 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFostering Generalization in Single-view 3D Reconstruction by Learning a Hierarchy of Local and Global Shape Priors
Apr 01, 2021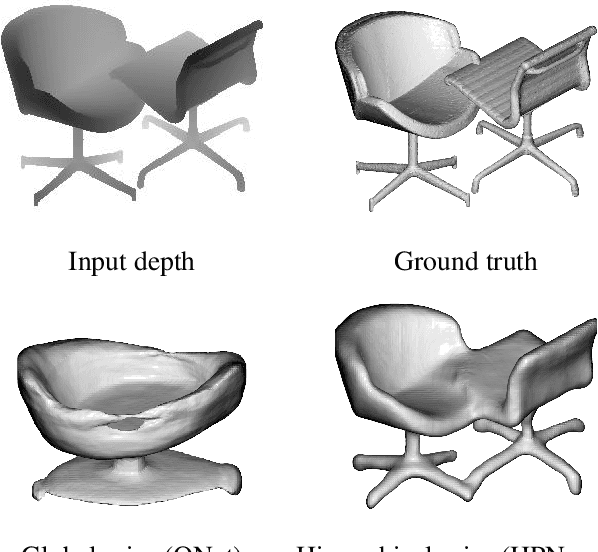
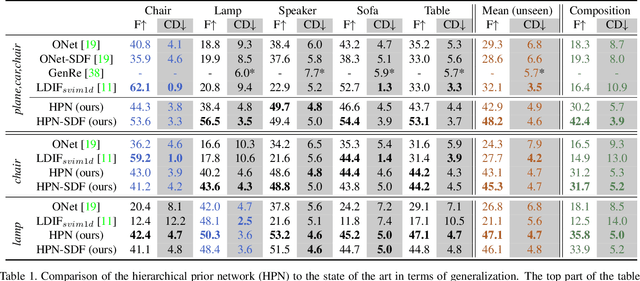
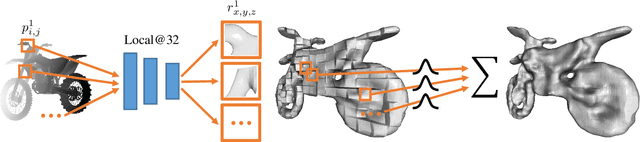
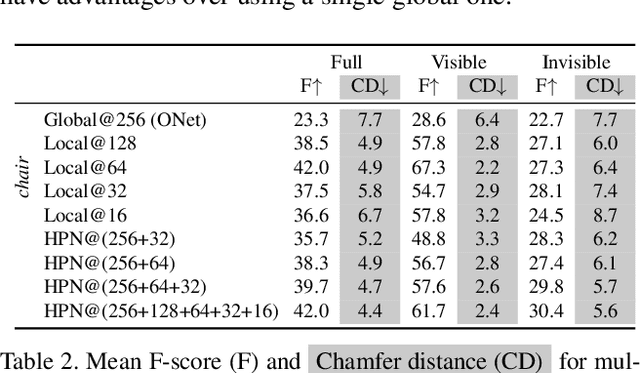
Single-view 3D object reconstruction has seen much progress, yet methods still struggle generalizing to novel shapes unseen during training. Common approaches predominantly rely on learned global shape priors and, hence, disregard detailed local observations. In this work, we address this issue by learning a hierarchy of priors at different levels of locality from ground truth input depth maps. We argue that exploiting local priors allows our method to efficiently use input observations, thus improving generalization in visible areas of novel shapes. At the same time, the combination of local and global priors enables meaningful hallucination of unobserved parts resulting in consistent 3D shapes. We show that the hierarchical approach generalizes much better than the global approach. It generalizes not only between different instances of a class but also across classes and to unseen arrangements of objects.
