 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability Metrics for Selecting Source Model Ensembles
Nov 25, 2021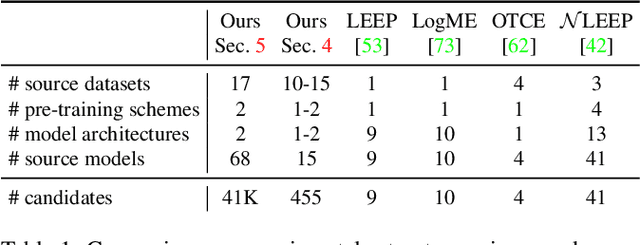
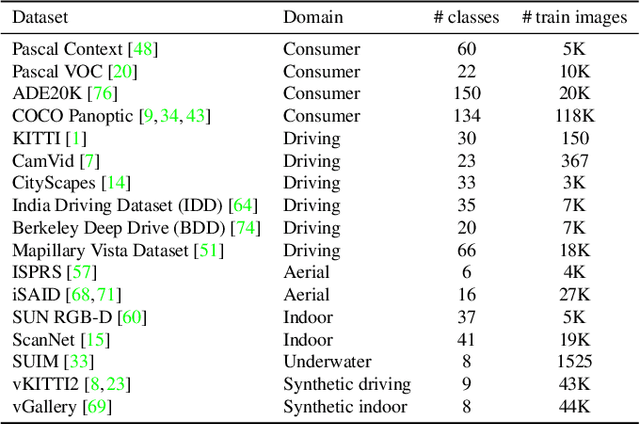
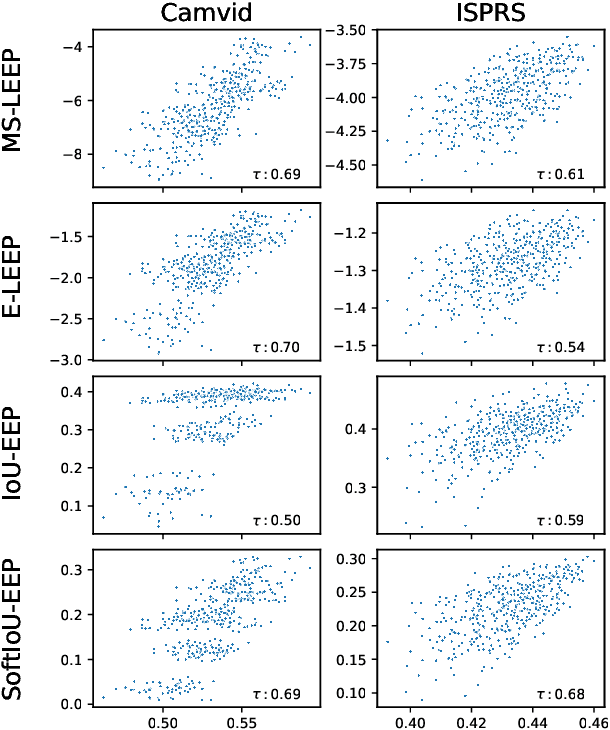
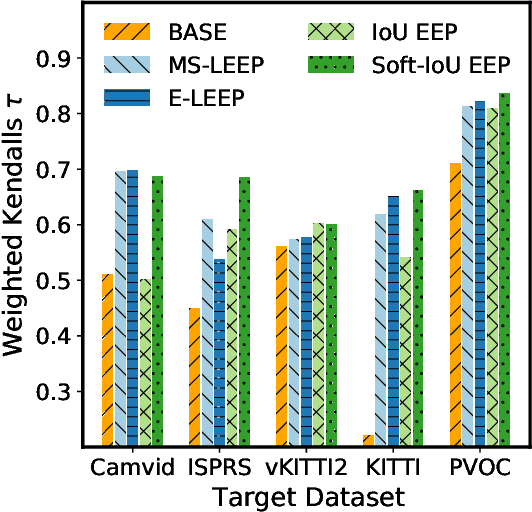
We address the problem of ensemble selection in transfer learning: Given a large pool of source models we want to select an ensemble of models which, after fine-tuning on the target training set, yields the best performance on the target test set. Since fine-tuning all possible ensembles is computationally prohibitive, we aim at predicting performance on the target dataset using a computationally efficient transferability metric. We propose several new transferability metrics designed for this task and evaluate them in a challenging and realistic transfer learning setup for semantic segmentation: we create a large and diverse pool of source models by considering 17 source datasets covering a wide variety of image domain, two different architectures, and two pre-training schemes. Given this pool, we then automatically select a subset to form an ensemble performing well on a given target dataset. We compare the ensemble selected by our method to two baselines which select a single source model, either (1) from the same pool as our method; or (2) from a pool containing large source models, each with similar capacity as an ensemble. Averaged over 17 target datasets, we outperform these baselines by 6.0% and 2.5% relative mean IoU, respectively.
