 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Earth is Flat because: Investigating LLMs' Belief towards Misinformation via Persuasive Conversation
Dec 29, 2023Large Language Models (LLMs) encapsulate vast amounts of knowledge but still remain vulnerable to external misinformation. Existing research mainly studied this susceptibility behavior in a single-turn setting. However, belief can change during a multi-turn conversation, especially a persuasive one. Therefore, in this study, we delve into LLMs' susceptibility to persuasive conversations, particularly on factual questions that they can answer correctly. We first curate the Farm (i.e., Fact to Misinform) dataset, which contains factual questions paired with systematically generated persuasive misinformation. Then, we develop a testing framework to track LLMs' belief changes in a persuasive dialogue. Through extensive experiments, we find that LLMs' correct beliefs on factual knowledge can be easily manipulated by various persuasive strategies.
On Secrecy Performance of RIS-Assisted MISO Systems over Rician Channels with Spatially Random Eavesdroppers
Dec 28, 2023



Reconfigurable intelligent surface (RIS) technology is emerging as a promising technique for performance enhancement for next-generation wireless networks. This paper investigates the physical layer security of an RIS-assisted multiple-antenna communication system in the presence of random spatially distributed eavesdroppers. The RIS-to-ground channels are assumed to experience Rician fading. Using stochastic geometry, exact distributions of the received signal-to-noise-ratios (SNRs) at the legitimate user and the eavesdroppers located according to a Poisson point process (PPP) are derived, and closed-form expressions for the secrecy outage probability (SOP) and the ergodic secrecy capacity (ESC) are obtained to provide insightful guidelines for system design. First, the secrecy diversity order is obtained as $\frac{2}{\alpha_2}$, where $\alpha_2$ denotes the path loss exponent of the RIS-to-ground links. Then, it is revealed that the secrecy performance is mainly affected by the number of RIS reflecting elements, $N$, and the impact of the number of transmit antennas and transmit power at the base station is marginal. In addition, when the locations of the randomly located eavesdroppers are unknown, deploying the RIS closer to the legitimate user rather than to the base station is shown to be more efficient. Moreover, it is also found that the density of randomly located eavesdroppers, $\lambda_e$, has an additive effect on the asymptotic ESC performance given by $\log_2{\left({1}/{\lambda_e}\right)}$. Finally, numerical simulations are conducted to verify the accuracy of these theoretical observations.
Deep-Unfolding-Based Joint Activity and Data Detection for Grant-Free Transmission in Cell-Free Communication Systems
Dec 20, 2023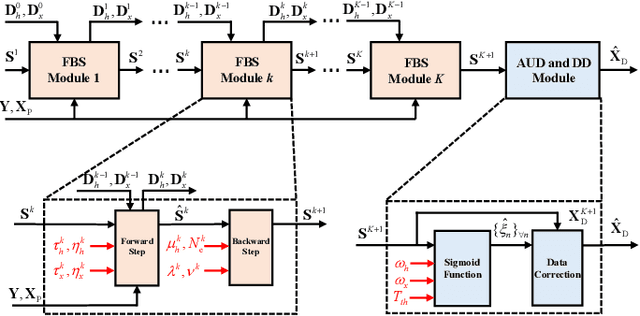
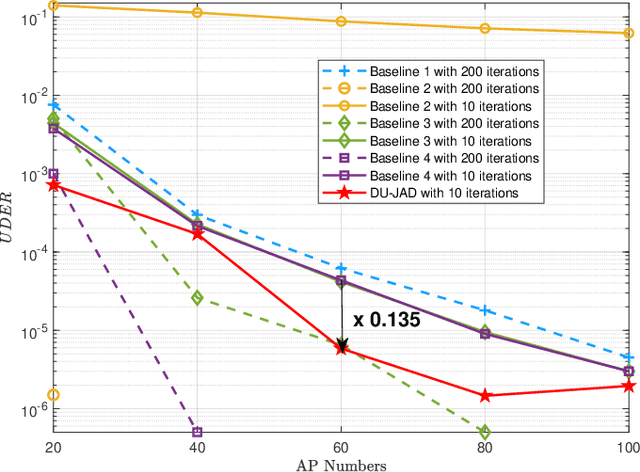
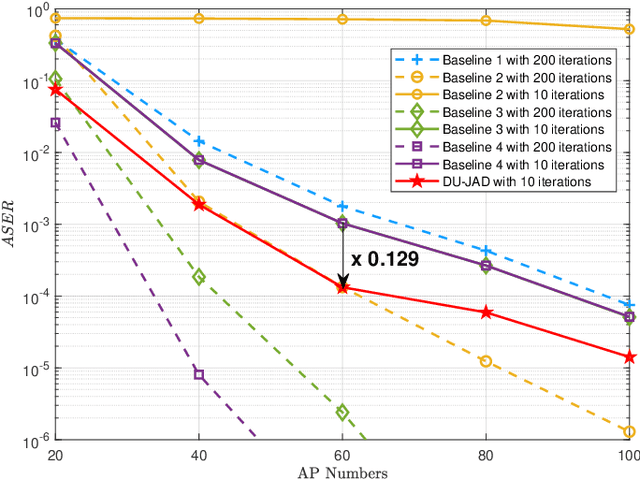
Massive grant-free transmission and cell-free wireless communication systems have emerged as pivotal enablers for massive machine-type communication. This paper proposes a deep-unfolding-based joint activity and data detection (DU-JAD) algorithm for massive grant-free transmission in cell-free systems. We first formulate a joint activity and data detection optimization problem, which we solve approximately using forward-backward splitting (FBS). We then apply deep unfolding to FBS to optimize algorithm parameters using machine learning. In order to improve data detection (DD) performance, reduce algorithm complexity, and enhance active user detection (AUD), we employ a momentum strategy, an approximate posterior mean estimator, and a novel soft-output AUD module, respectively. Simulation results confirm the efficacy of DU-JAD for AUD and DD.
Low-Complexity Channel Estimation for Extremely Large-Scale MIMO in Near Field
Dec 07, 2023



