 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Weighted Adversarial Nets for Partial Domain Adaptation
Mar 28, 2018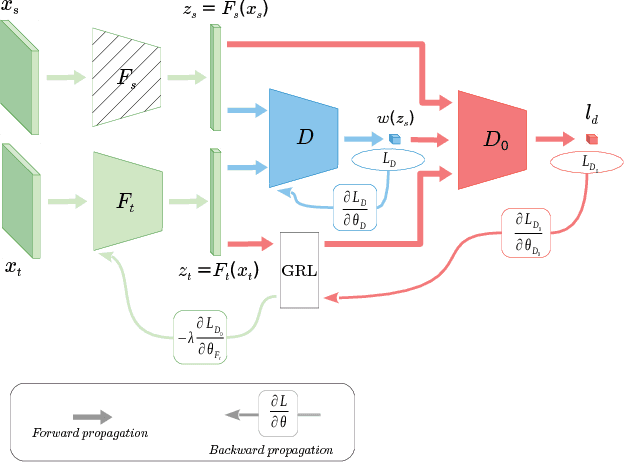
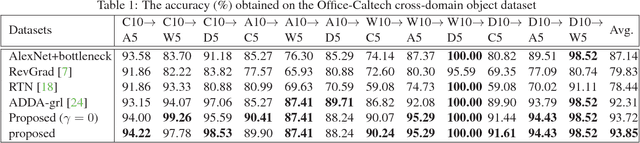

This paper proposes an importance weighted adversarial nets-based method for unsupervised domain adaptation, specific for partial domain adaptation where the target domain has less number of classes compared to the source domain. Previous domain adaptation methods generally assume the identical label spaces, such that reducing the distribution divergence leads to feasible knowledge transfer. However, such an assumption is no longer valid in a more realistic scenario that requires adaptation from a larger and more diverse source domain to a smaller target domain with less number of classes. This paper extends the adversarial nets-based domain adaptation and proposes a novel adversarial nets-based partial domain adaptation method to identify the source samples that are potentially from the outlier classes and, at the same time, reduce the shift of shared classes between domains.
Unsupervised Domain Adaptation: A Multi-task Learning-based Method
Mar 25, 2018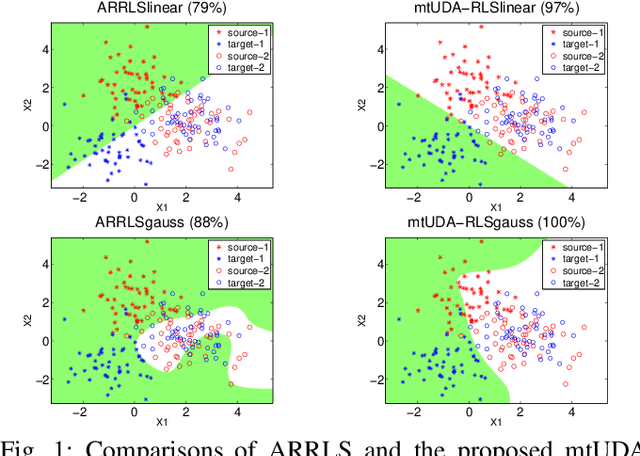
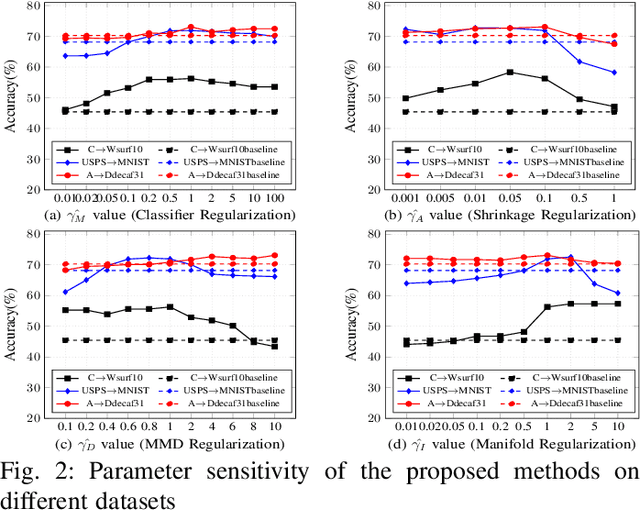
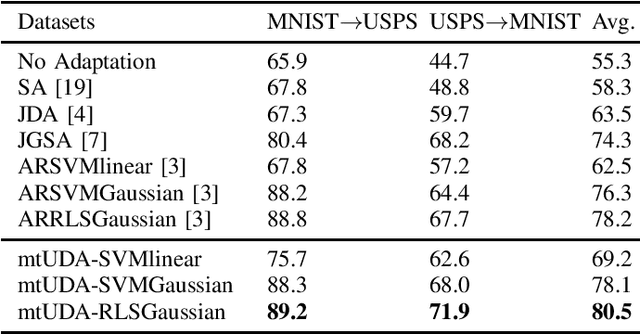
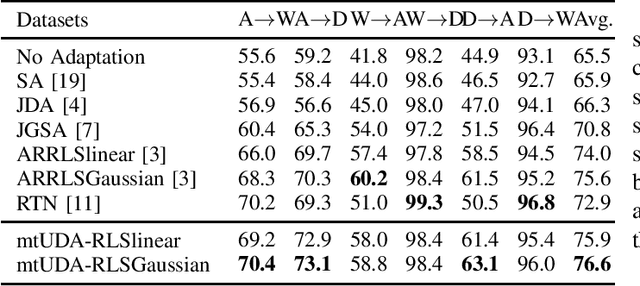
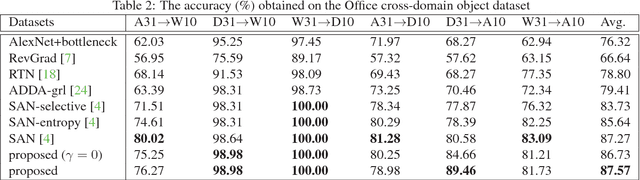
This paper presents a novel multi-task learning-based method for unsupervised domain adaptation. Specifically, the source and target domain classifiers are jointly learned by considering the geometry of target domain and the divergence between the source and target domains based on the concept of multi-task