 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice
Mar 09, 2022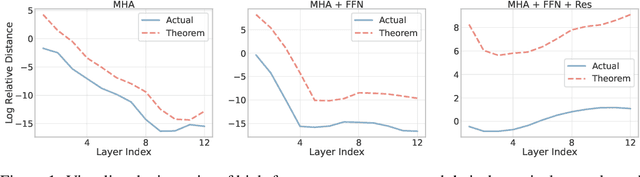
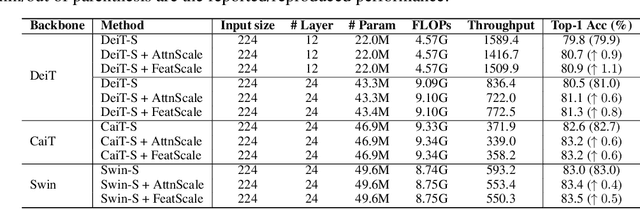
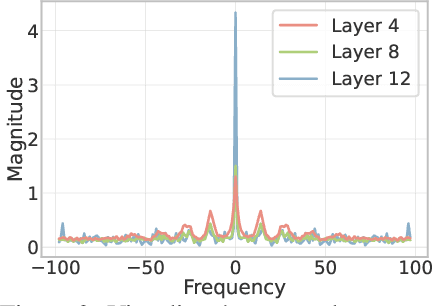
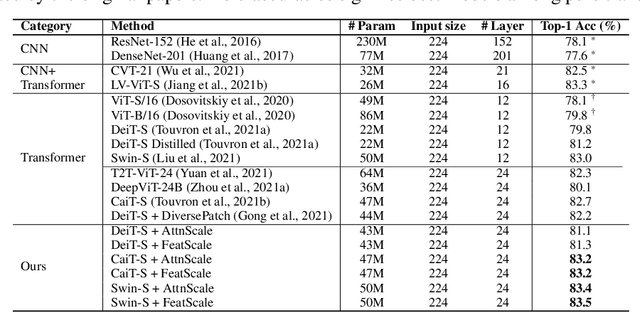
Vision Transformer (ViT) has recently demonstrated promise in computer vision problems. However, unlike Convolutional Neural Networks (CNN), it is known that the performance of ViT saturates quickly with depth increasing, due to the observed attention collapse or patch uniformity. Despite a couple of empirical solutions, a rigorous framework studying on this scalability issue remains elusive. In this paper, we first establish a rigorous theory framework to analyze ViT features from the Fourier spectrum domain. We show that the self-attention mechanism inherently amounts to a low-pass filter, which indicates when ViT scales up its depth, excessive low-pass filtering will cause feature maps to only preserve their Direct-Current (DC) component. We then propose two straightforward yet effective techniques to mitigate the undesirable low-pass limitation. The first technique, termed AttnScale, decomposes a self-attention block into low-pass and high-pass components, then rescales and combines these two filters to produce an all-pass self-attention matrix. The second technique, termed FeatScale, re-weights feature maps on separate frequency bands to amplify the high-frequency signals. Both techniques are efficient and hyperparameter-free, while effectively overcoming relevant ViT training artifacts such as attention collapse and patch uniformity. By seamlessly plugging in our techniques to multiple ViT variants, we demonstrate that they consistently help ViTs benefit from deeper architectures, bringing up to 1.1% performance gains "for free" (e.g., with little parameter overhead). We publicly release our codes and pre-trained models at https://github.com/VITA-Group/ViT-Anti-Oversmoothing.
