 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative World Models: An Online-Offline Transfer RL Approach
May 25, 2023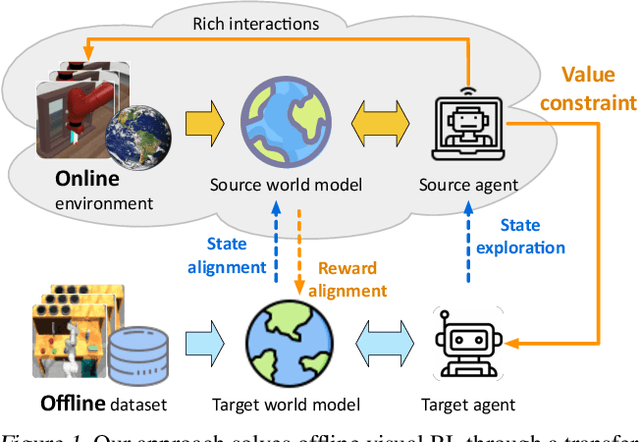

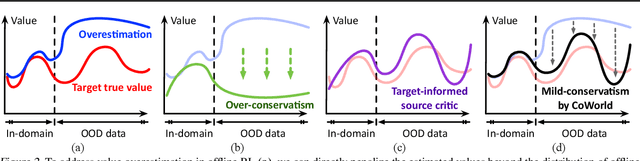
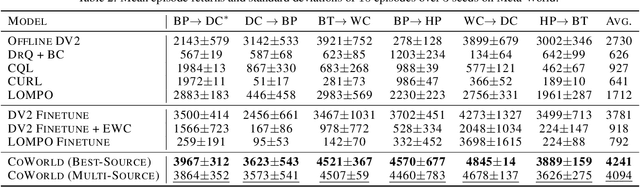
Training visual reinforcement learning (RL) models in offline datasets is challenging due to overfitting issues in representation learning and overestimation problems in value function. In this paper, we propose a transfer learning method called Collaborative World Models (CoWorld) to improve the performance of visual RL under offline conditions. The core idea is to use an easy-to-interact, off-the-shelf simulator to train an auxiliary RL model as the online "test bed" for the offline policy learned in the target domain, which provides a flexible constraint for the value function -- Intuitively, we want to mitigate the overestimation problem of value functions outside the offline data distribution without impeding the exploration of actions with potential advantages. Specifically, CoWorld performs domain-collaborative representation learning to bridge the gap between online and offline hidden state distributions. Furthermore, it performs domain-collaborative behavior learning that enables the source RL agent to provide target-aware value estimation, allowing for effective offline policy regularization. Experiments show that CoWorld significantly outperforms existing methods in offline visual control tasks in DeepMind Control and Meta-World.
NaviNeRF: NeRF-based 3D Representation Disentanglement by Latent Semantic Navigation
Apr 22, 20233D representation disentanglement aims to identify, decompose, and manipulate the underlying explanatory factors of 3D data, which helps AI fundamentally understand our 3D world. This task is currently under-explored and poses great challenges: (i) the 3D representations are complex and in general contains much more information than 2D image; (ii) many 3D representations are not well suited for gradient-based optimization, let alone disentanglement. To address these challenges, we use NeRF as a differentiable 3D representation, and introduce a self-supervised Navigation to identify interpretable semantic directions in the latent space. To our best knowledge, this novel method, dubbed NaviNeRF, is the first work to achieve fine-grained 3D disentanglement without any priors or supervisions. Specifically, NaviNeRF is built upon the generative NeRF pipeline, and equipped with an Outer Navigation Branch and an Inner Refinement Branch. They are complementary -- the outer navigation is to identify global-view semantic directions, and the inner refinement dedicates to fine-grained attributes. A synergistic loss is further devised to coordinate two branches. Extensive experiments demonstrate that NaviNeRF has a superior fine-grained 3D disentanglement ability than the previous 3D-aware models. Its performance is also comparable to editing-oriented models relying on semantic or geometry priors.
