 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLORE: Content-Level Optimization for Reasoning Efficiency
May 21, 2026Reinforcement learning post-training has improved the reasoning ability of large language models, but often produces unnecessarily long, repetitive, or semantically opaque reasoning traces. Existing efficient reasoning methods mainly regulate response length through explicit budgets or length-aware rewards, leaving intermediate reasoning content weakly supervised. We propose CLORE, a content-level optimization framework that improves reasoning efficiency by editing correct on-policy rollouts. CLORE uses an external augmentation model to delete repetitive segments, illegible or task-irrelevant content, and superfluous reasoning after the solution is established, while preserving the final answer. The resulting augmented--original pairs are optimized with an auxiliary reference-free DPO objective alongside standard policy-gradient training. By restricting augmentation to correct trajectories and performing local deletion, CLORE keeps edited rollouts close to the policy distribution and mitigates off-policy mismatch. Experiments on DeepSeek-R1-Distill-Qwen-7B and Qwen2.5-Math-7B across five mathematical reasoning benchmarks show that CLORE improves the accuracy--efficiency trade-off and remains compatible with GRPO, DAPO, Training Efficient, and ThinkPrune. Content-level analyses further show that CLORE reduces repetitive reasoning, illegible content, and post-answer exploration, supporting content-level supervision as a complementary direction to length-level control.
Divide and Conquer: Accelerating Diffusion-Based Large Language Models via Adaptive Parallel Decoding
Feb 27, 2026Diffusion-based large language models (dLLMs) have shown promising performance across various reasoning tasks, establishing themselves as an alternative to autoregressive large language models (LLMs). Unlike autoregressive LLMs that generate one token per step based on all previous tokens, dLLMs theoretically enable parallel generation of multiple tokens at each decoding step. However, recent dLLMs still favor one-token-per-step generation in practice, as directly decoding multiple masked tokens often leads to degraded generation quality and stability. This reveals a substantial gap between the theoretical parallelism and practical performance of dLLMs. To bridge this gap, we introduce an adaptive parallel decoding approach, namely DiCo, which features a three-phase divide-and-conquer paradigm to unleash the inherent parallelism of dLLMs. During the Divide phase, DiCo first explores the input masked sequence and identifies masked tokens as seed tokens, which are then expanded to construct a set of local clusters. During the Conquer phase, DiCo performs parallel decoding across different local clusters constructed in the Divide phase. The divide-and-conquer process repeatedly alternates between the Divide and Conquer phases until convergence. During the Finalize phase, DiCo decodes the remaining few masked tokens using an effective fine-grained compound decoding scheme to finalize the generation. Extensive experiments demonstrate that DiCo can achieve significant inference speedups while maintaining competitive generation quality.
MosaicThinker: On-Device Visual Spatial Reasoning for Embodied AI via Iterative Construction of Space Representation
Feb 06, 2026When embodied AI is expanding from traditional object detection and recognition to more advanced tasks of robot manipulation and actuation planning, visual spatial reasoning from the video inputs is necessary to perceive the spatial relationships of objects and guide device actions. However, existing visual language models (VLMs) have very weak capabilities in spatial reasoning due to the lack of knowledge about 3D spatial information, especially when the reasoning task involve complex spatial relations across multiple video frames. In this paper, we present a new inference-time computing technique for on-device embodied AI, namely \emph{MosaicThinker}, which enhances the on-device small VLM's spatial reasoning capabilities on difficult cross-frame reasoning tasks. Our basic idea is to integrate fragmented spatial information from multiple frames into a unified space representation of global semantic map, and further guide the VLM's spatial reasoning over the semantic map via a visual prompt. Experiment results show that our technique can greatly enhance the accuracy of cross-frame spatial reasoning on resource-constrained embodied AI devices, over reasoning tasks with diverse types and complexities.