learning. Two novel algorithms are proposed upon the method using Regularized Least Squares and Support Vector Machines respectively. Experiments on both synthetic and real world cross domain recognition tasks have shown that the proposed methods outperform several state-of-the-art domain adaptation methods.
Cooperative Training of Deep Aggregation Networks for RGB-D Action Recognition
Dec 05, 2017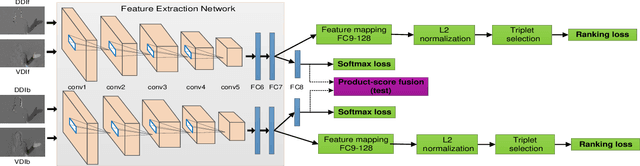
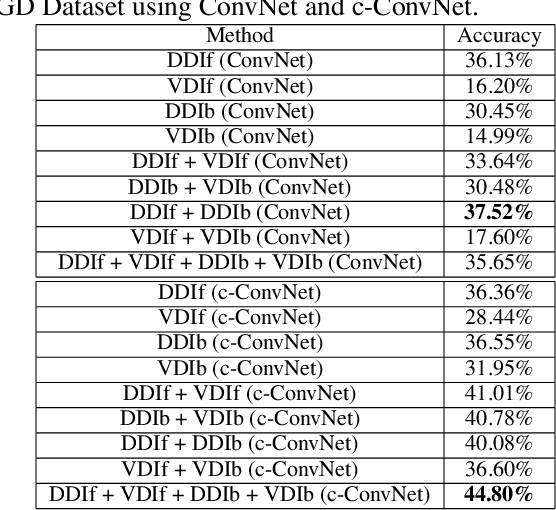


A novel deep neural network training paradigm that exploits the conjoint information in multiple heterogeneous sources is proposed. Specifically, in a RGB-D based action recognition task, it cooperatively trains a single convolutional neural network (named c-ConvNet) on both RGB visual features and depth features, and deeply aggregates the two kinds of features for action recognition. Differently from the conventional ConvNet that learns the deep separable features for homogeneous modality-based classification with only one softmax loss function, the c-ConvNet enhances the discriminative power of the deeply learned features and weakens the undesired modality discrepancy by jointly optimizing a ranking loss and a softmax loss for both homogeneous and heterogeneous modalities. The ranking loss consists of intra-modality and cross-modality triplet losses, and it reduces both the intra-modality and cross-modality feature variations. Furthermore, the correlations between RGB and depth data are embedded in the c-ConvNet, and can be retrieved by either of the modalities and contribute to the recognition in the case even only one of the modalities is available. The proposed method was extensively evaluated on two large RGB-D action recognition datasets, ChaLearn LAP IsoGD and NTU RGB+D datasets, and one small dataset, SYSU 3D HOI, and achieved state-of-the-art results.
