 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
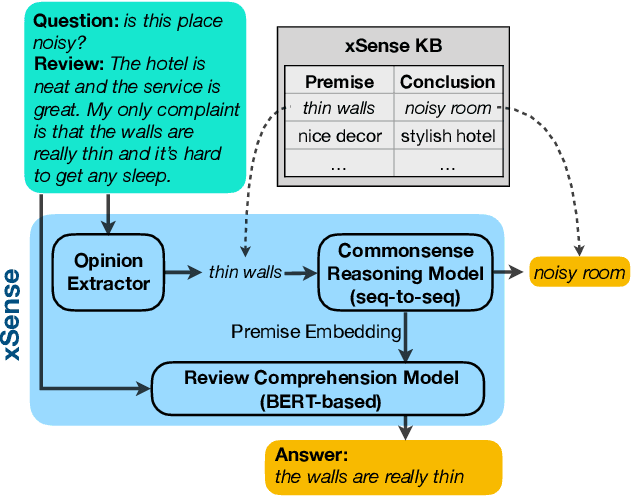
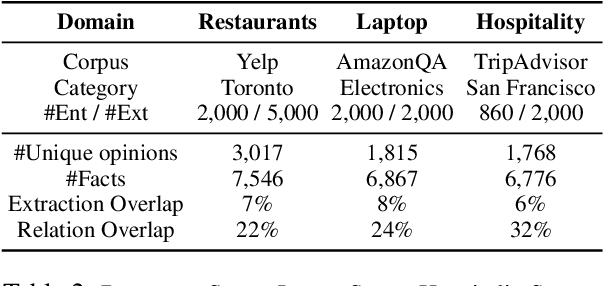
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.
Deep Entity Matching with Pre-Trained Language Models
Apr 01, 2020

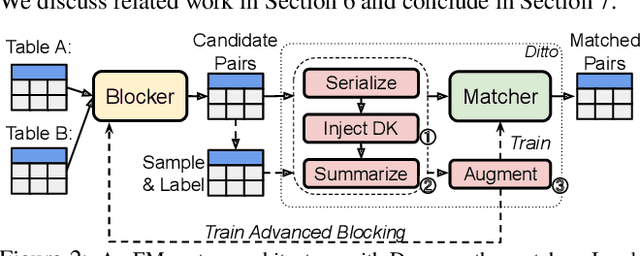

We present Ditto, a novel entity matching system based on pre-trained Transformer-based language models. We fine-tune and cast EM as a sequence-pair classification problem to leverage such models with a simple architecture. Our experiments show that a straightforward application of language models such as BERT, DistilBERT, or ALBERT pre-trained on large text corpora already significantly improves the matching quality and outperforms previous state-of-the-art (SOTA), by up to 19% of F1 score on benchmark datasets. We also developed three optimization techniques to further improve Ditto's matching capability. Ditto allows domain knowledge to be injected by highlighting important pieces of input information that may be of interest when making matching decisions. Ditto also summarizes strings that are too long so that only the essential information is retained and used for EM. Finally, Ditto adapts a SOTA technique on data augmentation for text to EM to augment the training data with (difficult) examples. This way, Ditto is forced to learn "harder" to improve the model's matching capability. The optimizations we developed further boost the performance of Ditto by up to 8.5%. Perhaps more surprisingly, we establish that Ditto can achieve the previous SOTA results with at most half the number of labeled data. Finally, we demonstrate Ditto's effectiveness on a real-world large-scale EM task. On matching two company datasets consisting of 789K and 412K records, Ditto achieves a high F1 score of 96.5%.