Exploring Deep-to-Shallow Transformable Neural Networks for Intelligent Embedded Systems
Dec 17, 2025



Thanks to the evolving network depth, convolutional neural networks (CNNs) have achieved remarkable success across various embedded scenarios, paving the way for ubiquitous embedded intelligence. Despite its promise, the evolving network depth comes at the cost of degraded hardware efficiency. In contrast to deep networks, shallow networks can deliver superior hardware efficiency but often suffer from inferior accuracy. To address this dilemma, we propose Double-Win NAS, a novel deep-to-shallow transformable neural architecture search (NAS) paradigm tailored for resource-constrained intelligent embedded systems. Specifically, Double-Win NAS strives to automatically explore deep networks to first win strong accuracy, which are then equivalently transformed into their shallow counterparts to further win strong hardware efficiency. In addition to search, we also propose two enhanced training techniques, including hybrid transformable training towards better training accuracy and arbitrary-resolution elastic training towards enabling natural network elasticity across arbitrary input resolutions. Extensive experimental results on two popular intelligent embedded systems (i.e., NVIDIA Jetson AGX Xavier and NVIDIA Jetson Nano) and two representative large-scale datasets (i.e., ImageNet and ImageNet-100) clearly demonstrate the superiority of Double-Win NAS over previous state-of-the-art NAS approaches.
Efficient Deep Learning Infrastructures for Embedded Computing Systems: A Comprehensive Survey and Future Envision
Nov 03, 2024Deep neural networks (DNNs) have recently achieved impressive success across a wide range of real-world vision and language processing tasks, spanning from image classification to many other downstream vision tasks, such as object detection, tracking, and segmentation. However, previous well-established DNNs, despite being able to maintain superior accuracy, have also been evolving to be deeper and wider and thus inevitably necessitate prohibitive computational resources for both training and inference. This trend further enlarges the computational gap between computation-intensive DNNs and resource-constrained embedded computing systems, making it challenging to deploy powerful DNNs upon real-world embedded computing systems towards ubiquitous embedded intelligence. To alleviate the above computational gap and enable ubiquitous embedded intelligence, we, in this survey, focus on discussing recent efficient deep learning infrastructures for embedded computing systems, spanning from training to inference, from manual to automated, from convolutional neural networks to transformers, from transformers to vision transformers, from vision models to large language models, from software to hardware, and from algorithms to applications. Specifically, we discuss recent efficient deep learning infrastructures for embedded computing systems from the lens of (1) efficient manual network design for embedded computing systems, (2) efficient automated network design for embedded computing systems, (3) efficient network compression for embedded computing systems, (4) efficient on-device learning for embedded computing systems, (5) efficient large language models for embedded computing systems, (6) efficient deep learning software and hardware for embedded computing systems, and (7) efficient intelligent applications for embedded computing systems.
Enabling Energy-Efficient Deployment of Large Language Models on Memristor Crossbar: A Synergy of Large and Small
Oct 21, 2024Large language models (LLMs) have garnered substantial attention due to their promising applications in diverse domains. Nevertheless, the increasing size of LLMs comes with a significant surge in the computational requirements for training and deployment. Memristor crossbars have emerged as a promising solution, which demonstrated a small footprint and remarkably high energy efficiency in computer vision (CV) models. Memristors possess higher density compared to conventional memory technologies, making them highly suitable for effectively managing the extreme model size associated with LLMs. However, deploying LLMs on memristor crossbars faces three major challenges. Firstly, the size of LLMs increases rapidly, already surpassing the capabilities of state-of-the-art memristor chips. Secondly, LLMs often incorporate multi-head attention blocks, which involve non-weight stationary multiplications that traditional memristor crossbars cannot support. Third, while memristor crossbars excel at performing linear operations, they are not capable of executing complex nonlinear operations in LLM such as softmax and layer normalization. To address these challenges, we present a novel architecture for the memristor crossbar that enables the deployment of state-of-the-art LLM on a single chip or package, eliminating the energy and time inefficiencies associated with off-chip communication. Our testing on BERT_Large showed negligible accuracy loss. Compared to traditional memristor crossbars, our architecture achieves enhancements of up to 39X in area overhead and 18X in energy consumption. Compared to modern TPU/GPU systems, our architecture demonstrates at least a 68X reduction in the area-delay product and a significant 69% energy consumption reduction.