Foreground Detection in Camouflaged Scenes
Jul 11, 2017
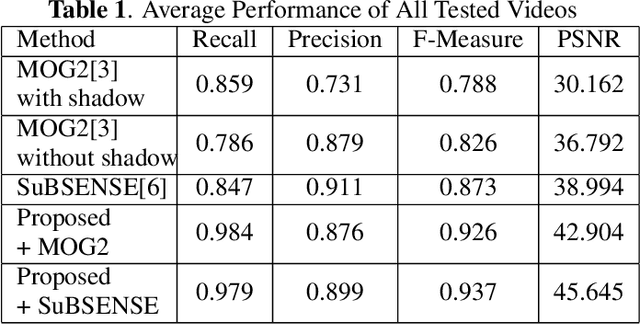

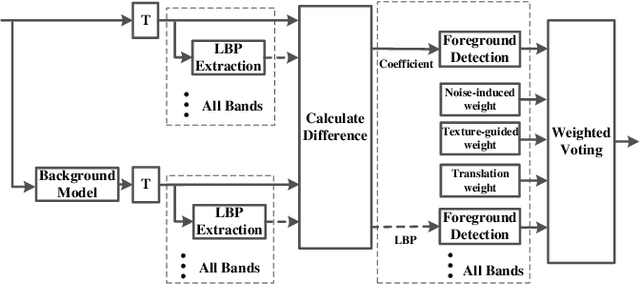
Foreground detection has been widely studied for decades due to its importance in many practical applications. Most of the existing methods assume foreground and background show visually distinct characteristics and thus the foreground can be detected once a good background model is obtained. However, there are many situations where this is not the case. Of particular interest in video surveillance is the camouflage case. For example, an active attacker camouflages by intentionally wearing clothes that are visually similar to the background. In such cases, even given a decent background model, it is not trivial to detect foreground objects. This paper proposes a texture guided weighted voting (TGWV) method which can efficiently detect foreground objects in camouflaged scenes. The proposed method employs the stationary wavelet transform to decompose the image into frequency bands. We show that the small and hardly noticeable differences between foreground and background in the image domain can be effectively captured in certain wavelet frequency bands. To make the final foreground decision, a weighted voting scheme is developed based on intensity and texture of all the wavelet bands with weights carefully designed. Experimental results demonstrate that the proposed method achieves superior performance compared to the current state-of-the-art results.