Inpaint Anything: Segment Anything Meets Image Inpainting
Apr 13, 2023


Modern image inpainting systems, despite the significant progress, often struggle with mask selection and holes filling. Based on Segment-Anything Model (SAM), we make the first attempt to the mask-free image inpainting and propose a new paradigm of ``clicking and filling'', which is named as Inpaint Anything (IA). The core idea behind IA is to combine the strengths of different models in order to build a very powerful and user-friendly pipeline for solving inpainting-related problems. IA supports three main features: (i) Remove Anything: users could click on an object and IA will remove it and smooth the ``hole'' with the context; (ii) Fill Anything: after certain objects removal, users could provide text-based prompts to IA, and then it will fill the hole with the corresponding generative content via driving AIGC models like Stable Diffusion; (iii) Replace Anything: with IA, users have another option to retain the click-selected object and replace the remaining background with the newly generated scenes. We are also very willing to help everyone share and promote new projects based on our Inpaint Anything (IA). Our codes are available at https://github.com/geekyutao/Inpaint-Anything.
Token is All You Need for Zero-Shot Semantic Segmentation
Apr 13, 2023



In this paper, we propose an embarrassingly simple yet highly effective zero-shot semantic segmentation (ZS3) method, based on the pre-trained vision-language model CLIP. First, our study provides a couple of key discoveries: (i) the global tokens (a.k.a [CLS] tokens in Transformer) of the text branch in CLIP provide a powerful representation of semantic information and (ii) these text-side [CLS] tokens can be regarded as category priors to guide CLIP visual encoder pay more attention on the corresponding region of interest. Based on that, we build upon the CLIP model as a backbone which we extend with a One-Way [CLS] token navigation from text to the visual branch that enables zero-shot dense prediction, dubbed \textbf{ClsCLIP}. Specifically, we use the [CLS] token output from the text branch, as an auxiliary semantic prompt, to replace the [CLS] token in shallow layers of the ViT-based visual encoder. This one-way navigation embeds such global category prior earlier and thus promotes semantic segmentation. Furthermore, to better segment tiny objects in ZS3, we further enhance ClsCLIP with a local zoom-in strategy, which employs a region proposal pre-processing and we get ClsCLIP+. Extensive experiments demonstrate that our proposed ZS3 method achieves a SOTA performance, and it is even comparable with those few-shot semantic segmentation methods.
StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion
Mar 30, 20233D semantic scene completion (SSC) is an ill-posed task that requires inferring a dense 3D scene from incomplete observations. Previous methods either explicitly incorporate 3D geometric input or rely on learnt 3D prior behind monocular RGB images. However, 3D sensors such as LiDAR are expensive and intrusive while monocular cameras face challenges in modeling precise geometry due to the inherent ambiguity. In this work, we propose StereoScene for 3D Semantic Scene Completion (SSC), which explores taking full advantage of light-weight camera inputs without resorting to any external 3D sensors. Our key insight is to leverage stereo matching to resolve geometric ambiguity. To improve its robustness in unmatched areas, we introduce bird's-eye-view (BEV) representation to inspire hallucination ability with rich context information. On top of the stereo and BEV representations, a mutual interactive aggregation (MIA) module is carefully devised to fully unleash their power. Specifically, a Bi-directional Interaction Transformer (BIT) augmented with confidence re-weighting is used to encourage reliable prediction through mutual guidance while a Dual Volume Aggregation (DVA) module is designed to facilitate complementary aggregation. Experimental results on SemanticKITTI demonstrate that the proposed StereoScene outperforms the state-of-the-art camera-based methods by a large margin with a relative improvement of 26.9% in geometry and 38.6% in semantic.
Automatic Intrinsic Reward Shaping for Exploration in Deep Reinforcement Learning
Jan 26, 2023We present AIRS: Automatic Intrinsic Reward Shaping that intelligently and adaptively provides high-quality intrinsic rewards to enhance exploration in reinforcement learning (RL). More specifically, AIRS selects shaping function from a predefined set based on the estimated task return in real-time, providing reliable exploration incentives and alleviating the biased objective problem. Moreover, we develop an intrinsic reward toolkit to provide efficient and reliable implementations of diverse intrinsic reward approaches. We test AIRS on various tasks of Procgen games and DeepMind Control Suite. Extensive simulation demonstrates that AIRS can outperform the benchmarking schemes and achieve superior performance with simple architecture.