Snippext: Semi-supervised Opinion Mining with Augmented Data
Feb 07, 2020
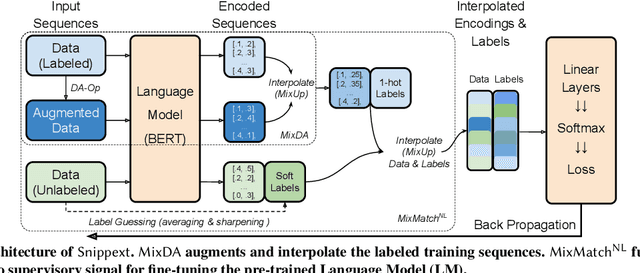
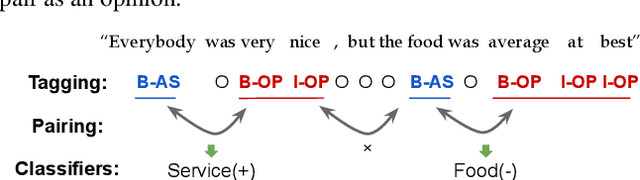
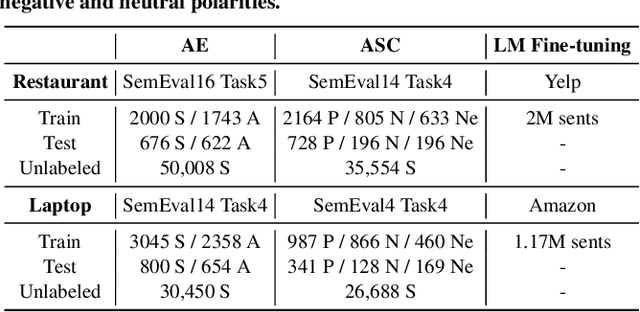
Online services are interested in solutions to opinion mining, which is the problem of extracting aspects, opinions, and sentiments from text. One method to mine opinions is to leverage the recent success of pre-trained language models which can be fine-tuned to obtain high-quality extractions from reviews. However, fine-tuning language models still requires a non-trivial amount of training data. In this paper, we study the problem of how to significantly reduce the amount of labeled training data required in fine-tuning language models for opinion mining. We describe Snippext, an opinion mining system developed over a language model that is fine-tuned through semi-supervised learning with augmented data. A novelty of Snippext is its clever use of a two-prong approach to achieve state-of-the-art (SOTA) performance with little labeled training data through: (1) data augmentation to automatically generate more labeled training data from existing ones, and (2) a semi-supervised learning technique to leverage the massive amount of unlabeled data in addition to the (limited amount of) labeled data. We show with extensive experiments that Snippext performs comparably and can even exceed previous SOTA results on several opinion mining tasks with only half the training data required. Furthermore, it achieves new SOTA results when all training data are leveraged. By comparison to a baseline pipeline, we found that Snippext extracts significantly more fine-grained opinions which enable new opportunities of downstream applications.
Teddy: A System for Interactive Review Analysis
Jan 15, 2020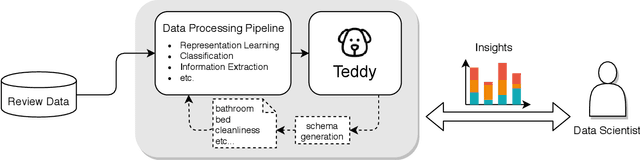

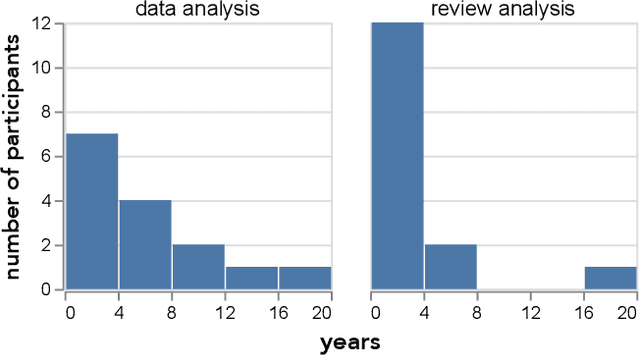
Reviews are integral to e-commerce services and products. They contain a wealth of information about the opinions and experiences of users, which can help better understand consumer decisions and improve user experience with products and services. Today, data scientists analyze reviews by developing rules and models to extract, aggregate, and understand information embedded in the review text. However, working with thousands of reviews, which are typically noisy incomplete text, can be daunting without proper tools. Here we first contribute results from an interview study that we conducted with fifteen data scientists who work with review text, providing insights into their practices and challenges. Results suggest data scientists need interactive systems for many review analysis tasks. In response we introduce Teddy, an interactive system that enables data scientists to quickly obtain insights from reviews and improve their extraction and modeling pipelines.