Online Action Recognition based on Incremental Learning of Weighted Covariance Descriptors
Jul 06, 2017
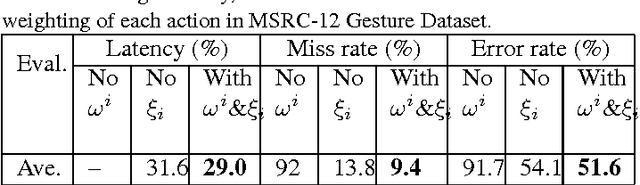
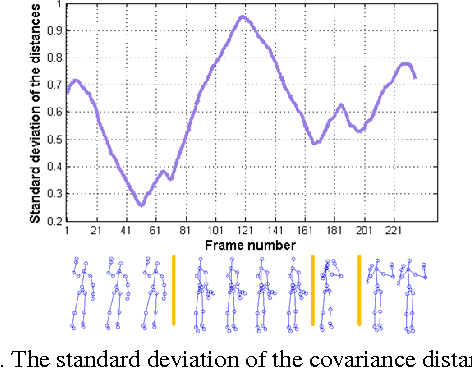
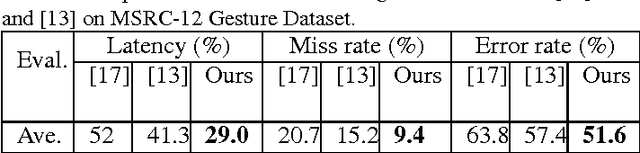
Different from traditional action recognition based on video segments, online action recognition aims to recognize actions from unsegmented streams of data in a continuous manner. One way for online recognition is based on the evidence accumulation over time to make predictions from stream videos. This paper presents a fast yet effective method to recognize actions from stream of noisy skeleton data, and a novel weighted covariance descriptor is adopted to accumulate evidence. In particular, a fast incremental updating method for the weighted covariance descriptor is developed for accumulation of temporal information and online prediction. The weighted covariance descriptor takes the following principles into consideration: past frames have less contribution for recognition and recent and informative frames such as key frames contribute more to the recognition. The online recognition is achieved using a simple nearest neighbor search against a set of offline trained action models. Experimental results on MSC-12 Kinect Gesture dataset and our newly constructed online action recognition dataset have demonstrated the efficacy of the proposed method.