Transferability Estimation using Bhattacharyya Class Separability
Nov 24, 2021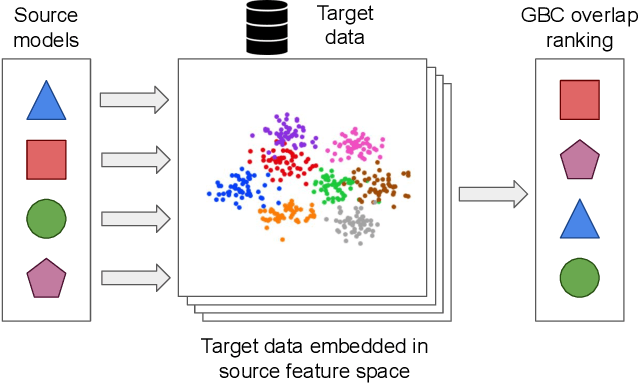

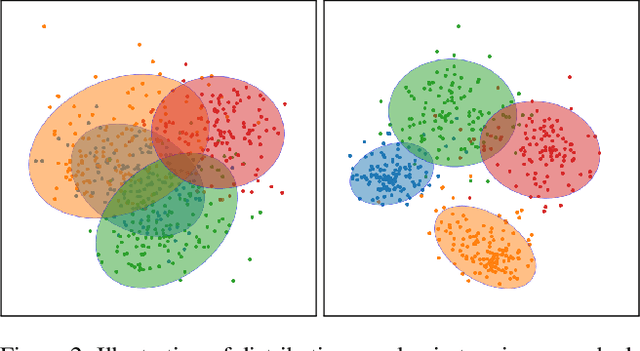
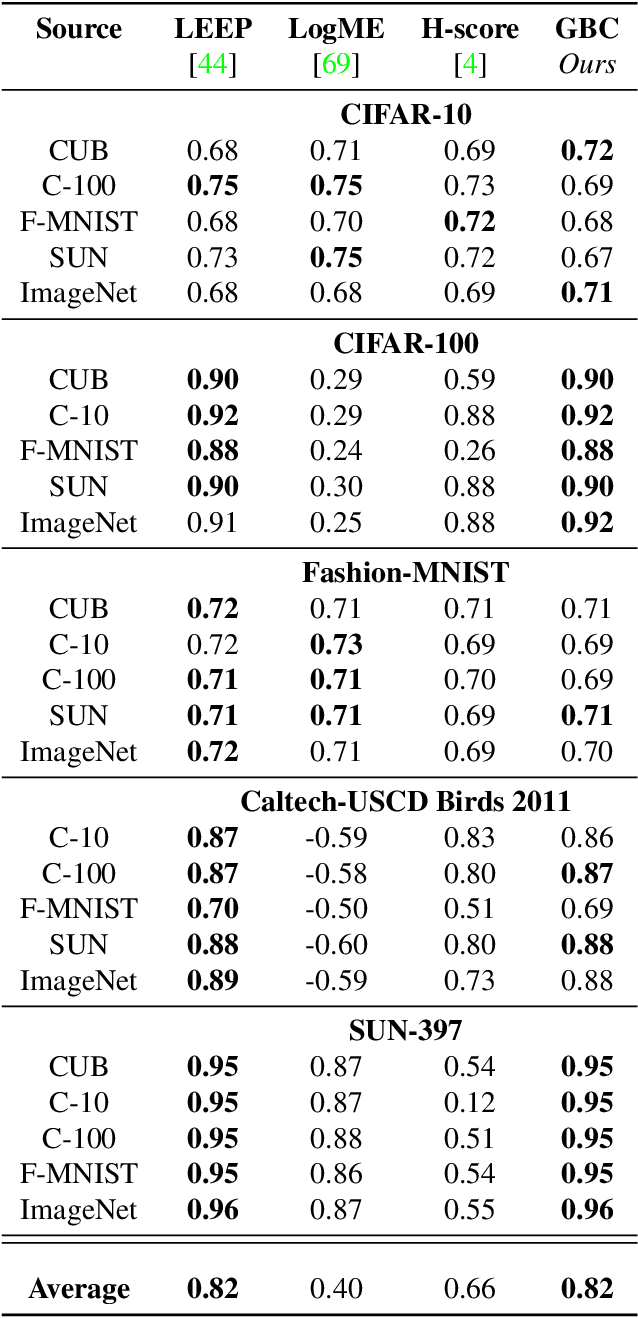
Transfer learning has become a popular method for leveraging pre-trained models in computer vision. However, without performing computationally expensive fine-tuning, it is difficult to quantify which pre-trained source models are suitable for a specific target task, or, conversely, to which tasks a pre-trained source model can be easily adapted to. In this work, we propose Gaussian Bhattacharyya Coefficient (GBC), a novel method for quantifying transferability between a source model and a target dataset. In a first step we embed all target images in the feature space defined by the source model, and represent them with per-class Gaussians. Then, we estimate their pairwise class separability using the Bhattacharyya coefficient, yielding a simple and effective measure of how well the source model transfers to the target task. We evaluate GBC on image classification tasks in the context of dataset and architecture selection. Further, we also perform experiments on the more complex semantic segmentation transferability estimation task. We demonstrate that GBC outperforms state-of-the-art transferability metrics on most evaluation criteria in the semantic segmentation settings, matches the performance of top methods for dataset transferability in image classification, and performs best on architecture selection problems for image classification.