Sato: Contextual Semantic Type Detection in Tables
Nov 14, 2019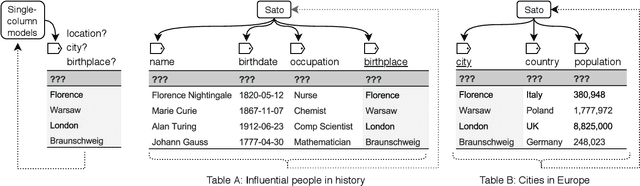

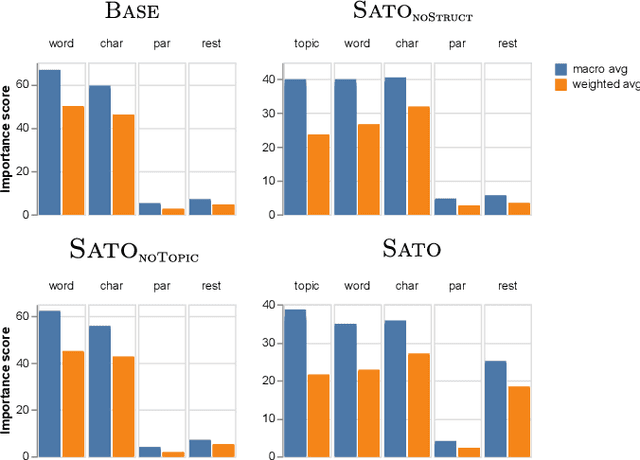
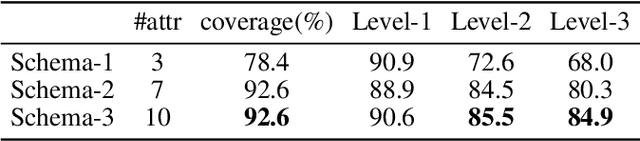
Detecting the semantic types of data columns in relational tables is important for various data preparation and information retrieval tasks such as data cleaning, schema matching, data discovery, and semantic search. However, existing detection approaches either perform poorly with dirty data, support only a limited number of semantic types, fail to incorporate the table context of columns or rely on large sample sizes in the training data. We introduce Sato, a hybrid machine learning model to automatically detect the semantic types of columns in tables, exploiting the signals from the context as well as the column values. Sato combines a deep learning model trained on a large-scale table corpus with topic modeling and structured prediction to achieve support-weighted and macro average F1 scores of 0.901 and 0.973, respectively, exceeding the state-of-the-art performance by a significant margin. We extensively analyze the overall and per-type performance of Sato, discussing how individual modeling components, as well as feature categories, contribute to its performance.
Essentia: Mining Domain-Specific Paraphrases with Word-Alignment Graphs
Oct 04, 2019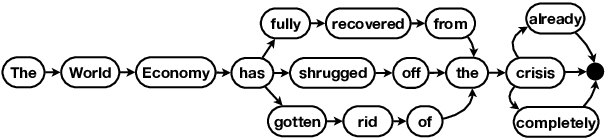



Paraphrases are important linguistic resources for a wide variety of NLP applications. Many techniques for automatic paraphrase mining from general corpora have been proposed. While these techniques are successful at discovering generic paraphrases, they often fail to identify domain-specific paraphrases (e.g., {staff, concierge} in the hospitality domain). This is because current techniques are often based on statistical methods, while domain-specific corpora are too small to fit statistical methods. In this paper, we present an unsupervised graph-based technique to mine paraphrases from a small set of sentences that roughly share the same topic or intent. Our system, Essentia, relies on word-alignment techniques to create a word-alignment graph that merges and organizes tokens from input sentences. The resulting graph is then used to generate candidate paraphrases. We demonstrate that our system obtains high-quality paraphrases, as evaluated by crowd workers. We further show that the majority of the identified paraphrases are domain-specific and thus complement existing paraphrase databases.