EML System Description for VoxCeleb Speaker Diarization Challenge 2020
Oct 23, 2020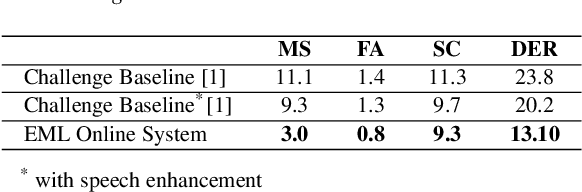
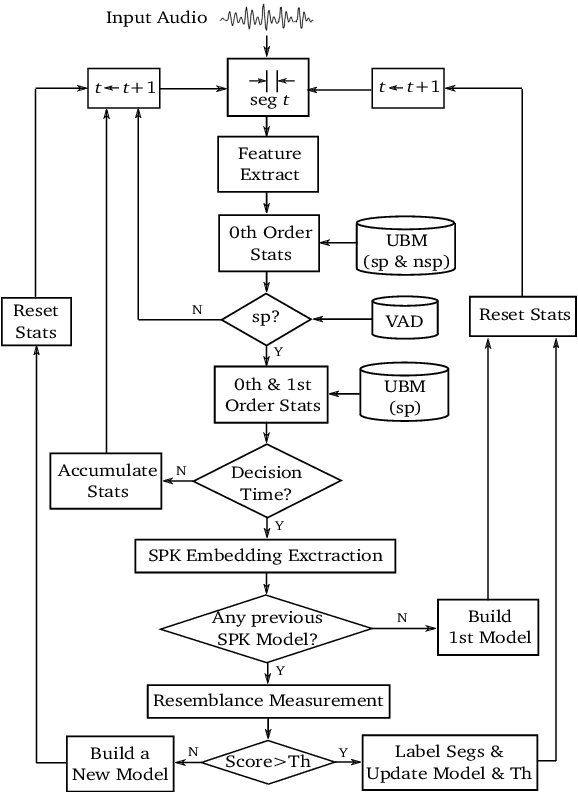
This technical report describes the EML submission to the first VoxCeleb speaker diarization challenge. Although the aim of the challenge has been the offline processing of the signals, the submitted system is basically the EML online algorithm which decides about the speaker labels in runtime approximately every 1.2 sec. For the first phase of the challenge, only VoxCeleb2 dev dataset was used for training. The results on the provided VoxConverse dev set show much better accuracy in terms of both DER and JER compared to the offline baseline provided in the challenge. The real-time factor of the whole diarization process is about 0.01 using a single CPU machine.
SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks
Jun 22, 2020
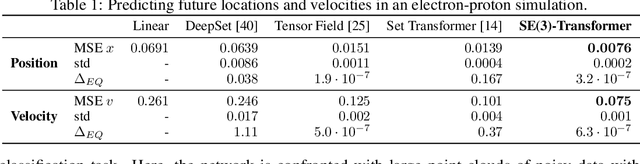
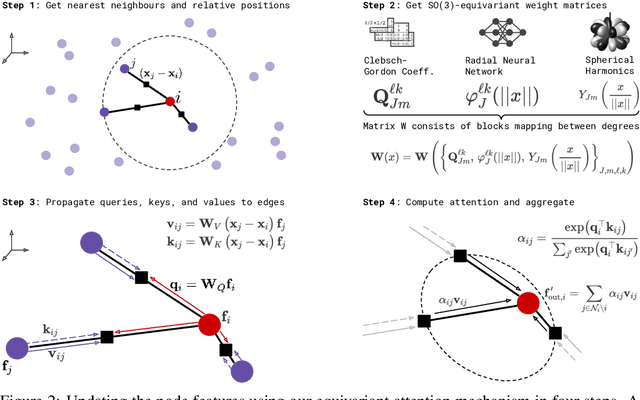

We introduce the SE(3)-Transformer, a variant of the self-attention module for 3D point clouds, which is equivariant under continuous 3D roto-translations. Equivariance is important to ensure stable and predictable performance in the presence of nuisance transformations of the data input. A positive corollary of equivariance is increased weight-tying within the model, leading to fewer trainable parameters and thus decreased sample complexity (i.e. we need less training data). The SE(3)-Transformer leverages the benefits of self-attention to operate on large point clouds with varying number of points, while guaranteeing SE(3)-equivariance for robustness. We evaluate our model on a toy $N$-body particle simulation dataset, showcasing the robustness of the predictions under rotations of the input. We further achieve competitive performance on two real-world datasets, ScanObjectNN and QM9. In all cases, our model outperforms a strong, non-equivariant attention baseline and an equivariant model without attention.