You Only Search Once: On Lightweight Differentiable Architecture Search for Resource-Constrained Embedded Platforms
Aug 30, 2022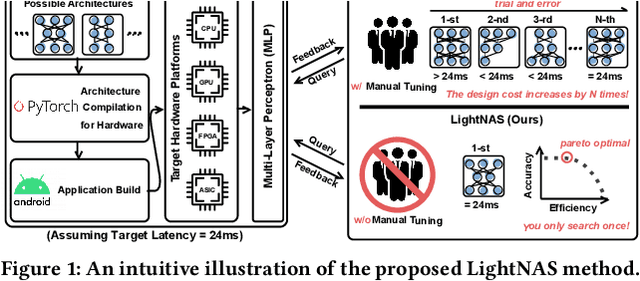

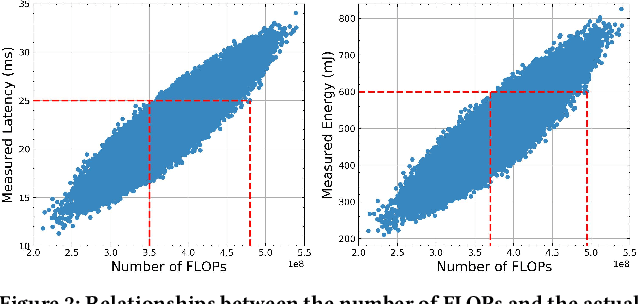
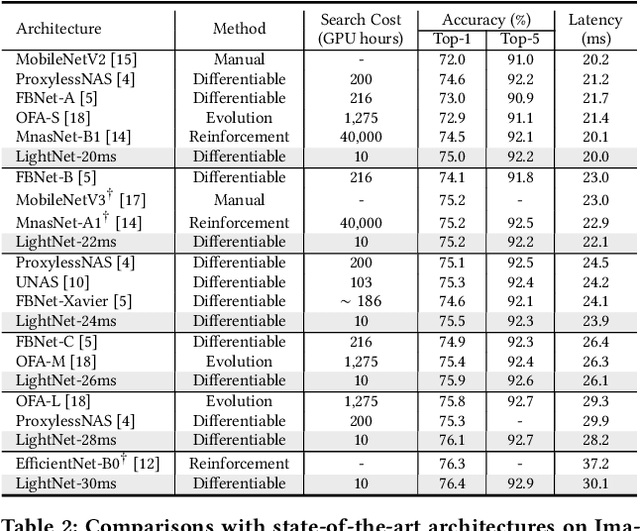
Benefiting from the search efficiency, differentiable neural architecture search (NAS) has evolved as the most dominant alternative to automatically design competitive deep neural networks (DNNs). We note that DNNs must be executed under strictly hard performance constraints in real-world scenarios, for example, the runtime latency on autonomous vehicles. However, to obtain the architecture that meets the given performance constraint, previous hardware-aware differentiable NAS methods have to repeat a plethora of search runs to manually tune the hyper-parameters by trial and error, and thus the total design cost increases proportionally. To resolve this, we introduce a lightweight hardware-aware differentiable NAS framework dubbed LightNAS, striving to find the required architecture that satisfies various performance constraints through a one-time search (i.e., \underline{\textit{you only search once}}). Extensive experiments are conducted to show the superiority of LightNAS over previous state-of-the-art methods.
