 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Expert Alignment Is Hard: Evidence from Subjective Evaluation
May 06, 2026Aligning large language models with expert judgment is especially difficult in subjective evaluation tasks, where experts may disagree, rely on tacit criteria, and change their judgments over time. In this paper, we study expert alignment as a way to understand this difficulty. Using expert evaluations and follow-up questionnaires, we examine how different forms of expert information affect alignment and what this reveals about subjective judgment. Our findings show four consistent patterns. First, alignment difficulty varies substantially across experts, suggesting that expert evaluation styles differ widely in their distance from a model's prior behavior. Second, explicit criteria and reasoning do not always improve alignment, indicating that expert judgment is not fully captured by verbalized rules. Third, editing is sensitive to both the number and the identity of examples, with small numbers of edits providing useful but unstable gains. Fourth, alignment difficulty differs across evaluation dimensions: dimensions grounded more directly in proposal content are easier to align, while dimensions requiring external knowledge or value-based judgment remain harder. Taken together, these results suggest that expert alignment is difficult not only because of model limitations, but also because subjective evaluation is inherently heterogeneous, partly tacit, dimension-dependent, and temporally unstable.
Aggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
Emu: Enhancing Multilingual Sentence Embeddings with Semantic Specialization
Sep 15, 2019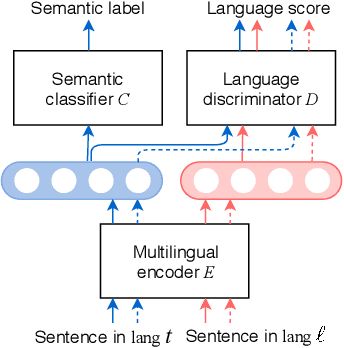
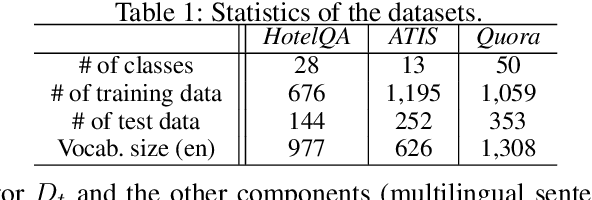
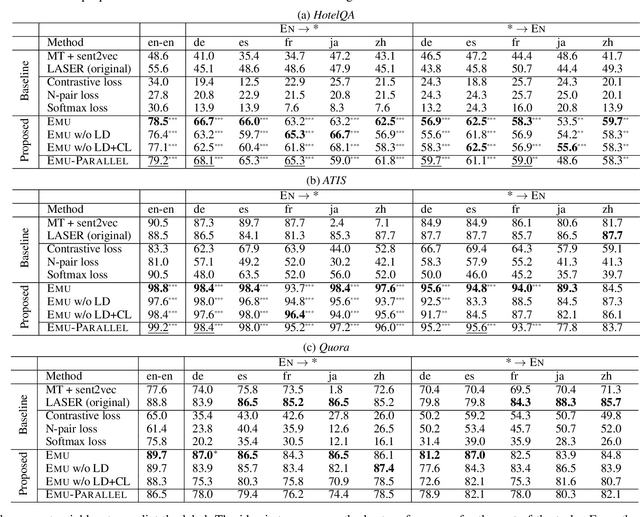
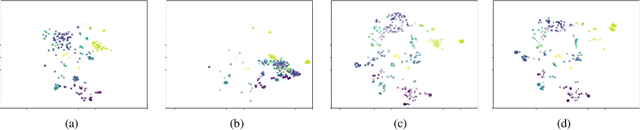
We present Emu, a system that semantically enhances multilingual sentence embeddings. Our framework fine-tunes pre-trained multilingual sentence embeddings using two main components: a semantic classifier and a language discriminator. The semantic classifier improves the semantic similarity of related sentences, whereas the language discriminator enhances the multilinguality of the embeddings via multilingual adversarial training. Our experimental results based on several language pairs show that our specialized embeddings outperform the state-of-the-art multilingual sentence embedding model on the task of cross-lingual intent classification using only monolingual labeled data.