Group Pruning using a Bounded-Lp norm for Group Gating and Regularization
Aug 09, 2019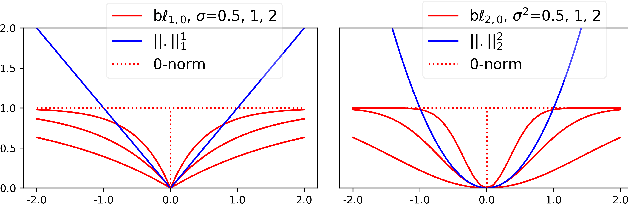
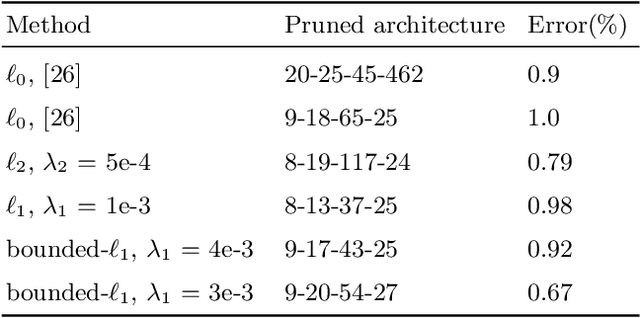
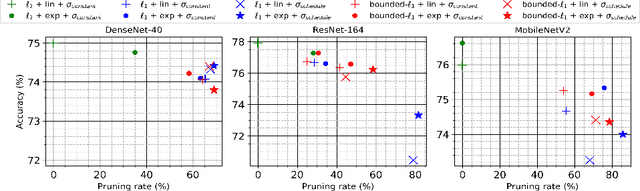
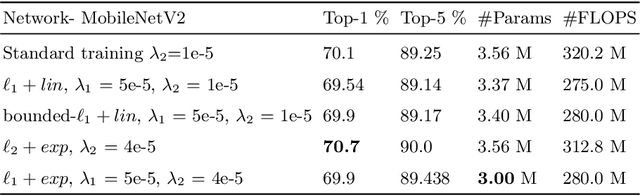
Deep neural networks achieve state-of-the-art results on several tasks while increasing in complexity. It has been shown that neural networks can be pruned during training by imposing sparsity inducing regularizers. In this paper, we investigate two techniques for group-wise pruning during training in order to improve network efficiency. We propose a gating factor after every convolutional layer to induce channel level sparsity, encouraging insignificant channels to become exactly zero. Further, we introduce and analyse a bounded variant of the L1 regularizer, which interpolates between L1 and L0-norms to retain performance of the network at higher pruning rates. To underline effectiveness of the proposed methods,we show that the number of parameters of ResNet-164, DenseNet-40 and MobileNetV2 can be reduced down by 30%, 69% and 75% on CIFAR100 respectively without a significant drop in accuracy. We achieve state-of-the-art pruning results for ResNet-50 with higher accuracy on ImageNet. Furthermore, we show that the light weight MobileNetV2 can further be compressed on ImageNet without a significant drop in performance.
Grid Saliency for Context Explanations of Semantic Segmentation
Jul 30, 2019
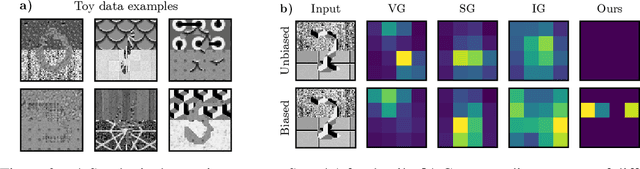
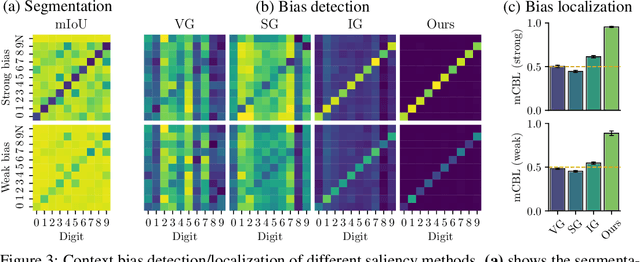
Recently, there has been a growing interest in developing saliency methods that provide visual explanations of network predictions. Still, the usability of existing methods is limited to image classification models. To overcome this limitation, we extend the existing approaches to generate grid saliencies, which provide spatially coherent visual explanations for (pixel-level) dense prediction networks. As the proposed grid saliency allows to spatially disentangle the object and its context, we specifically explore its potential to produce context explanations for semantic segmentation networks, discovering which context most influences the class predictions inside a target object area. We investigate the effectiveness of grid saliency on a synthetic dataset with an artificially induced bias between objects and their context as well as on the real-world Cityscapes dataset using state-of-the-art segmentation networks. Our results show that grid saliency can be successfully used to provide easily interpretable context explanations and, moreover, can be employed for detecting and localizing contextual biases present in the data.