FAT: An In-Memory Accelerator with Fast Addition for Ternary Weight Neural Networks
Jan 19, 2022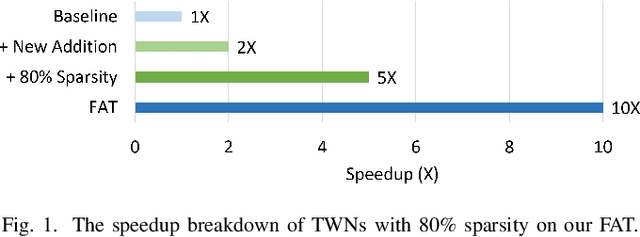
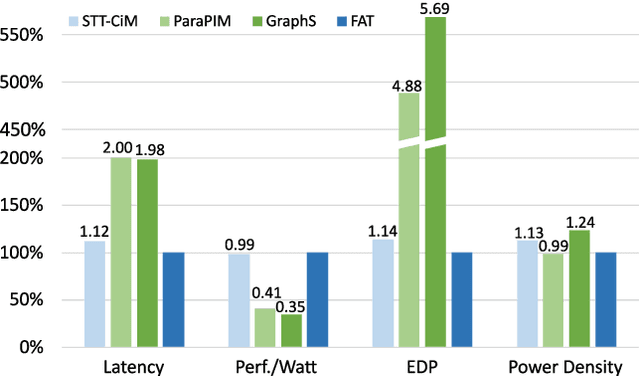

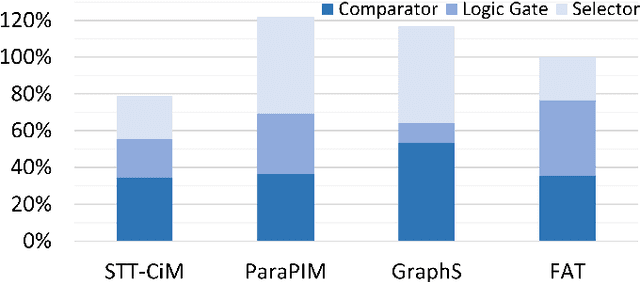
Convolutional Neural Networks (CNNs) demonstrate great performance in various applications but have high computational complexity. Quantization is applied to reduce the latency and storage cost of CNNs. Among the quantization methods, Binary and Ternary Weight Networks (BWNs and TWNs) have a unique advantage over 8-bit and 4-bit quantization. They replace the multiplication operations in CNNs with additions, which are favoured on In-Memory-Computing (IMC) devices. IMC acceleration for BWNs has been widely studied. However, though TWNs have higher accuracy and better sparsity, IMC acceleration for TWNs has limited research. TWNs on existing IMC devices are inefficient because the sparsity is not well utilized, and the addition operation is not efficient. In this paper, we propose FAT as a novel IMC accelerator for TWNs. First, we propose a Sparse Addition Control Unit, which utilizes the sparsity of TWNs to skip the null operations on zero weights. Second, we propose a fast addition scheme based on the memory Sense Amplifier to avoid the time overhead of both carry propagation and writing back the carry to the memory cells. Third, we further propose a Combined-Stationary data mapping to reduce the data movement of both activations and weights and increase the parallelism of memory columns. Simulation results show that for addition operations at the Sense Amplifier level, FAT achieves 2.00X speedup, 1.22X power efficiency and 1.22X area efficiency compared with State-Of-The-Art IMC accelerator ParaPIM. FAT achieves 10.02X speedup and 12.19X energy efficiency compared with ParaPIM on networks with 80% sparsity
HSCoNAS: Hardware-Software Co-Design of Efficient DNNs via Neural Architecture Search
Mar 11, 2021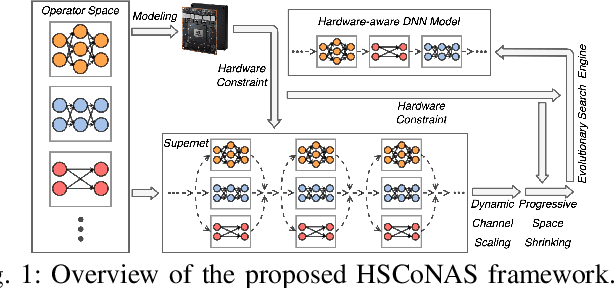
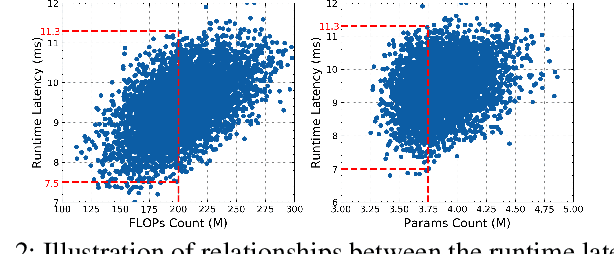
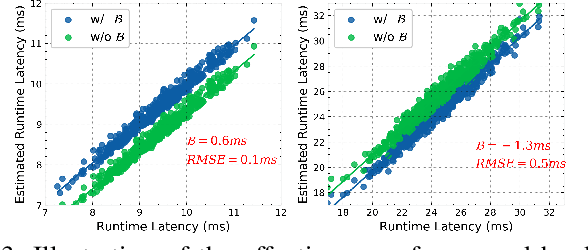
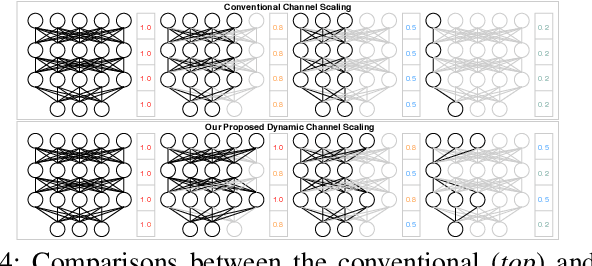
In this paper, we present a novel multi-objective hardware-aware neural architecture search (NAS) framework, namely HSCoNAS, to automate the design of deep neural networks (DNNs) with high accuracy but low latency upon target hardware. To accomplish this goal, we first propose an effective hardware performance modeling method to approximate the runtime latency of DNNs on target hardware, which