The extremely large-scale massive multiple-input multiple-output (XL-MIMO) has the potential to achieve boosted spectral efficiency and refined spatial resolution for future wireless networks. However, channel estimation for XL-MIMO is challenging since the large number of antennas results in high computational complexity with the near-field effect. In this letter, we propose a low-complexity sequential angle-distance channel estimation (SADCE) method for near-field XL-MIMO systems equipped with uniformly planar arrays (UPA). Specifically, we first successfully decouple the angle and distance parameters, which allows us to devise a two-dimensional discrete Fourier transform (2D-DFT) method for angle parameters estimation. Then, a low-complexity distance estimation method is proposed with a closed-form solution. Compared with existing methods, the proposed method achieves significant performance gain with noticeably reduced computational complexity.Numerical results verify the superiority of the proposed near-field channel estimation algorithm.
An HCAI Methodological Framework: Putting It Into Action to Enable Human-Centered AI
Nov 30, 2023Human-centered AI (HCAI), as a design philosophy, advocates prioritizing humans in designing, developing, and deploying intelligent systems, aiming to maximize the benefits of AI technology to humans and avoid its potential adverse effects. While HCAI has gained momentum, the lack of guidance on methodology in its implementation makes its adoption challenging. After assessing the needs for a methodological framework for HCAI, this paper first proposes a comprehensive and interdisciplinary HCAI methodological framework integrated with seven components, including design goals, design principles, implementation approaches, design paradigms, interdisciplinary teams, methods, and processes. THe implications of the framework are also discussed. This paper also presents a "three-layer" approach to facilitate the implementation of the framework. We believe the proposed framework is systematic and executable, which can overcome the weaknesses in current frameworks and the challenges currently faced in implementing HCAI. Thus, the framework can help put it into action to develop, transfer, and implement HCAI in practice, eventually enabling the design, development, and deployment of HCAI-based intelligent systems.
Wireless Network Digital Twin for 6G: Generative AI as A Key Enabler
Nov 29, 2023



Digital twin, which enables emulation, evaluation, and optimization of physical entities through synchronized digital replicas, has gained increasingly attention as a promising technology for intricate wireless networks. For 6G, numerous innovative wireless technologies and network architectures have posed new challenges in establishing wireless network digital twins. To tackle these challenges, artificial intelligence (AI), particularly the flourishing generative AI, emerges as a potential solution. In this article, we discuss emerging prerequisites for wireless network digital twins considering the complicated network architecture, tremendous network scale, extensive coverage, and diversified application scenarios in the 6G era. We further explore the applications of generative AI, such as transformer and diffusion model, to empower the 6G digital twin from multiple perspectives including implementation, physical-digital synchronization, and slicing capability. Subsequently, we propose a hierarchical generative AI-enabled wireless network digital twin at both the message-level and policy-level, and provide a typical use case with numerical results to validate the effectiveness and efficiency. Finally, open research issues for wireless network digital twins in the 6G era are discussed.
Knowledge Plugins: Enhancing Large Language Models for Domain-Specific Recommendations
Nov 16, 2023