Tackling Visual Control via Multi-View Exploration Maximization
Nov 28, 2022



We present MEM: Multi-view Exploration Maximization for tackling complex visual control tasks. To the best of our knowledge, MEM is the first approach that combines multi-view representation learning and intrinsic reward-driven exploration in reinforcement learning (RL). More specifically, MEM first extracts the specific and shared information of multi-view observations to form high-quality features before performing RL on the learned features, enabling the agent to fully comprehend the environment and yield better actions. Furthermore, MEM transforms the multi-view features into intrinsic rewards based on entropy maximization to encourage exploration. As a result, MEM can significantly promote the sample-efficiency and generalization ability of the RL agent, facilitating solving real-world problems with high-dimensional observations and spare-reward space. We evaluate MEM on various tasks from DeepMind Control Suite and Procgen games. Extensive simulation results demonstrate that MEM can achieve superior performance and outperform the benchmarking schemes with simple architecture and higher efficiency.
Rewarding Episodic Visitation Discrepancy for Exploration in Reinforcement Learning
Sep 25, 2022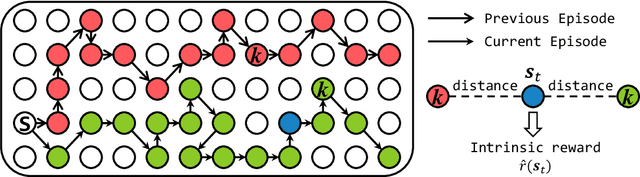
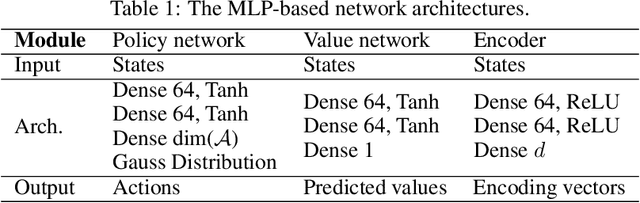
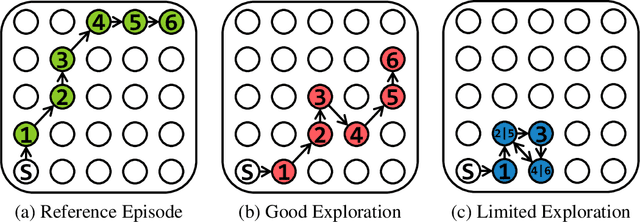
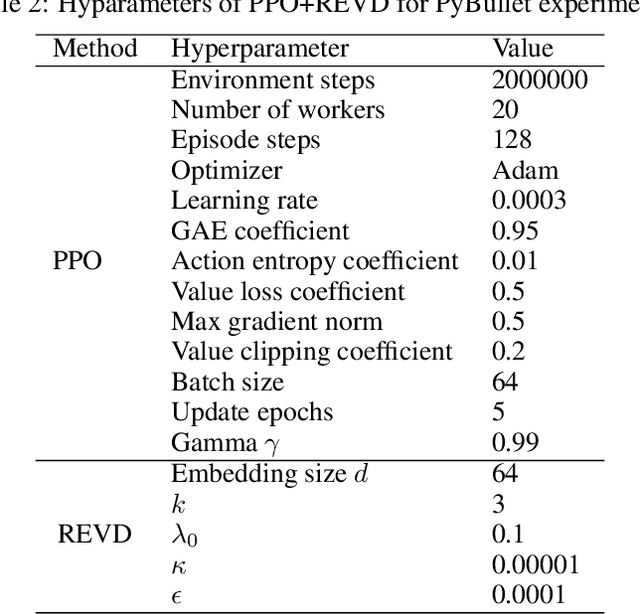
Exploration is critical for deep reinforcement learning in complex environments with high-dimensional observations and sparse rewards. To address this problem, recent approaches proposed to leverage intrinsic rewards to improve exploration, such as novelty-based exploration and prediction-based exploration. However, many intrinsic reward modules require sophisticated structures and representation learning, resulting in prohibitive computational complexity and unstable performance. In this paper, we propose Rewarding Episodic Visitation Discrepancy (REVD), a computation-efficient and quantified exploration method. More specifically, REVD provides intrinsic rewards by evaluating the R\'enyi divergence-based visitation discrepancy between episodes. To make efficient divergence estimation, a k-nearest neighbor estimator is utilized with a randomly-initialized state encoder. Finally, the REVD is tested on Atari games and PyBullet Robotics Environments. Extensive experiments demonstrate that REVD can significantly improves the sample efficiency of reinforcement learning algorithms and outperforms the benchmarking methods.