will be integrated into HSCoNAS to avoid the tedious on-device measurements. Besides, we propose two novel techniques, i.e., dynamic channel scaling to maximize the accuracy under the specified latency and progressive space shrinking to refine the search space towards target hardware as well as alleviate the search overheads. These two techniques jointly work to allow HSCoNAS to perform fine-grained and efficient explorations. Finally, an evolutionary algorithm (EA) is incorporated to conduct the architecture search. Extensive experiments on ImageNet are conducted upon diverse target hardware, i.e., GPU, CPU, and edge device to demonstrate the superiority of HSCoNAS over recent state-of-the-art approaches.
Bringing AI To Edge: From Deep Learning's Perspective
Nov 25, 2020
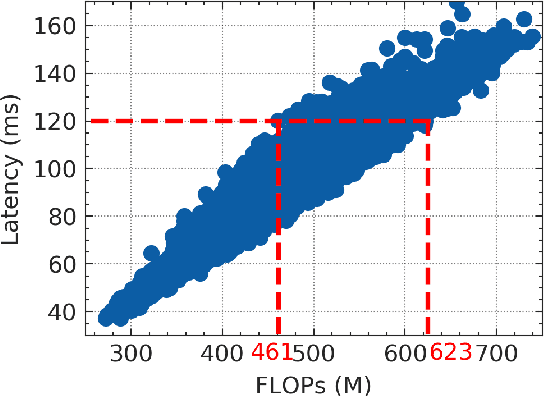
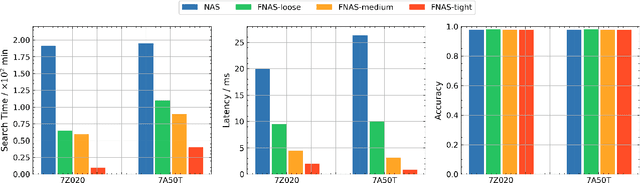
Edge computing and artificial intelligence (AI), especially deep learning for nowadays, are gradually intersecting to build a novel system, called edge intelligence. However, the development of edge intelligence systems encounters some challenges, and one of these challenges is the \textit{computational gap} between computation-intensive deep learning algorithms and less-capable edge systems. Due to the computational gap, many edge intelligence systems cannot meet the expected performance requirements. To bridge the gap, a plethora of deep learning techniques and optimization methods are proposed in the past years: light-weight deep learning models, network compression, and efficient neural architecture search. Although some reviews or surveys have partially covered this large body of literature, we lack a systematic and comprehensive review to discuss all aspects of these deep learning techniques which are critical for edge intelligence implementation. As various and diverse methods which are applicable to edge systems are proposed intensively, a holistic review would enable edge computing engineers and community to know the state-of-the-art deep learning techniques which are instrumental for edge intelligence and to facilitate the development of edge intelligence systems. This paper surveys the representative and latest deep learning techniques that are useful for edge intelligence systems, including hand-crafted models, model compression, hardware-aware neural architecture search and adaptive deep learning models. Finally, based on observations and simple experiments we conducted, we discuss some future directions.