Neural Architecture Search for Efficient Uncalibrated Deep Photometric Stereo
Oct 11, 2021

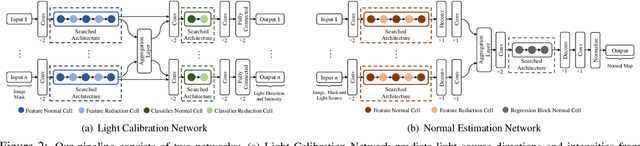

We present an automated machine learning approach for uncalibrated photometric stereo (PS). Our work aims at discovering lightweight and computationally efficient PS neural networks with excellent surface normal accuracy. Unlike previous uncalibrated deep PS networks, which are handcrafted and carefully tuned, we leverage differentiable neural architecture search (NAS) strategy to find uncalibrated PS architecture automatically. We begin by defining a discrete search space for a light calibration network and a normal estimation network, respectively. We then perform a continuous relaxation of this search space and present a gradient-based optimization strategy to find an efficient light calibration and normal estimation network. Directly applying the NAS methodology to uncalibrated PS is not straightforward as certain task-specific constraints must be satisfied, which we impose explicitly. Moreover, we search for and train the two networks separately to account for the Generalized Bas-Relief (GBR) ambiguity. Extensive experiments on the DiLiGenT dataset show that the automatically searched neural architectures performance compares favorably with the state-of-the-art uncalibrated PS methods while having a lower memory footprint.