Short-Term Prediction and Multi-Camera Fusion on Semantic Grids
Mar 21, 2019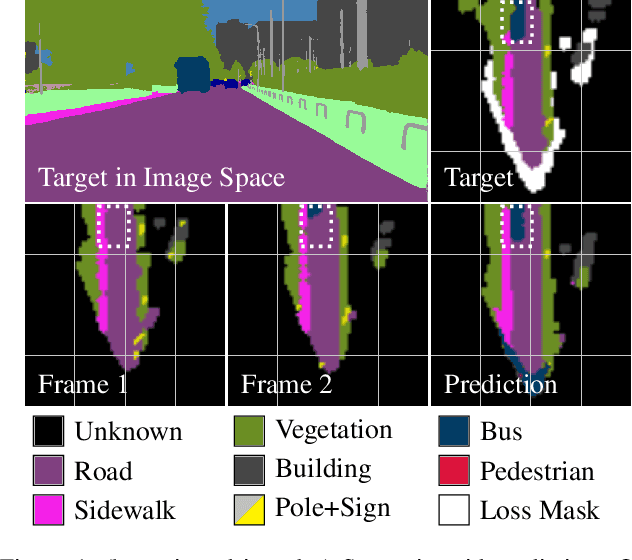
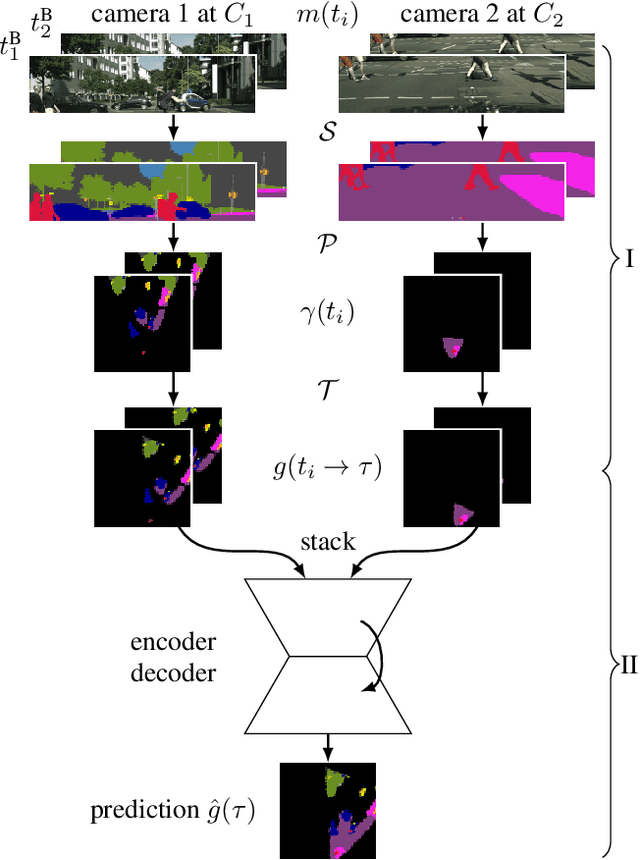
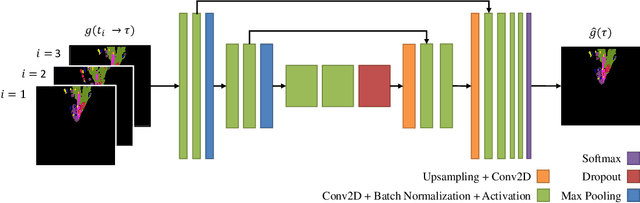

An environment representation (ER) is a substantial part of every autonomous system. It introduces a common interface between perception and other system components, such as decision making, and allows downstream algorithms to deal with abstracted data without knowledge of the used sensor. In this work, we propose and evaluate a novel architecture that generates an egocentric, grid-based, predictive, and semantically-interpretable ER. In particular, we provide a proof of concept for the spatio-temporal fusion of multiple camera sequences and short-term prediction in such an ER. Our design utilizes a strong semantic segmentation network together with depth and egomotion estimates to first extract semantic information from multiple camera streams and then transform these separately into egocentric temporally-aligned bird's-eye view grids. A deep encoder-decoder network is trained to fuse a stack of these grids into a unified semantic grid representation and to predict the dynamics of its surrounding. We evaluate this representation on real-world sequences of the Cityscapes dataset and show that our architecture can make accurate predictions in complex sensor fusion scenarios and significantly outperforms a model-driven baseline in a category-based evaluation.
