 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is Undercover? Guiding LLMs to Explore Multi-Perspective Team Tactic in the Game
Oct 20, 2024



Large Language Models (LLMs) are pivotal AI agents in complex tasks but still face challenges in open decision-making problems within complex scenarios. To address this, we use the language logic game ``Who is Undercover?'' (WIU) as an experimental platform to propose the Multi-Perspective Team Tactic (MPTT) framework. MPTT aims to cultivate LLMs' human-like language expression logic, multi-dimensional thinking, and self-perception in complex scenarios. By alternating speaking and voting sessions, integrating techniques like self-perspective, identity-determination, self-reflection, self-summary and multi-round find-teammates, LLM agents make rational decisions through strategic concealment and communication, fostering human-like trust. Preliminary results show that MPTT, combined with WIU, leverages LLMs' cognitive capabilities to create a decision-making framework that can simulate real society. This framework aids minority groups in communication and expression, promoting fairness and diversity in decision-making. Additionally, our Human-in-the-loop experiments demonstrate that LLMs can learn and align with human behaviors through interactive, indicating their potential for active participation in societal decision-making.
Inferring Pitch from Coarse Spectral Features
Apr 10, 2022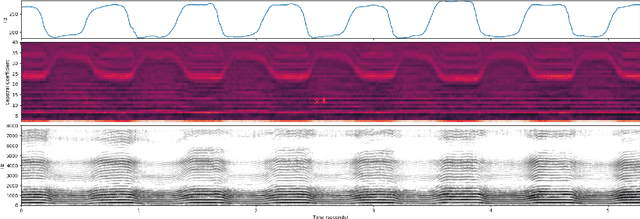
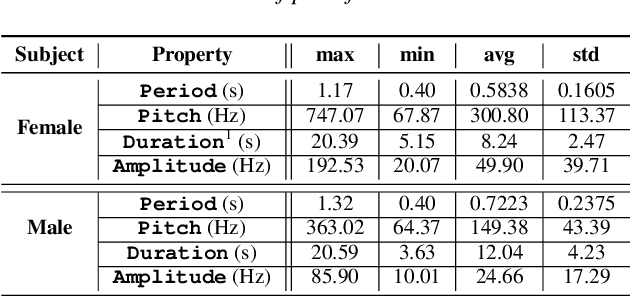
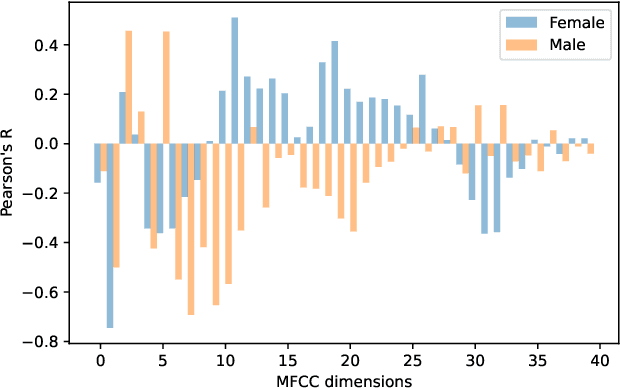
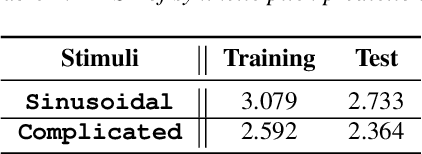
Fundamental frequency (F0) has long been treated as the physical definition of "pitch" in phonetic analysis. But there have been many demonstrations that F0 is at best an approximation to pitch, both in production and in perception: pitch is not F0, and F0 is not pitch. Changes in the pitch involve many articulatory and acoustic covariates; pitch perception often deviates from what F0 analysis predicts; and in fact, quasi-periodic signals from a single voice source are often incompletely characterized by an attempt to define a single time-varying F0. In this paper, we find strong support for the existence of covariates for pitch in aspects of relatively coarse spectra, in which an overtone series is not available. Thus linear regression can predict the pitch of simple vocalizations, produced by an articulatory synthesizer or by human, from single frames of such coarse spectra. Across speakers, and in more complex vocalizations, our experiments indicate that the covariates are not quite so simple, though apparently still available for more sophisticated modeling. On this basis, we propose that the field needs a better way of thinking about speech pitch, just as celestial mechanics requires us to go beyond Newton's point mass approximations to heavenly bodies.
Essentia: Mining Domain-Specific Paraphrases with Word-Alignment Graphs
Oct 04, 2019



Paraphrases are important linguistic resources for a wide variety of NLP applications. Many techniques for automatic paraphrase mining from general corpora have been proposed. While these techniques are successful at discovering generic paraphrases, they often fail to identify domain-specific paraphrases (e.g., {staff, concierge} in the hospitality domain). This is because current techniques are often based on statistical methods, while domain-specific corpora are too small to fit statistical methods. In this paper, we present an unsupervised graph-based technique to mine paraphrases from a small set of sentences that roughly share the same topic or intent. Our system, Essentia, relies on word-alignment techniques to create a word-alignment graph that merges and organizes tokens from input sentences. The resulting graph is then used to generate candidate paraphrases. We demonstrate that our system obtains high-quality paraphrases, as evaluated by crowd workers. We further show that the majority of the identified paraphrases are domain-specific and thus complement existing paraphrase databases.