 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGSP:Implicit Gradient Subspace Projection for Efficient Continual Learning of Vision-Language Models
May 19, 2026Vision-Language Models require efficient adaptation to continually emerging downstream tasks. While Parameter-Efficient Fine-Tuning mitigates catastrophic forgetting, assigning isolated modules per task leads to parameter explosion. Conversely, recent similarity-driven sharing mechanisms falsely equate superficial visual similarity with underlying alignment consistency. This fundamental mismatch triggers severe negative transfer between visually similar but logically distinct tasks and fails to exploit alignment reuse across visually diverse ones. We argue thatalignment sharing is fundamentally a geometric problem of overlapping optimization trajectories within shared low-rank subspaces. Grounded in this insight, we propose iGSP, a novel framework that achieves efficient adaptation via implicit gradient subspace projection. Leveraging the early convergence of MoE routers to establish the subspace basis, iGSP bifurcates the adaptation process into two phases. First, the Subspace Identification phase introduces candidate experts via basis pre-expansion, applies a novel subspace-constrained regularization to implicitly project new task gradients onto the historical subspace, and precisely prunes redundant dimensions by treating routing probabilities as gradient flow indicators, ultimately to maximize knowledge reuse. Second, the Orthogonal Subspace Fine-Tuning phase fixes this structural basis and removes the regularization to rapidly fit the task-specific residual loss. Extensive experiments on the MTIL benchmark demonstrate that iGSP achieves state-of-the-art accuracy while significantly improving training efficiency, reducing the average trainable parameters by 42.7\% compared to current SOTA methods, and decreasing the final total parameters by 86.9\% relative to counterparts. The source code is available at https://github.com/GeoX-Lab/iGSP.
RS-Claw: Progressive Active Tool Exploration via Hierarchical Skill Trees for Remote Sensing Agents
May 13, 2026The rise of multi-modal large language models (MLLMs) is shifting remote sensing (RS) intelligence from "see" to "action", as OpenClaw-style frameworks enable agents to autonomously operate massive RS image-processing tools for complex tasks. Existing RS agents adopt a passive selection paradigm for tool invocation, relying on either full tool registration (Flat) or retrieval-augmented generation (RAG). However, in the massive and multi-source heterogeneous RS tool ecosystem, such passive mechanisms struggle to dynamically balance "context load" and "toolset completeness" throughout task reasoning, thus exhibiting inherent limitations: full tool registration triggers context space deficits during long-horizon tasks, whereas RAG retrieval may omit critical tools in essential steps. To overcome these bottlenecks, this paper redefines tool selection by arguing that the agent should act as an active explorer within the tool space. Based on this perspective, we propose RS-Claw, a novel RS agent architecture. By leveraging Skill encapsulation technology at the tool end, this architecture hierarchically structures tool descriptions, enabling the agent to execute on-demand sequential decision-making: initially selecting relevant skill branches by reading only tool summaries, then dynamically loading detailed descriptions, and ultimately achieving precise invocation. This active paradigm not only significantly liberates the agent's context space but also effectively ensures the accurate hit rate of critical tools during long-horizon reasoning. Systematic experiments on the Earth-Bench benchmark demonstrate that RS-Claw's active exploration mechanism effectively filters semantic noise and substantially frees up reasoning space, achieving an input token compression ratio of up to 86%, and comprehensively outperforming existing Flat and RAG baselines across complex reasoning evaluations.
SuperFace: Preference-Aligned Facial Expression Estimation Beyond Pseudo Supervision
May 07, 2026Accurate facial estimation is crucial for realistic digital human animation, and ARKit blendshape coefficients offer an interpretable representation by mapping facial motions to semantic animation controls. However, learning high-quality ARKit coefficient prediction remains limited by the absence of reliable ground-truth supervision. Existing methods typically rely on capture software such as Live Link Face to provide pseudo labels, which may contain noisy activations, biased coefficient magnitudes, and missing or inaccurate facial actions. Consequently, models trained with supervised learning tend to reproduce imperfect pseudo labels rather than optimize for perceptual expression fidelity. In this paper, we propose SuperFace, a preference-driven framework that moves ARKit facial expression estimation from pseudo-label imitation toward human-aligned perceptual optimization. Instead of treating software-estimated coefficients as fixed ground truth, SuperFace uses them only as an initialization and further improves coefficient prediction through human preference feedback on rendered facial expressions. By aligning the model with perceptual judgments rather than numerical pseudo labels, SuperFace enables more visually faithful and expressive facial animation. Experiments show that SuperFace improves expression fidelity over Live Link Face supervision, demonstrating the effectiveness of preference-driven optimization for semantic facial action prediction.