Skeleton-based Action Recognition Using LSTM and CNN
Jul 06, 2017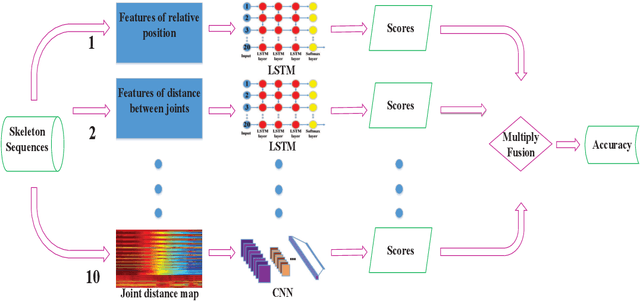
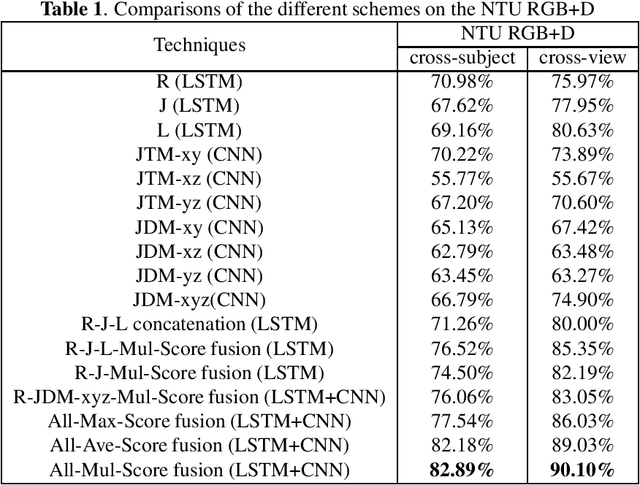
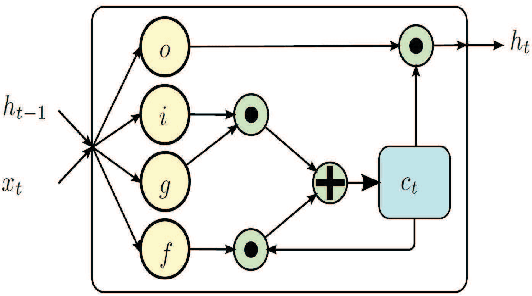
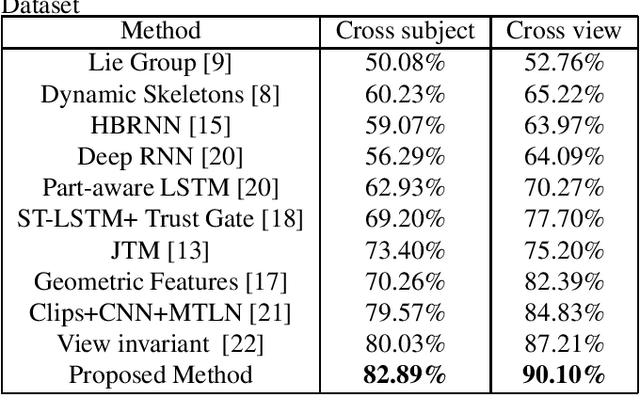
Recent methods based on 3D skeleton data have achieved outstanding performance due to its conciseness, robustness, and view-independent representation. With the development of deep learning, Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM)-based learning methods have achieved promising performance for action recognition. However, for CNN-based methods, it is inevitable to loss temporal information when a sequence is encoded into images. In order to capture as much spatial-temporal information as possible, LSTM and CNN are adopted to conduct effective recognition with later score fusion. In addition, experimental results show that the score fusion between CNN and LSTM performs better than that between LSTM and LSTM for the same feature. Our method achieved state-of-the-art results on NTU RGB+D datasets for 3D human action analysis. The proposed method achieved 87.40% in terms of accuracy and ranked $1^{st}$ place in Large Scale 3D Human Activity Analysis Challenge in Depth Videos.
