 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^3$P-VoxelMap: Compact, Cumulative and Coalescible Probabilistic Voxel Mapping
Jun 03, 2024This work presents a compact, cumulative and coalescible probabilistic voxel mapping method to enhance performance, accuracy and memory efficiency in LiDAR odometry. Probabilistic voxel mapping requires storing past point clouds and re-iterating on them to update the uncertainty every iteration, which consumes large memory space and CPU cycles. To solve this problem, we propose a two-folded strategy. First, we introduce a compact point-free representation for probabilistic voxels and derive a cumulative update of the planar uncertainty without caching original point clouds. Our voxel structure only keeps track of a predetermined set of statistics for points that lie inside it. This method reduces the runtime complexity from $O(MN)$ to $O(N)$ and the space complexity from $O(N)$ to $O(1)$ where $M$ is the number of iterations and $N$ is the number of points. Second, to further minimize memory usage and enhance mapping accuracy, we provide a strategy to dynamically merge voxels associated with the same physical planes by taking advantage of the geometric features in the real world. Rather than scanning for these coalescible voxels constantly at every iteration, our merging strategy accumulates voxels in a locality-sensitive hash and triggers merging lazily. On-demand merging not only reduces memory footprint with minimal computational overhead but also improves localization accuracy thanks to cross-voxel denoising. Experiments exhibit 20% higher accuracy, 20% faster performance and 70% lower memory consumption than the state-of-the-art.
An Efficient Volumetric Mesh Representation for Real-time Scene Reconstruction using Spatial Hashing
Mar 11, 2018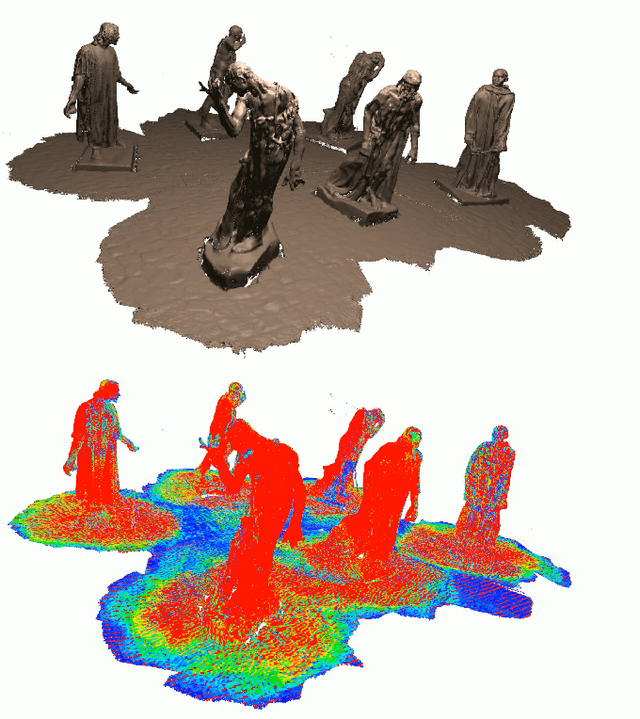
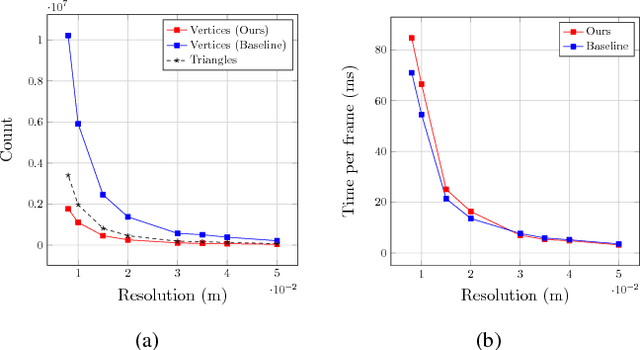
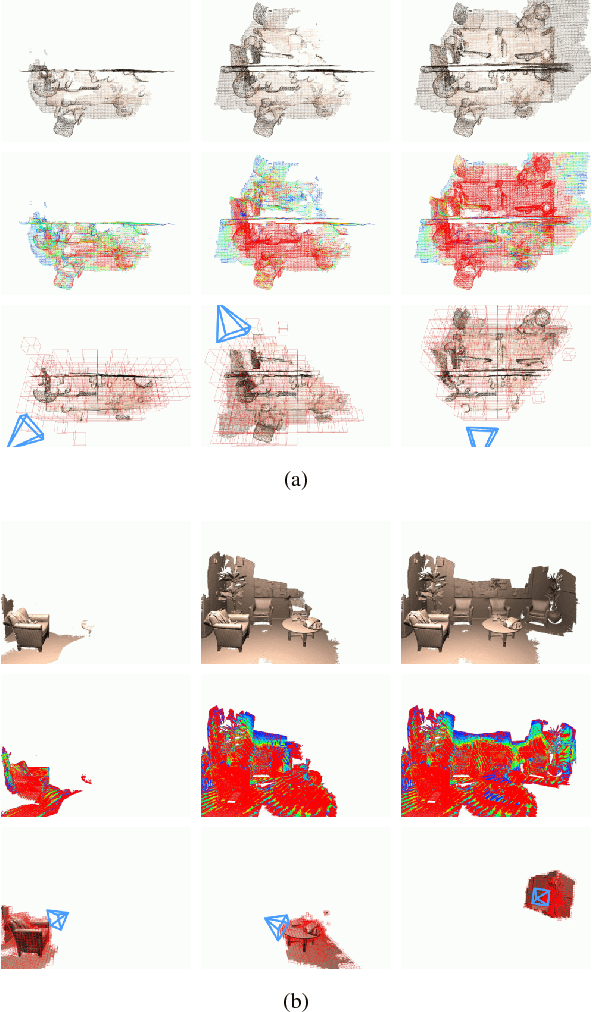
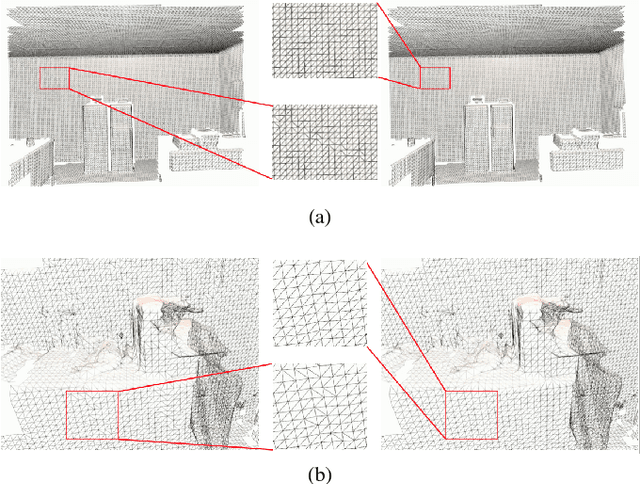
Mesh plays an indispensable role in dense real-time reconstruction essential in robotics. Efforts have been made to maintain flexible data structures for 3D data fusion, yet an efficient incremental framework specifically designed for online mesh storage and manipulation is missing. We propose a novel framework to compactly generate, update, and refine mesh for scene reconstruction upon a volumetric representation. Maintaining a spatial-hashed field of cubes, we distribute vertices with continuous value on discrete edges that support O(1) vertex accessing and forbid memory redundancy. By introducing Hamming distance in mesh refinement, we further improve the mesh quality regarding the triangle type consistency with a low cost. Lock-based and lock-free operations were applied to avoid thread conflicts in GPU parallel computation. Experiments demonstrate that the mesh memory consumption is significantly reduced while the running speed is kept in the online reconstruction process.