GeoAgentBench: A Dynamic Execution Benchmark for Tool-Augmented Agents in Spatial Analysis
Apr 15, 2026The integration of Large Language Models (LLMs) into Geographic Information Systems (GIS) marks a paradigm shift toward autonomous spatial analysis. However, evaluating these LLM-based agents remains challenging due to the complex, multi-step nature of geospatial workflows. Existing benchmarks primarily rely on static text or code matching, neglecting dynamic runtime feedback and the multimodal nature of spatial outputs. To address this gap, we introduce GeoAgentBench (GABench), a dynamic and interactive evaluation benchmark tailored for tool-augmented GIS agents. GABench provides a realistic execution sandbox integrating 117 atomic GIS tools, encompassing 53 typical spatial analysis tasks across 6 core GIS domains. Recognizing that precise parameter configuration is the primary determinant of execution success in dynamic GIS environments, we designed the Parameter Execution Accuracy (PEA) metric, which utilizes a "Last-Attempt Alignment" strategy to quantify the fidelity of implicit parameter inference. Complementing this, a Vision-Language Model (VLM) based verification is proposed to assess data-spatial accuracy and cartographic style adherence. Furthermore, to address the frequent task failures caused by parameter misalignments and runtime anomalies, we developed a novel agent architecture, Plan-and-React, that mimics expert cognitive workflows by decoupling global orchestration from step-wise reactive execution. Extensive experiments with seven representative LLMs demonstrate that the Plan-and-React paradigm significantly outperforms traditional frameworks, achieving the optimal balance between logical rigor and execution robustness, particularly in multi-step reasoning and error recovery. Our findings highlight current capability boundaries and establish a robust standard for assessing and advancing the next generation of autonomous GeoAI.
SemanticFace: Semantic Facial Action Estimation via Semantic Distillation in Interpretable Space
Mar 16, 2026Facial action estimation from a single image is often formulated as predicting or fitting parameters in compact expression spaces, which lack explicit semantic interpretability. However, many practical applications, such as avatar control and human-computer interaction, require interpretable facial actions that correspond to meaningful muscle movements. In this work, we propose \textbf{SemanticFace}, a framework for facial action estimation in the interpretable ARKit blendshape space that reformulates coefficient prediction as structured semantic reasoning. SemanticFace adopts a two-stage semantic distillation paradigm: it first derives structured semantic supervision from ground-truth ARKit coefficients and then distills this knowledge into a multimodal large language model to predict interpretable facial action coefficients from images. Extensive experiments demonstrate that language-aligned semantic supervision improves both coefficient accuracy and perceptual consistency, while enabling strong cross-identity generalization and robustness to large domain shifts, including cartoon faces.
DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
Jun 27, 2024



Current multimodal large language models (MLLMs) face significant challenges in visual document understanding (VDU) tasks due to the high resolution, dense text, and complex layouts typical of document images. These characteristics demand a high level of detail perception ability from MLLMs. While increasing input resolution improves detail perception, it also leads to longer sequences of visual tokens, increasing computational costs and straining the models' ability to handle long contexts. To address these challenges, we introduce DocKylin, a document-centric MLLM that performs visual content slimming at both the pixel and token levels, thereby reducing token sequence length in VDU scenarios. DocKylin utilizes an Adaptive Pixel Slimming (APS) preprocessing module to perform pixel-level slimming, increasing the proportion of informative pixels. Moreover, DocKylin incorporates a novel Dynamic Token Slimming (DTS) module to conduct token-level slimming, filtering essential tokens and removing others to create a compressed, adaptive visual sequence. Experiments demonstrate DocKylin's promising performance across various VDU benchmarks. Notably, both the proposed APS and DTS are parameter-free, facilitating easy integration into existing MLLMs, and our experiments indicate their potential for broader applications.