Transfer Learning for Cross-Dataset Recognition: A Survey
Jul 06, 2017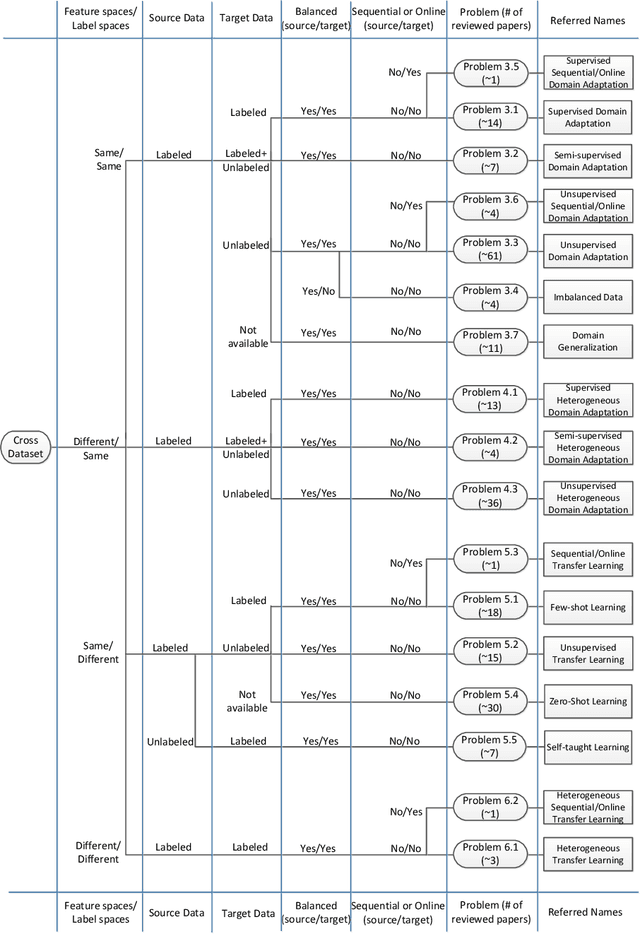
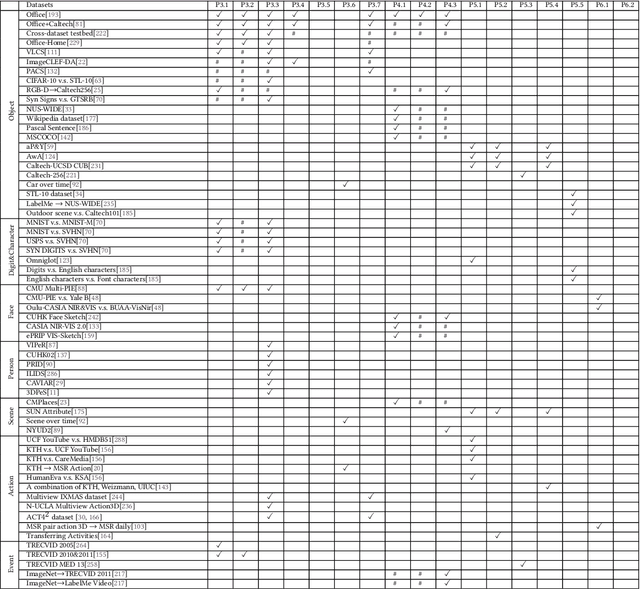
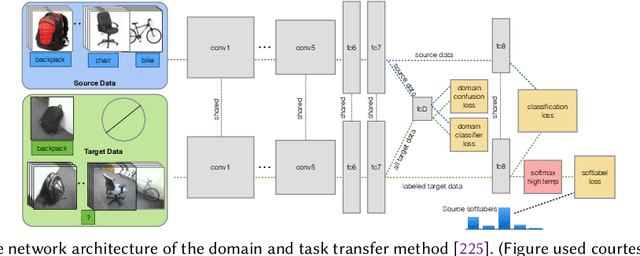
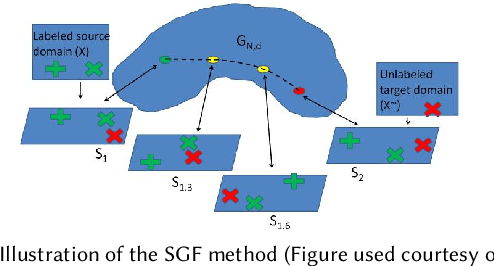
This paper summarises and analyses the cross-dataset recognition transfer learning techniques with the emphasis on what kinds of methods can be used when the available source and target data are presented in different forms for boosting the target task. This paper for the first time summarises several transferring criteria in details from the concept level, which are the key bases to guide what kind of knowledge to transfer between datasets. In addition, a taxonomy of cross-dataset scenarios and problems is proposed according the properties of data that define how different datasets are diverged, thereby review the recent advances on each specific problem under different scenarios. Moreover, some real world applications and corresponding commonly used benchmarks of cross-dataset recognition are reviewed. Lastly, several future directions are identified.