A Nonparametric Contextual Bandit with Arm-level Eligibility Control for Customer Service Routing
Sep 08, 2022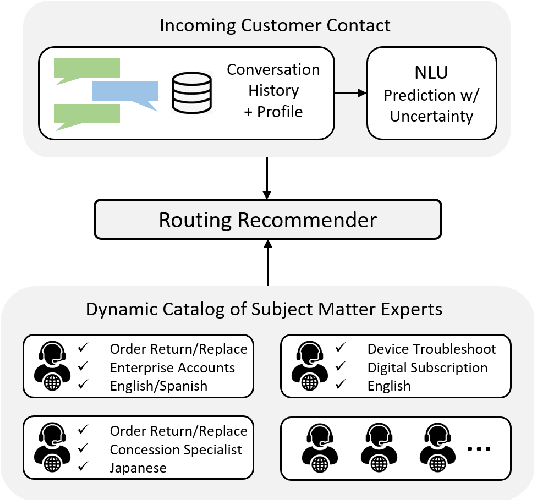
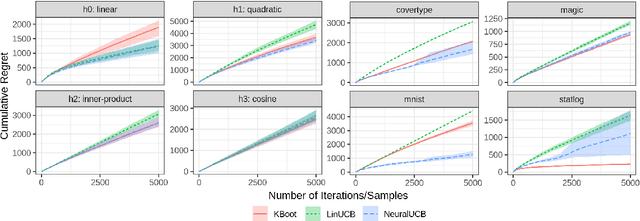
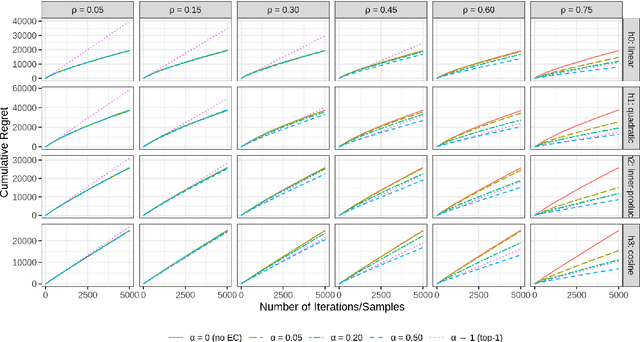
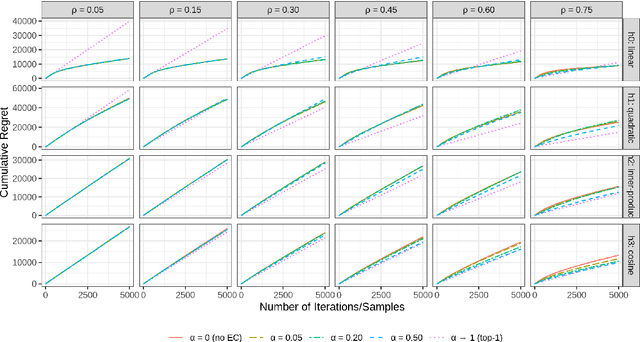
Amazon Customer Service provides real-time support for millions of customer contacts every year. While bot-resolver helps automate some traffic, we still see high demand for human agents, also called subject matter experts (SMEs). Customers outreach with questions in different domains (return policy, device troubleshooting, etc.). Depending on their training, not all SMEs are eligible to handle all contacts. Routing contacts to eligible SMEs turns out to be a non-trivial problem because SMEs' domain eligibility is subject to training quality and can change over time. To optimally recommend SMEs while simultaneously learning the true eligibility status, we propose to formulate the routing problem with a nonparametric contextual bandit algorithm (K-Boot) plus an eligibility control (EC) algorithm. K-Boot models reward with a kernel smoother on similar past samples selected by $k$-NN, and Bootstrap Thompson Sampling for exploration. EC filters arms (SMEs) by the initially system-claimed eligibility and dynamically validates the reliability of this information. The proposed K-Boot is a general bandit algorithm, and EC is applicable to other bandits. Our simulation studies show that K-Boot performs on par with state-of-the-art Bandit models, and EC boosts K-Boot performance when stochastic eligibility signal exists.