The streaming rollout of deep networks - towards fully model-parallel execution
Nov 02, 2018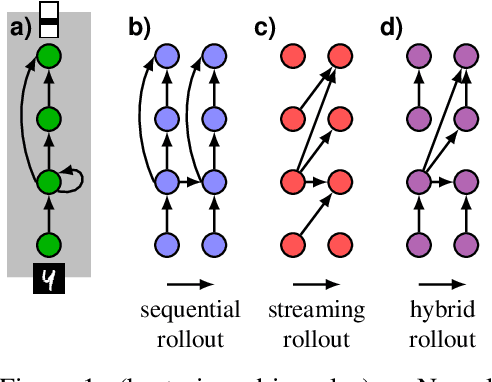
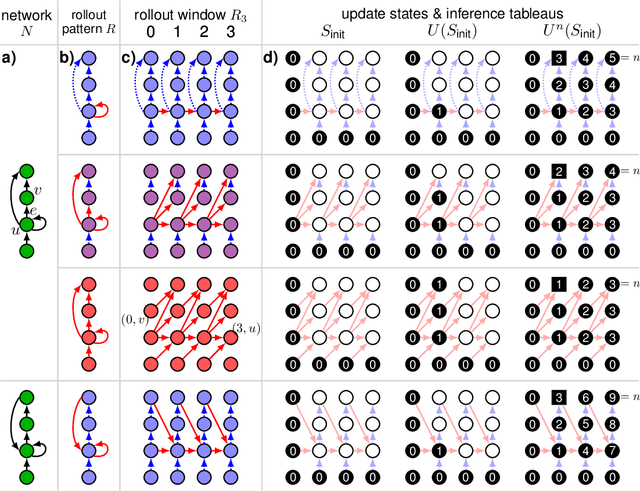
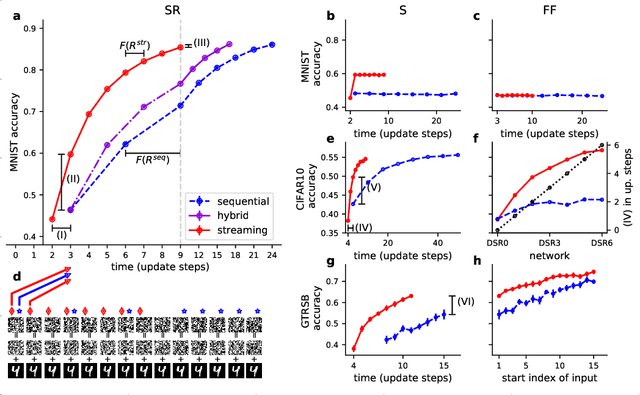
Deep neural networks, and in particular recurrent networks, are promising candidates to control autonomous agents that interact in real-time with the physical world. However, this requires a seamless integration of temporal features into the network's architecture. For the training of and inference with recurrent neural networks, they are usually rolled out over time, and different rollouts exist. Conventionally during inference, the layers of a network are computed in a sequential manner resulting in sparse temporal integration of information and long response times. In this study, we present a theoretical framework to describe rollouts, the level of model-parallelization they induce, and demonstrate differences in solving specific tasks. We prove that certain rollouts, also for networks with only skip and no recurrent connections, enable earlier and more frequent responses, and show empirically that these early responses have better performance. The streaming rollout maximizes these properties and enables a fully parallel execution of the network reducing runtime on massively parallel devices. Finally, we provide an open-source toolbox to design, train, evaluate, and interact with streaming rollouts.