Neural Radiance Fields Approach to Deep Multi-View Photometric Stereo
Oct 11, 2021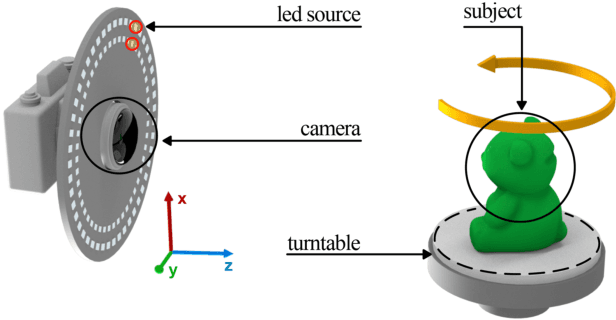

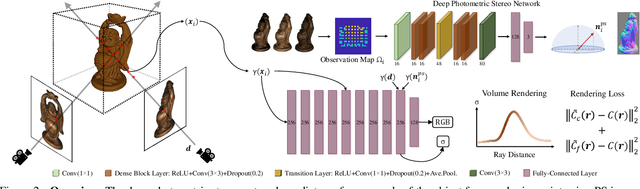
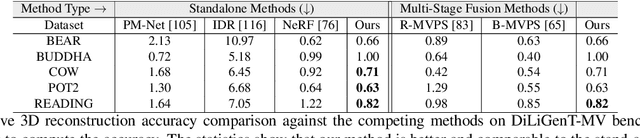
We present a modern solution to the multi-view photometric stereo problem (MVPS). Our work suitably exploits the image formation model in a MVPS experimental setup to recover the dense 3D reconstruction of an object from images. We procure the surface orientation using a photometric stereo (PS) image formation model and blend it with a multi-view neural radiance field representation to recover the object's surface geometry. Contrary to the previous multi-staged framework to MVPS, where the position, iso-depth contours, or orientation measurements are estimated independently and then fused later, our method is simple to implement and realize. Our method performs neural rendering of multi-view images while utilizing surface normals estimated by a deep photometric stereo network. We render the MVPS images by considering the object's surface normals for each 3D sample point along the viewing direction rather than explicitly using the density gradient in the volume space via 3D occupancy information. We optimize the proposed neural radiance field representation for the MVPS setup efficiently using a fully connected deep network to recover the 3D geometry of an object. Extensive evaluation on the DiLiGenT-MV benchmark dataset shows that our method performs better than the approaches that perform only PS or only multi-view stereo (MVS) and provides comparable results against the state-of-the-art multi-stage fusion methods.
Shape from Blur: Recovering Textured 3D Shape and Motion of Fast Moving Objects
Jun 16, 2021
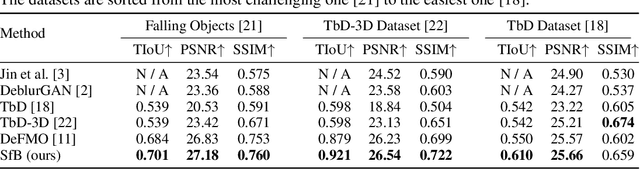
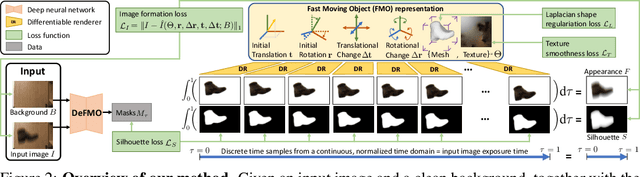
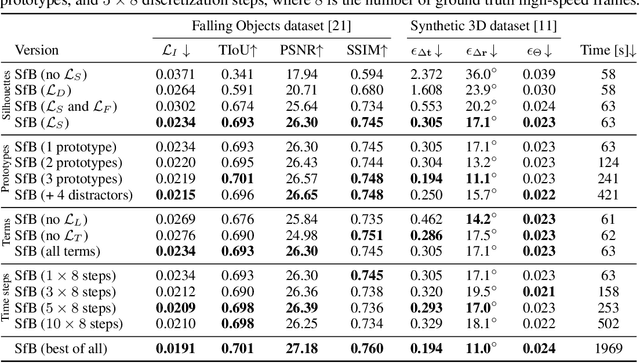