Web of Scholars: A Scholar Knowledge Graph
Feb 23, 2022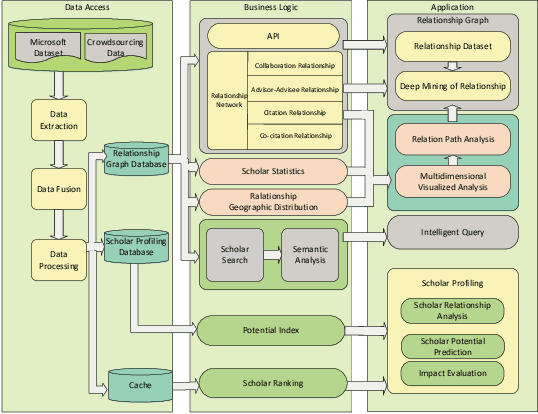
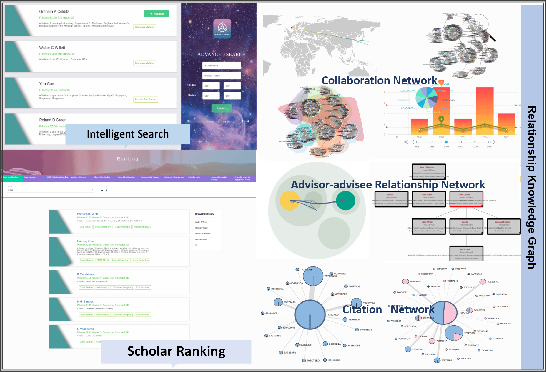
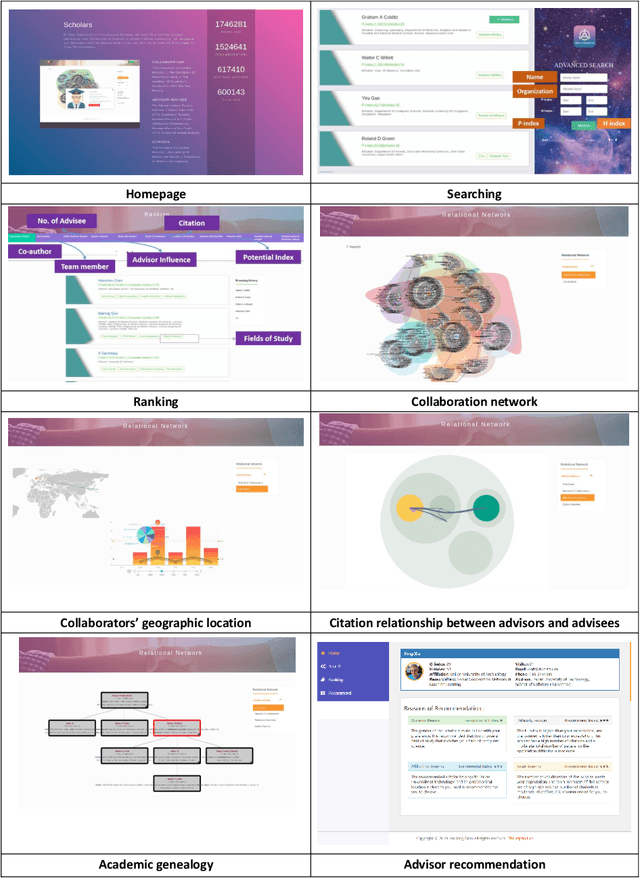
In this work, we demonstrate a novel system, namely Web of Scholars, which integrates state-of-the-art mining techniques to search, mine, and visualize complex networks behind scholars in the field of Computer Science. Relying on the knowledge graph, it provides services for fast, accurate, and intelligent semantic querying as well as powerful recommendations. In addition, in order to realize information sharing, it provides an open API to be served as the underlying architecture for advanced functions. Web of Scholars takes advantage of knowledge graph, which means that it will be able to access more knowledge if more search exist. It can be served as a useful and interoperable tool for scholars to conduct in-depth analysis within Science of Science.
Cold Brew: Distilling Graph Node Representations with Incomplete or Missing Neighborhoods
Nov 10, 2021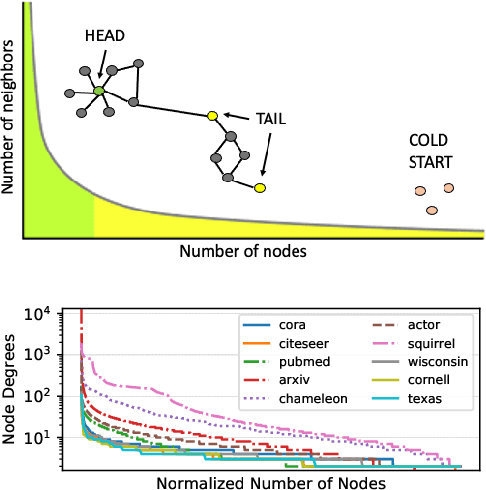
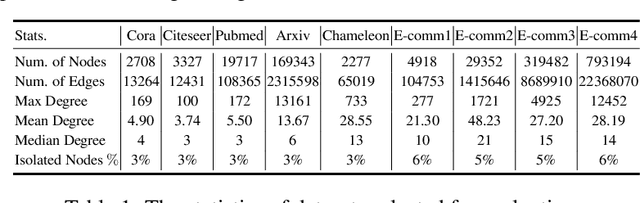
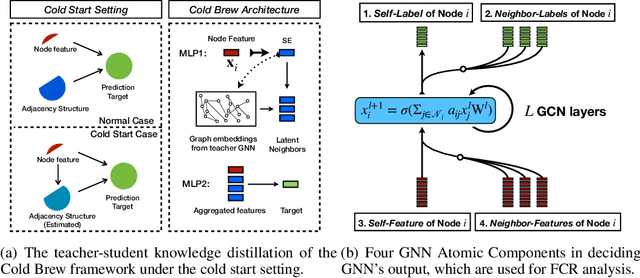
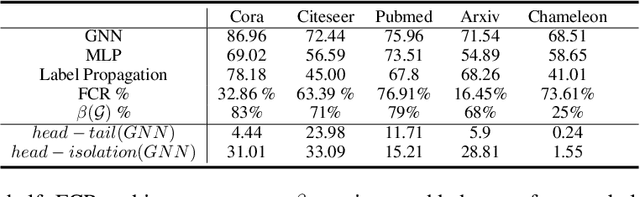
Graph Neural Networks (GNNs) have achieved state of the art performance in node classification, regression, and recommendation tasks. GNNs work well when high-quality and rich connectivity structure is available. However, this requirement is not satisfied in many real world graphs where the node degrees have power-law distributions as many nodes have either fewer or noisy connections. The extreme case of this situation is a node may have no neighbors at all, called Strict Cold Start (SCS) scenario. This forces the prediction models to rely completely on the node's input features. We propose Cold Brew to address the SCS and noisy neighbor setting compared to pointwise and other graph-based models via a distillation approach. We introduce feature-contribution ratio (FCR), a metric to study the viability of using inductive GNNs to solve the SCS problem and to select the best architecture for SCS generalization. We experimentally show FCR disentangles the contributions of various components of graph datasets and demonstrate the superior performance of Cold Brew on several public benchmarks and proprietary e-commerce datasets. The source code for our approach is available at: https://github.com/amazon-research/gnn-tail-generalization.