Hierarchical Side-Tuning for Vision Transformers
Oct 10, 2023



Fine-tuning pre-trained Vision Transformers (ViT) has consistently demonstrated promising performance in the realm of visual recognition. However, adapting large pre-trained models to various tasks poses a significant challenge. This challenge arises from the need for each model to undergo an independent and comprehensive fine-tuning process, leading to substantial computational and memory demands. While recent advancements in Parameter-efficient Transfer Learning (PETL) have demonstrated their ability to achieve superior performance compared to full fine-tuning with a smaller subset of parameter updates, they tend to overlook dense prediction tasks such as object detection and segmentation. In this paper, we introduce Hierarchical Side-Tuning (HST), a novel PETL approach that enables ViT transfer to various downstream tasks effectively. Diverging from existing methods that exclusively fine-tune parameters within input spaces or certain modules connected to the backbone, we tune a lightweight and hierarchical side network (HSN) that leverages intermediate activations extracted from the backbone and generates multi-scale features to make predictions. To validate HST, we conducted extensive experiments encompassing diverse visual tasks, including classification, object detection, instance segmentation, and semantic segmentation. Notably, our method achieves state-of-the-art average Top-1 accuracy of 76.0% on VTAB-1k, all while fine-tuning a mere 0.78M parameters. When applied to object detection tasks on COCO testdev benchmark, HST even surpasses full fine-tuning and obtains better performance with 49.7 box AP and 43.2 mask AP using Cascade Mask R-CNN.
High Accuracy Visible Light Positioning Based on Multi-target Tracking Algorithm
Mar 09, 2021
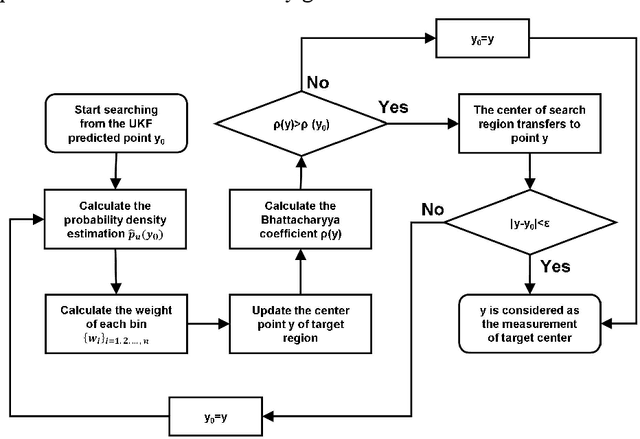

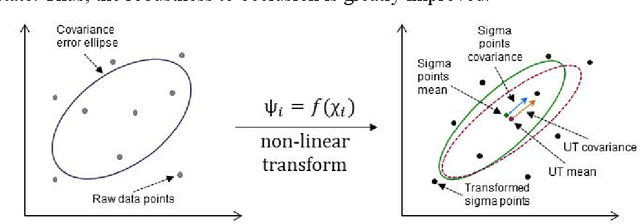
In this paper, we propose a multi-target image tracking algorithm based on continuously apative mean-shift (Cam-shift) and unscented Kalman filter. We improved the single-lamp tracking algorithm proposed in our previous work to multi-target tracking, and achieved better robustness in the case of occlusion, the real-time performance to complete one positioning and relatively high accuracy by dynamically adjusting the weights of the multi-target motion states. Our previous algorithm is limited to the analysis of tracking error. In this paper, the results of the tracking algorithm are evaluated with the tracking error we defined. Then combined with the double-lamp positioning algorithm, the real position of the terminal is calculated and evaluated with the positioning error we defined. Experiments show that the defined tracking error is 0.61cm and the defined positioning error for 3-D positioning is 3.29cm with the average processing time of 91.63ms per frame. Even if nearly half of the LED area is occluded, the tracking error remains at 5.25cm. All of this shows that the proposed visible light positioning (VLP) method can track multiple targets for positioning at the same time with good robustness, real-time performance and accuracy. In addition, the definition and analysis of tracking errors and positioning errors indicates the direction for future efforts to reduce errors.