Robust Multi-Object Tracking by Marginal Inference
Aug 07, 2022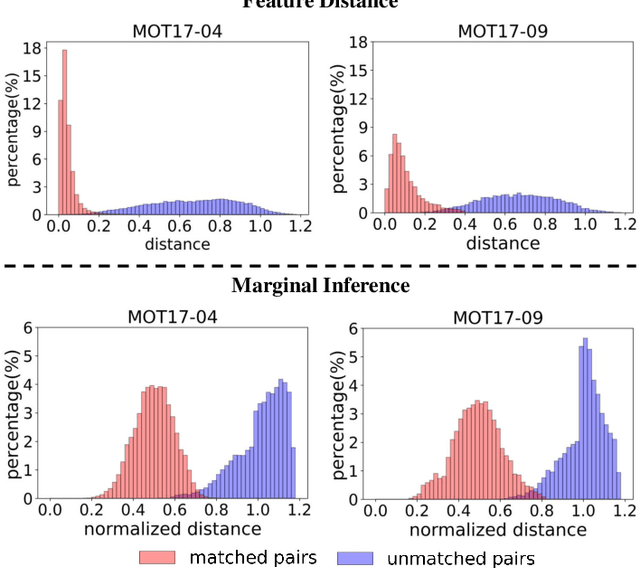
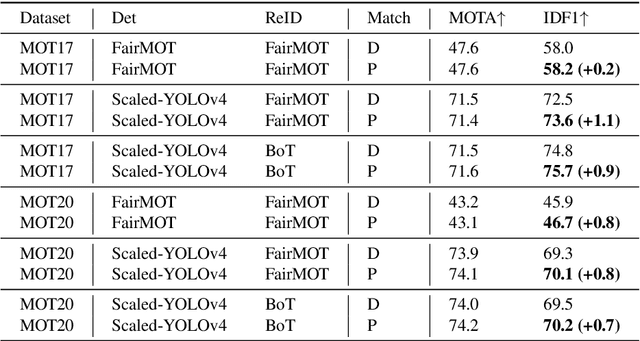
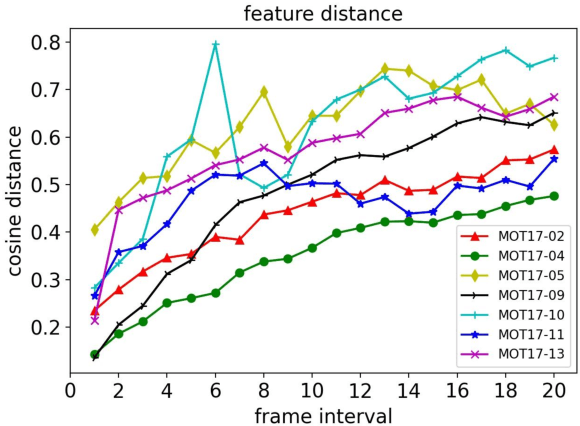

Multi-object tracking in videos requires to solve a fundamental problem of one-to-one assignment between objects in adjacent frames. Most methods address the problem by first discarding impossible pairs whose feature distances are larger than a threshold, followed by linking objects using Hungarian algorithm to minimize the overall distance. However, we find that the distribution of the distances computed from Re-ID features may vary significantly for different videos. So there isn't a single optimal threshold which allows us to safely discard impossible pairs. To address the problem, we present an efficient approach to compute a marginal probability for each pair of objects in real time. The marginal probability can be regarded as a normalized distance which is significantly more stable than the original feature distance. As a result, we can use a single threshold for all videos. The approach is general and can be applied to the existing trackers to obtain about one point improvement in terms of IDF1 metric. It achieves competitive results on MOT17 and MOT20 benchmarks. In addition, the computed probability is more interpretable which facilitates subsequent post-processing operations.