseline test. Independent of the network type, we find that the XAI methods Integrated Gradients, Layer-wise relevance propagation, and InputGradients exhibit considerable robustness, faithfulness, and complexity while sacrificing randomization. The opposite is true for Gradient, SmoothGrad, NoiseGrad, and FusionGrad. Notably, explanations using input perturbations, such as SmoothGrad and Integrated Gradients, do not improve robustness and faithfulness, contrary to previous claims. Overall, our experiments offer a comprehensive overview of different properties of explanation methods in the climate science context and supports users in the selection of a suitable XAI method.
Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations
Feb 14, 2022
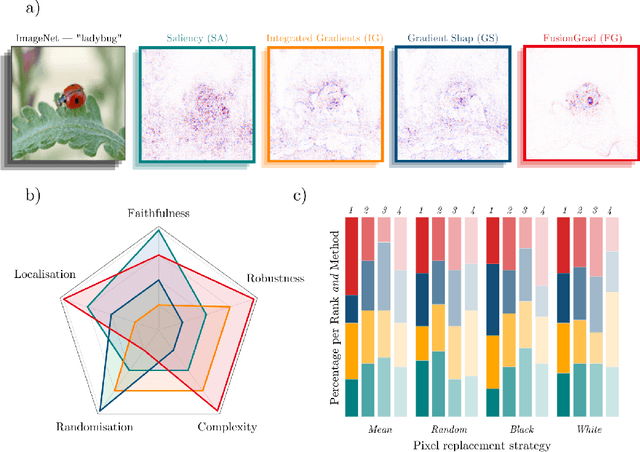
The evaluation of explanation methods is a research topic that has not yet been explored deeply, however, since explainability is supposed to strengthen trust in artificial intelligence, it is necessary to systematically review and compare explanation methods in order to confirm their correctness. Until now, no tool exists that exhaustively and speedily allows researchers to quantitatively evaluate explanations of neural network predictions. To increase transparency and reproducibility in the field, we therefore built Quantus - a comprehensive, open-source toolkit in Python that includes a growing, well-organised collection of evaluation metrics and tutorials for evaluating explainable methods. The toolkit has been thoroughly tested and is available under open source license on PyPi (or on https://github.com/understandable-machine-intelligence-lab/quantus/).