A Fully Trainable Network with RNN-based Pooling
Jun 16, 2017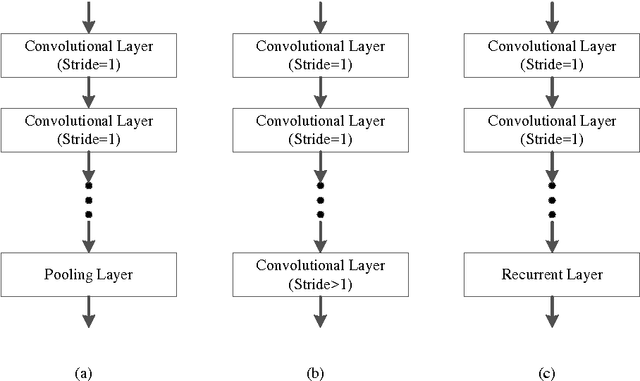
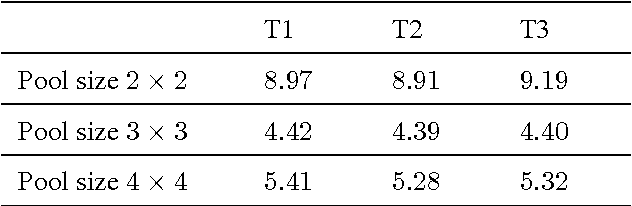
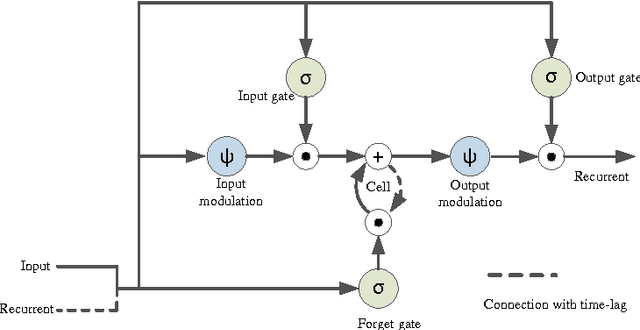
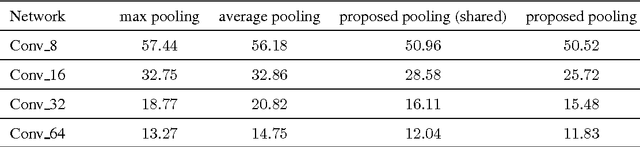
Pooling is an important component in convolutional neural networks (CNNs) for aggregating features and reducing computational burden. Compared with other components such as convolutional layers and fully connected layers which are completely learned from data, the pooling component is still handcrafted such as max pooling and average pooling. This paper proposes a learnable pooling function using recurrent neural networks (RNN) so that the pooling can be fully adapted to data and other components of the network, leading to an improved performance. Such a network with learnable pooling function is referred to as a fully trainable network (FTN). Experimental results have demonstrated that the proposed RNN-based pooling can well approximate the existing pooling functions and improve the performance of the network. Especially for small networks, the proposed FTN can improve the performance by seven percentage points in terms of error rate on the CIFAR-10 dataset compared with the traditional CNN.
Joint Geometrical and Statistical Alignment for Visual Domain Adaptation
May 16, 2017
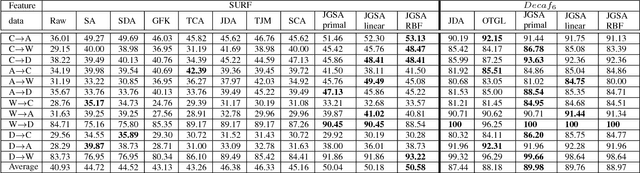
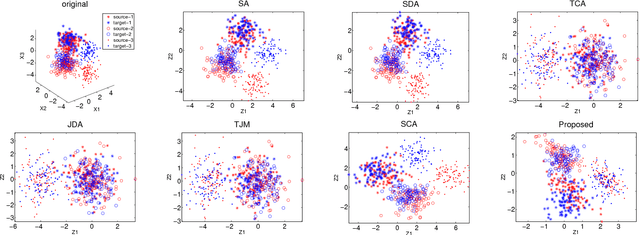

This paper presents a novel unsupervised domain adaptation method for cross-domain visual recognition. We propose a unified framework that reduces the shift between domains both statistically and geometrically, referred to as Joint Geometrical and Statistical Alignment (JGSA). Specifically, we learn two coupled projections that project the source domain and target domain data into low dimensional subspaces where the geometrical shift and distribution shift are reduced simultaneously. The objective function can be solved efficiently in a closed form. Extensive experiments have verified that the proposed method significantly outperforms several state-of-the-art domain adaptation methods on a synthetic dataset and three different real world cross-domain visual recognition tasks.