The significant progress of large language models (LLMs) provides a promising opportunity to build human-like systems for various practical applications. However, when applied to specific task domains, an LLM pre-trained on a general-purpose corpus may exhibit a deficit or inadequacy in two types of domain-specific knowledge. One is a comprehensive set of domain data that is typically large-scale and continuously evolving. The other is specific working patterns of this domain reflected in the data. The absence or inadequacy of such knowledge impacts the performance of the LLM. In this paper, we propose a general paradigm that augments LLMs with DOmain-specific KnowledgE to enhance their performance on practical applications, namely DOKE. This paradigm relies on a domain knowledge extractor, working in three steps: 1) preparing effective knowledge for the task; 2) selecting the knowledge for each specific sample; and 3) expressing the knowledge in an LLM-understandable way. Then, the extracted knowledge is incorporated through prompts, without any computational cost of model fine-tuning. We instantiate the general paradigm on a widespread application, i.e. recommender systems, where critical item attributes and collaborative filtering signals are incorporated. Experimental results demonstrate that DOKE can substantially improve the performance of LLMs in specific domains.
Reducing Privacy Risks in Online Self-Disclosures with Language Models
Nov 16, 2023



Self-disclosure, while being common and rewarding in social media interaction, also poses privacy risks. In this paper, we take the initiative to protect the user-side privacy associated with online self-disclosure through identification and abstraction. We develop a taxonomy of 19 self-disclosure categories, and curate a large corpus consisting of 4.8K annotated disclosure spans. We then fine-tune a language model for identification, achieving over 75% in Token F$_1$. We further conduct a HCI user study, with 82\% of participants viewing the model positively, highlighting its real world applicability. Motivated by the user feedback, we introduce the task of self-disclosure abstraction. We experiment with both one-span abstraction and three-span abstraction settings, and explore multiple fine-tuning strategies. Our best model can generate diverse abstractions that moderately reduce privacy risks while maintaining high utility according to human evaluation.
Enabling Human-Centered AI: A Methodological Perspective
Nov 14, 2023Human-centered AI (HCAI) is a design philosophy that advocates prioritizing humans in designing, developing, and deploying intelligent systems, aiming to maximize the benefits of AI to humans and avoid potential adverse impacts. While HCAI continues to influence, the lack of guidance on methodology in practice makes its adoption challenging. This paper proposes a comprehensive HCAI framework based on our previous work with integrated components, including design goals, design principles, implementation approaches, interdisciplinary teams, HCAI methods, and HCAI processes. This paper also presents a "three-layer" approach to facilitate the implementation of the framework. We believe this systematic and executable framework can overcome the weaknesses in current HCAI frameworks and the challenges currently faced in practice, putting it into action to enable HCAI further.
Towards Foundation Models for Learning on Tabular Data
Oct 22, 2023



Learning on tabular data underpins numerous real-world applications. Despite considerable efforts in developing effective learning models for tabular data, current transferable tabular models remain in their infancy, limited by either the lack of support for direct instruction following in new tasks or the neglect of acquiring foundational knowledge and capabilities from diverse tabular datasets. In this paper, we propose Tabular Foundation Models (TabFMs) to overcome these limitations. TabFMs harness the potential of generative tabular learning, employing a pre-trained large language model (LLM) as the base model and fine-tuning it using purpose-designed objectives on an extensive range of tabular datasets. This approach endows TabFMs with a profound understanding and universal capabilities essential for learning on tabular data. Our evaluations underscore TabFM's effectiveness: not only does it significantly excel in instruction-following tasks like zero-shot and in-context inference, but it also showcases performance that approaches, and in instances, even transcends, the renowned yet mysterious closed-source LLMs like GPT-4. Furthermore, when fine-tuning with scarce data, our model achieves remarkable efficiency and maintains competitive performance with abundant training data. Finally, while our results are promising, we also delve into TabFM's limitations and potential opportunities, aiming to stimulate and expedite future research on developing more potent TabFMs.