Functionally Modular and Interpretable Temporal Filtering for Robust Segmentation
Oct 15, 2018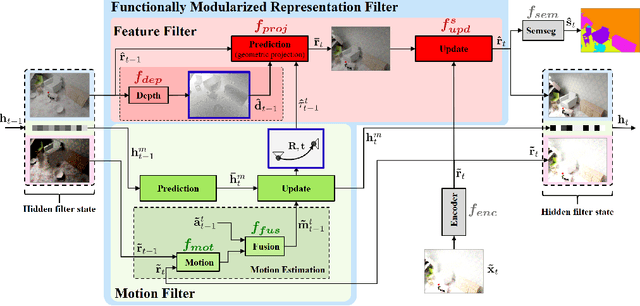


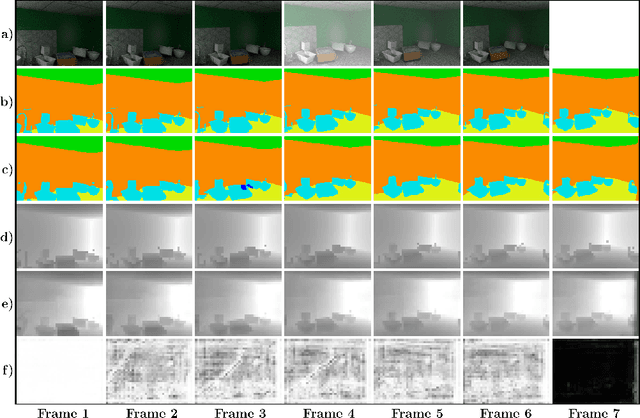
The performance of autonomous systems heavily relies on their ability to generate a robust representation of the environment. Deep neural networks have greatly improved vision-based perception systems but still fail in challenging situations, e.g. sensor outages or heavy weather. These failures are often introduced by data-inherent perturbations, which significantly reduce the information provided to the perception system. We propose a functionally modularized temporal filter, which stabilizes an abstract feature representation of a single-frame segmentation model using information of previous time steps. Our filter module splits the filter task into multiple less complex and more interpretable subtasks. The basic structure of the filter is inspired by a Bayes estimator consisting of a prediction and an update step. To make the prediction more transparent, we implement it using a geometric projection and estimate its parameters. This additionally enables the decomposition of the filter task into static representation filtering and low-dimensional motion filtering. Our model can cope with missing frames and is trainable in an end-to-end fashion. Using photorealistic, synthetic video data, we show the ability of the proposed architecture to overcome data-inherent perturbations. The experiments especially highlight advantages introduced by an interpretable and explicit filter module.
Universal Adversarial Perturbations Against Semantic Image Segmentation
Jul 31, 2017



While deep learning is remarkably successful on perceptual tasks, it was also shown to be vulnerable to adversarial perturbations of the input. These perturbations denote noise added to the input that was generated specifically to fool the system while being quasi-imperceptible for humans. More severely, there even exist universal perturbations that are input-agnostic but fool the network on the majority of inputs. While recent work has focused on image classification, this work proposes attacks against semantic image segmentation: we present an approach for generating (universal) adversarial perturbations that make the network yield a desired target segmentation as output. We show empirically that there exist barely perceptible universal noise patterns which result in nearly the same predicted segmentation for arbitrary inputs. Furthermore, we also show the existence of universal noise which removes a target class (e.g., all pedestrians) from the segmentation while leaving the segmentation mostly unchanged otherwise.
Adversarial Examples for Semantic Image Segmentation
Mar 03, 2017
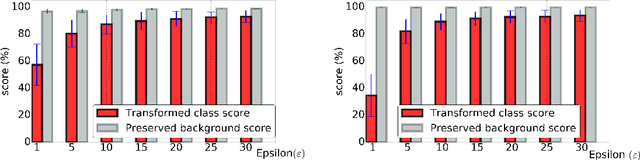
Machine learning methods in general and Deep Neural Networks in particular have shown to be vulnerable to adversarial perturbations. So far this phenomenon has mainly been studied in the context of whole-image classification. In this contribution, we analyse how adversarial perturbations can affect the task of semantic segmentation. We show how existing adversarial attackers can be transferred to this task and that it is possible to create imperceptible adversarial perturbations that lead a deep network to misclassify almost all pixels of a chosen class while leaving network prediction nearly unchanged outside this class.