Investigation of Different Skeleton Features for CNN-based 3D Action Recognition
May 02, 2017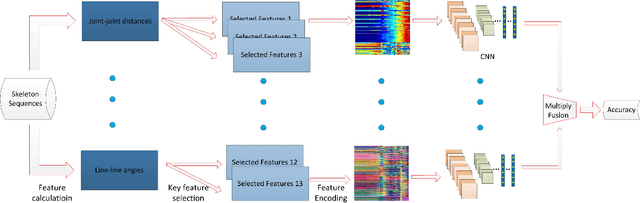
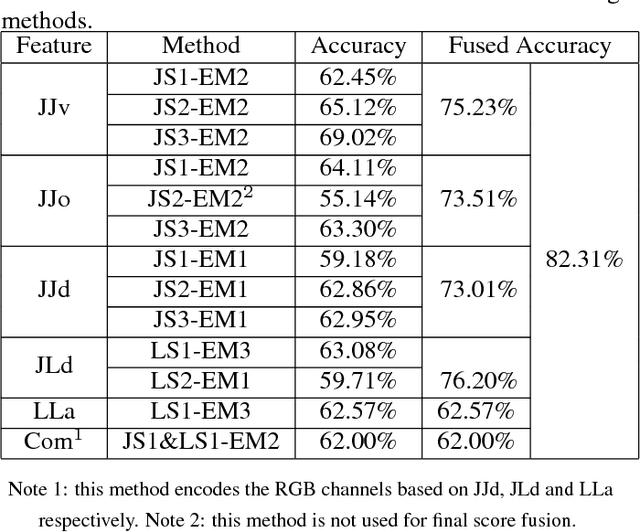
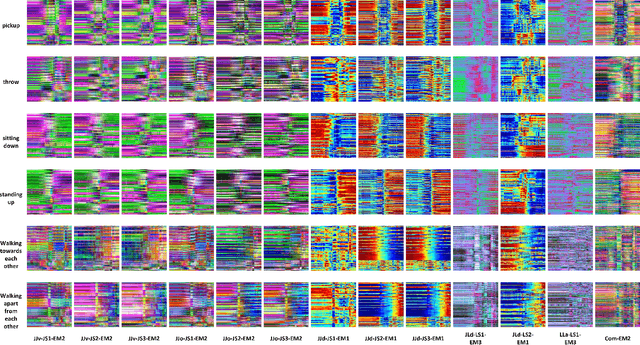
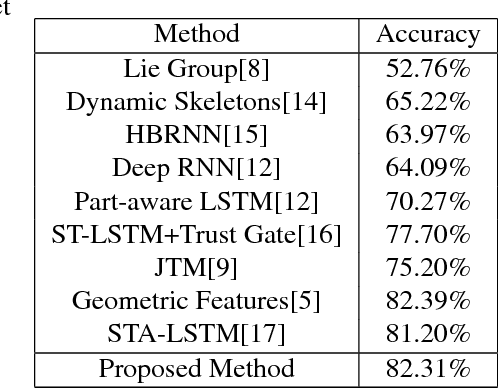
Deep learning techniques are being used in skeleton based action recognition tasks and outstanding performance has been reported. Compared with RNN based methods which tend to overemphasize temporal information, CNN-based approaches can jointly capture spatio-temporal information from texture color images encoded from skeleton sequences. There are several skeleton-based features that have proven effective in RNN-based and handcrafted-feature-based methods. However, it remains unknown whether they are suitable for CNN-based approaches. This paper proposes to encode five spatial skeleton features into images with different encoding methods. In addition, the performance implication of different joints used for feature extraction is studied. The proposed method achieved state-of-the-art performance on NTU RGB+D dataset for 3D human action analysis. An accuracy of 75.32\% was achieved in Large Scale 3D Human Activity Analysis Challenge in Depth Videos.