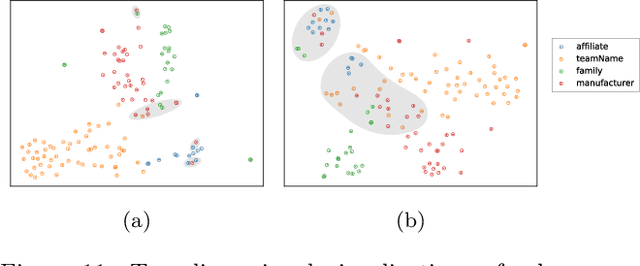
Emu: Enhancing Multilingual Sentence Embeddings with Semantic Specialization
Sep 15, 2019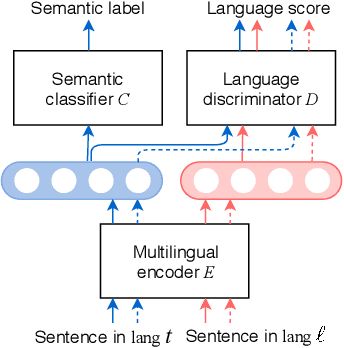
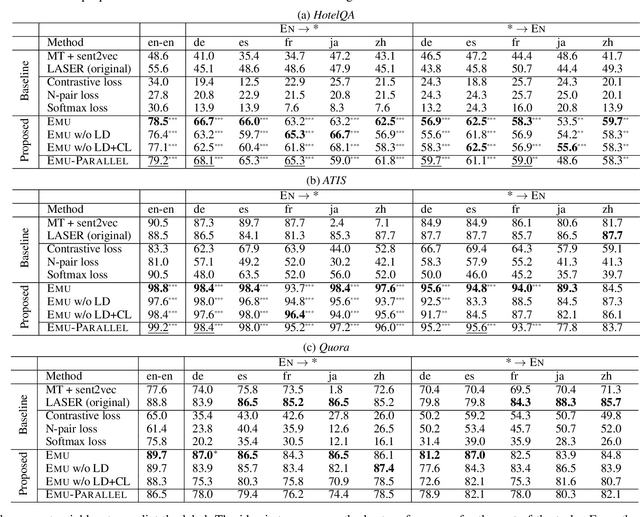
We present Emu, a system that semantically enhances multilingual sentence embeddings. Our framework fine-tunes pre-trained multilingual sentence embeddings using two main components: a semantic classifier and a language discriminator. The semantic classifier improves the semantic similarity of related sentences, whereas the language discriminator enhances the multilinguality of the embeddings via multilingual adversarial training. Our experimental results based on several language pairs show that our specialized embeddings outperform the state-of-the-art multilingual sentence embedding model on the task of cross-lingual intent classification using only monolingual labeled data.