We address the novel task of jointly reconstructing the 3D shape, texture, and motion of an object from a single motion-blurred image. While previous approaches address the deblurring problem only in the 2D image domain, our proposed rigorous modeling of all object properties in the 3D domain enables the correct description of arbitrary object motion. This leads to significantly better image decomposition and sharper deblurring results. We model the observed appearance of a motion-blurred object as a combination of the background and a 3D object with constant translation and rotation. Our method minimizes a loss on reconstructing the input image via differentiable rendering with suitable regularizers. This enables estimating the textured 3D mesh of the blurred object with high fidelity. Our method substantially outperforms competing approaches on several benchmarks for fast moving objects deblurring. Qualitative results show that the reconstructed 3D mesh generates high-quality temporal super-resolution and novel views of the deblurred object.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
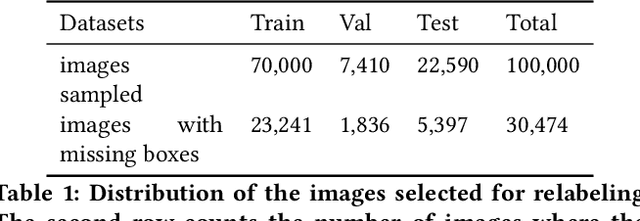
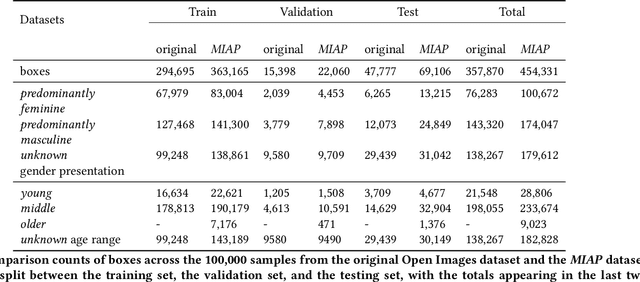
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
Mar 24, 2021
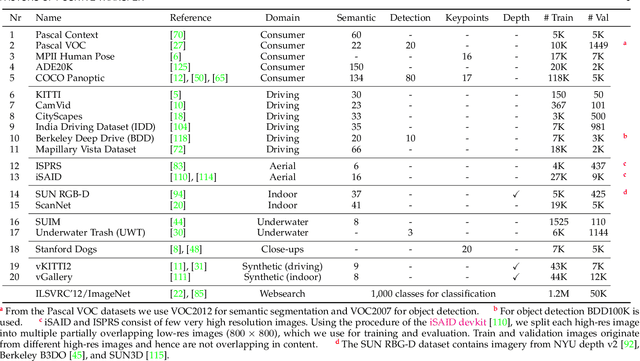
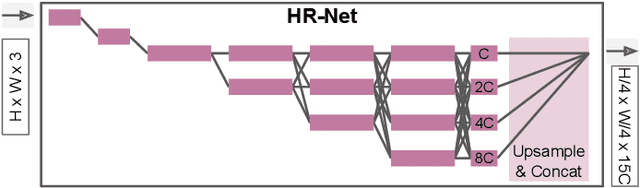

Transfer learning enables to re-use knowledge learned on a source task to help learning a target task. A simple form of transfer learning is common in current state-of-the-art computer vision models, i.e. pre-training a model for image classification on the ILSVRC dataset, and then fine-tune on any target task. However, previous systematic studies of transfer learning have been limited and the circumstances in which it is expected to work are not fully understood. In this paper we carry out an extensive experimental exploration of transfer learning across vastly different image domains (consumer photos, autonomous driving, aerial imagery, underwater, indoor scenes, synthetic, close-ups) and task types (semantic segmentation, object detection, depth estimation, keypoint detection). Importantly, these are all complex, structured output tasks types relevant to modern computer vision applications. In total we carry out over 1200 transfer experiments, including many where the source and target come from different image domains, task types, or both. We systematically analyze these experiments to understand the impact of image domain, task type, and dataset size on transfer learning performance. Our study leads to several insights and concrete recommendations for practitioners.