Delayed Propagation Transformer: A Universal Computation Engine towards Practical Control in Cyber-Physical Systems
Oct 29, 2021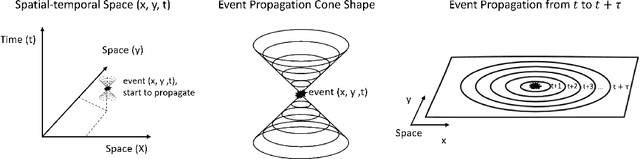
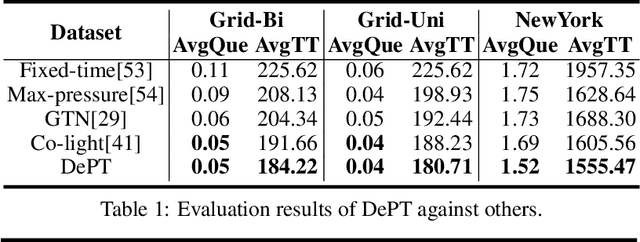
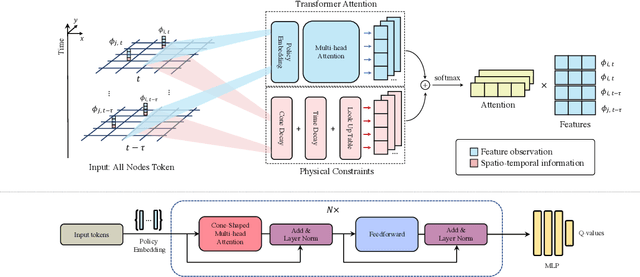
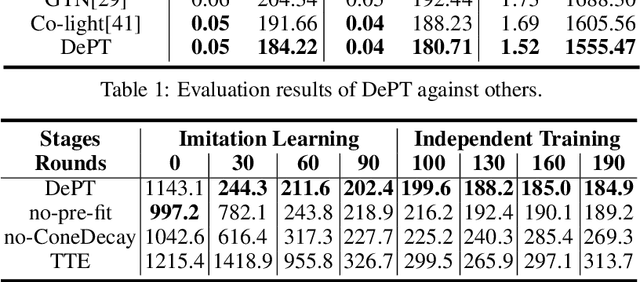
Multi-agent control is a central theme in the Cyber-Physical Systems (CPS). However, current control methods either receive non-Markovian states due to insufficient sensing and decentralized design, or suffer from poor convergence. This paper presents the Delayed Propagation Transformer (DePT), a new transformer-based model that specializes in the global modeling of CPS while taking into account the immutable constraints from the physical world. DePT induces a cone-shaped spatial-temporal attention prior, which injects the information propagation and aggregation principles and enables a global view. With physical constraint inductive bias baked into its design, our DePT is ready to plug and play for a broad class of multi-agent systems. The experimental results on one of the most challenging CPS -- network-scale traffic signal control system in the open world -- show that our model outperformed the state-of-the-art expert methods on synthetic and real-world datasets. Our codes are released at: https://github.com/VITA-Group/DePT.
