 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Labeling Functions with Limited Labeled Data
May 29, 2025Programmatic weak supervision (PWS) significantly reduces human effort for labeling data by combining the outputs of user-provided labeling functions (LFs) on unlabeled datapoints. However, the quality of the generated labels depends directly on the accuracy of the LFs. In this work, we study the problem of fixing LFs based on a small set of labeled examples. Towards this goal, we develop novel techniques for repairing a set of LFs by minimally changing their results on the labeled examples such that the fixed LFs ensure that (i) there is sufficient evidence for the correct label of each labeled datapoint and (ii) the accuracy of each repaired LF is sufficiently high. We model LFs as conditional rules which enables us to refine them, i.e., to selectively change their output for some inputs. We demonstrate experimentally that our system improves the quality of LFs based on surprisingly small sets of labeled datapoints.
Snippext: Semi-supervised Opinion Mining with Augmented Data
Feb 07, 2020
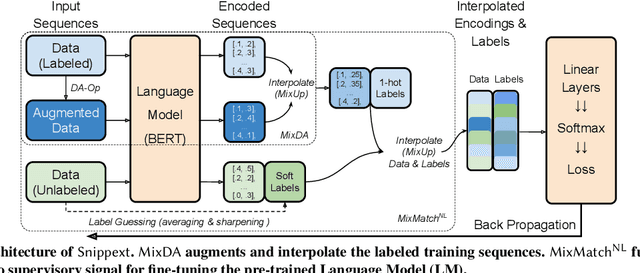
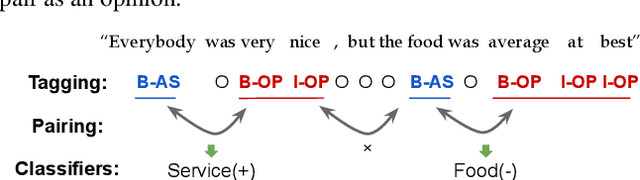
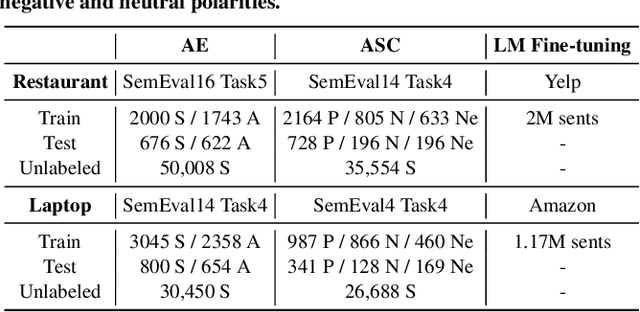
Online services are interested in solutions to opinion mining, which is the problem of extracting aspects, opinions, and sentiments from text. One method to mine opinions is to leverage the recent success of pre-trained language models which can be fine-tuned to obtain high-quality extractions from reviews. However, fine-tuning language models still requires a non-trivial amount of training data. In this paper, we study the problem of how to significantly reduce the amount of labeled training data required in fine-tuning language models for opinion mining. We describe Snippext, an opinion mining system developed over a language model that is fine-tuned through semi-supervised learning with augmented data. A novelty of Snippext is its clever use of a two-prong approach to achieve state-of-the-art (SOTA) performance with little labeled training data through: (1) data augmentation to automatically generate more labeled training data from existing ones, and (2) a semi-supervised learning technique to leverage the massive amount of unlabeled data in addition to the (limited amount of) labeled data. We show with extensive experiments that Snippext performs comparably and can even exceed previous SOTA results on several opinion mining tasks with only half the training data required. Furthermore, it achieves new SOTA results when all training data are leveraged. By comparison to a baseline pipeline, we found that Snippext extracts significantly more fine-grained opinions which enable new opportunities of downstream applications.