ShaRF: Shape-conditioned Radiance Fields from a Single View
Feb 17, 2021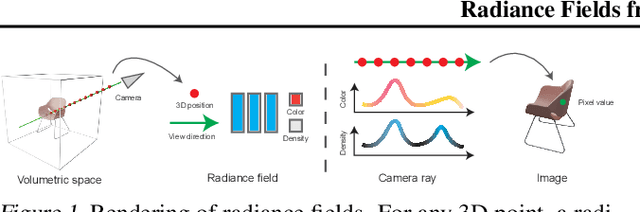
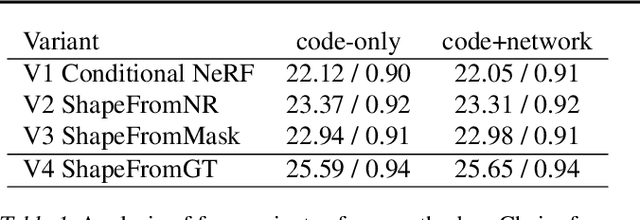
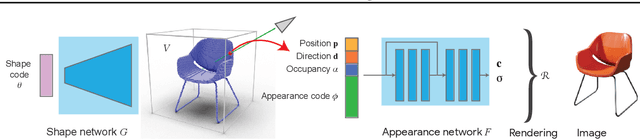
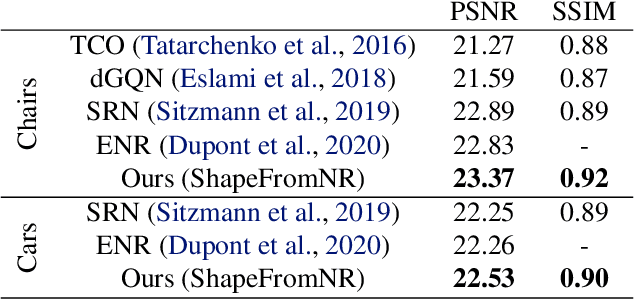
We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
Telling the What while Pointing the Where: Fine-grained Mouse Trace and Language Supervision for Improved Image Retrieval
Feb 09, 2021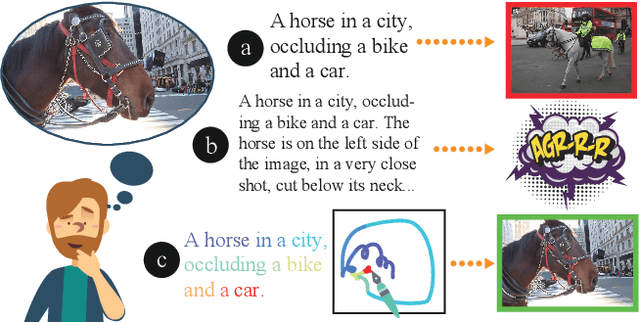
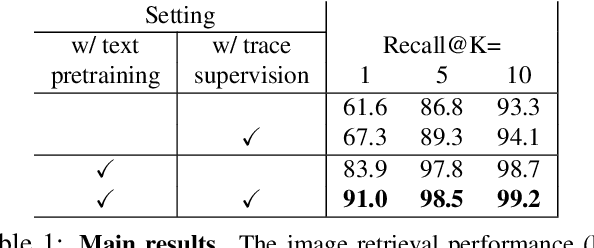


Existing image retrieval systems use text queries to provide a natural and practical way for users to express what they are looking for. However, fine-grained image retrieval often requires the ability to also express the where in the image the content they are looking for is. The textual modality can only cumbersomely express such localization preferences, whereas pointing would be a natural fit. In this paper, we describe an image retrieval setup where the user simultaneously describes an image using both spoken natural language (the "what") and mouse traces over an empty canvas (the "where") to express the characteristics of the desired target image. To this end, we learn an image retrieval model using the Localized Narratives dataset, which is capable of performing early fusion between text descriptions and synchronized mouse traces. Qualitative and quantitative experiments show that our model is capable of taking this spatial guidance into account, and provides more accurate retrieval results compared to text-only equivalent systems.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020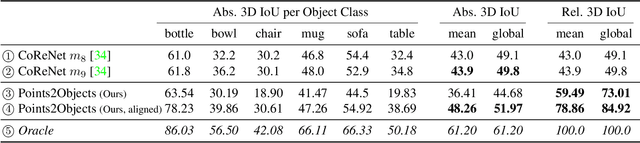
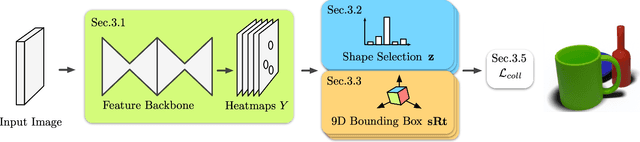

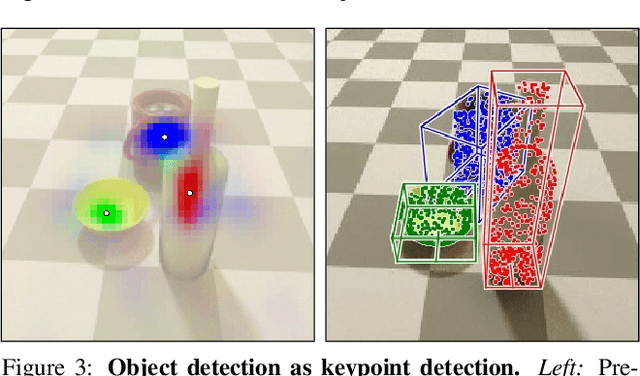
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.