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study
Aug 24, 2021
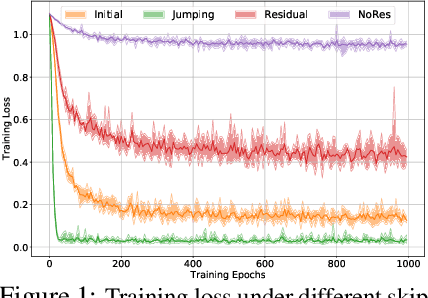

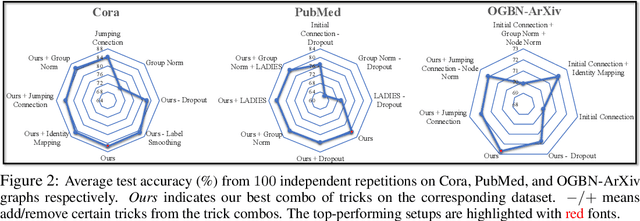
Training deep graph neural networks (GNNs) is notoriously hard. Besides the standard plights in training deep architectures such as vanishing gradients and overfitting, the training of deep GNNs also uniquely suffers from over-smoothing, information squashing, and so on, which limits their potential power on large-scale graphs. Although numerous efforts are proposed to address these limitations, such as various forms of skip connections, graph normalization, and random dropping, it is difficult to disentangle the advantages brought by a deep GNN architecture from those "tricks" necessary to train such an architecture. Moreover, the lack of a standardized benchmark with fair and consistent experimental settings poses an almost insurmountable obstacle to gauging the effectiveness of new mechanisms. In view of those, we present the first fair and reproducible benchmark dedicated to assessing the "tricks" of training deep GNNs. We categorize existing approaches, investigate their hyperparameter sensitivity, and unify the basic configuration. Comprehensive evaluations are then conducted on tens of representative graph datasets including the recent large-scale Open Graph Benchmark (OGB), with diverse deep GNN backbones. Based on synergistic studies, we discover the combo of superior training tricks, that lead us to attain the new state-of-the-art results for deep GCNs, across multiple representative graph datasets. We demonstrate that an organic combo of initial connection, identity mapping, group and batch normalization has the most ideal performance on large datasets. Experiments also reveal a number of "surprises" when combining or scaling up some of the tricks. All codes are available at https://github.com/VITA-Group/Deep_GCN_Benchmarking.
Scalable Perception-Action-Communication Loops with Convolutional and Graph Neural Networks
Jun 24, 2021In this paper, we present a perception-action-communication loop design using Vision-based Graph Aggregation and Inference (VGAI). This multi-agent decentralized learning-to-control framework maps raw visual observations to agent actions, aided by local communication among neighboring agents. Our framework is implemented by a cascade of a convolutional and a graph neural network (CNN / GNN), addressing agent-level visual perception and feature learning, as well as swarm-level communication, local information aggregation and agent action inference, respectively. By jointly training the CNN and GNN, image features and communication messages are learned in conjunction to better address the specific task. We use imitation learning to train the VGAI controller in an offline phase, relying on a centralized expert controller. This results in a learned VGAI controller that can be deployed in a distributed manner for online execution. Additionally, the controller exhibits good scaling properties, with training in smaller teams and application in larger teams. Through a multi-agent flocking application, we demonstrate that VGAI yields performance comparable to or better than other decentralized controllers, using only the visual input modality and without accessing precise location or motion state information.
Structured DropConnect for Uncertainty Inference in Image Classification
Jun 16, 2021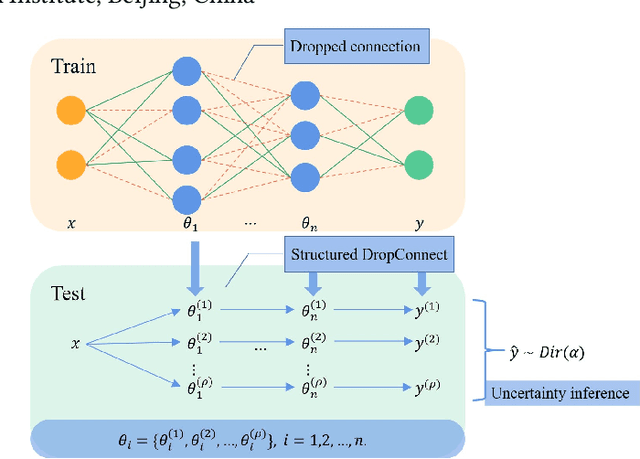


With the complexity of the network structure, uncertainty inference has become an important task to improve the classification accuracy for artificial intelligence systems. For image classification tasks, we propose a structured DropConnect (SDC) framework to model the output of a deep neural network by a Dirichlet distribution. We introduce a DropConnect strategy on weights in the fully connected layers during training. In test, we split the network into several sub-networks, and then model the Dirichlet distribution by match its moments with the mean and variance of the outputs of these sub-networks. The entropy of the estimated Dirichlet distribution is finally utilized for uncertainty inference. In this paper, this framework is implemented on LeNet$5$ and VGG$16$ models for misclassification detection and out-of-distribution detection on MNIST and CIFAR-$10$ datasets. Experimental results show that the performance of the proposed SDC can be comparable to other uncertainty inference methods. Furthermore, the SDC is adapted well to different network structures with certain generalization capabilities and research prospects.