Happiness Entailment: Automating Suggestions for Well-Being
Jul 23, 2019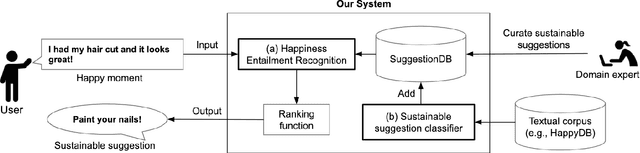

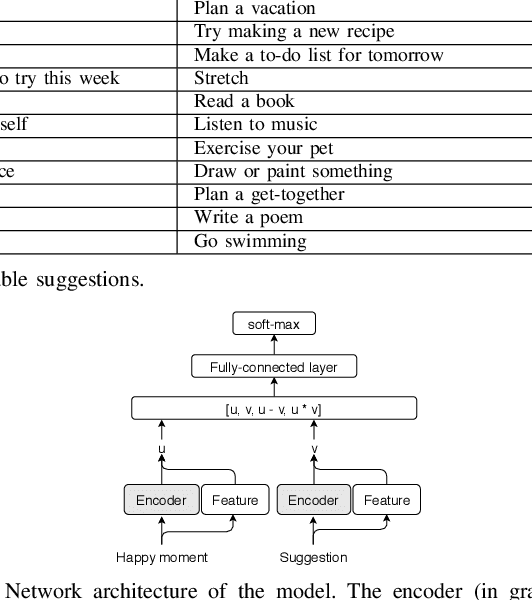
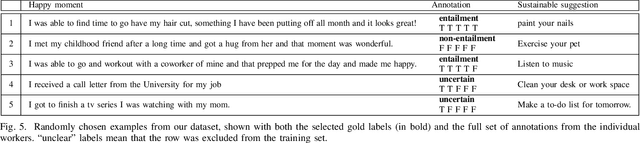
Understanding what makes people happy is a central topic in psychology. Prior work has mostly focused on developing self-reporting assessment tools for individuals and relies on experts to analyze the periodic reported assessments. One of the goals of the analysis is to understand what actions are necessary to encourage modifications in the behaviors of the individuals to improve their overall well-being. In this paper, we outline a complementary approach; on the assumption that the user journals her happy moments as short texts, a system can analyze these texts and propose sustainable suggestions for the user that may lead to an overall improvement in her well-being. We prototype one necessary component of such a system, the Happiness Entailment Recognition (HER) module, which takes as input a short text describing an event, a candidate suggestion, and outputs a determination about whether the suggestion is more likely to be good for this user based on the event described. This component is implemented as a neural network model with two encoders, one for the user input and one for the candidate actionable suggestion, with additional layers to capture psychologically significant features in the happy moment and suggestion.
Open Information Extraction from Question-Answer Pairs
Apr 06, 2019



Open Information Extraction (OpenIE) extracts meaningful structured tuples from free-form text. Most previous work on OpenIE considers extracting data from one sentence at a time. We describe NeurON, a system for extracting tuples from question-answer pairs. Since real questions and answers often contain precisely the information that users care about, such information is particularly desirable to extend a knowledge base with. NeurON addresses several challenges. First, an answer text is often hard to understand without knowing the question, and second, relevant information can span multiple sentences. To address these, NeurON formulates extraction as a multi-source sequence-to-sequence learning task, wherein it combines distributed representations of a question and an answer to generate knowledge facts. We describe experiments on two real-world datasets that demonstrate that NeurON can find a significant number of new and interesting facts to extend a knowledge base compared to state-of-the-art OpenIE methods.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019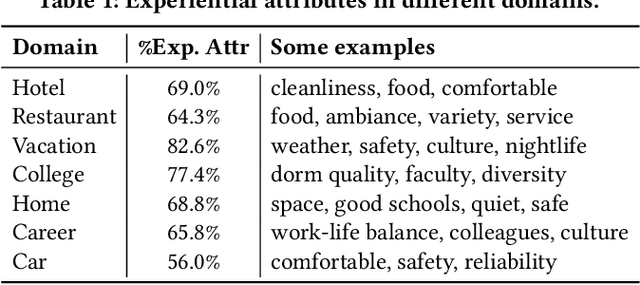
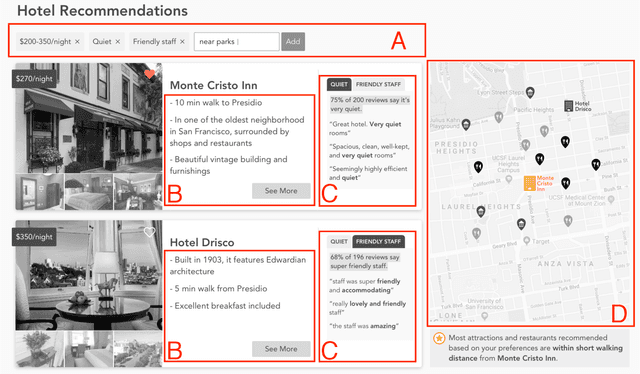
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.