 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023



Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
Beyond SOT: It's Time to Track Multiple Generic Objects at Once
Dec 22, 2022



Generic Object Tracking (GOT) is the problem of tracking target objects, specified by bounding boxes in the first frame of a video. While the task has received much attention in the last decades, researchers have almost exclusively focused on the single object setting. Multi-object GOT benefits from a wider applicability, rendering it more attractive in real-world applications. We attribute the lack of research interest into this problem to the absence of suitable benchmarks. In this work, we introduce a new large-scale GOT benchmark, LaGOT, containing multiple annotated target objects per sequence. Our benchmark allows researchers to tackle key remaining challenges in GOT, aiming to increase robustness and reduce computation through joint tracking of multiple objects simultaneously. Furthermore, we propose a Transformer-based GOT tracker TaMOS capable of joint processing of multiple objects through shared computation. TaMOs achieves a 4x faster run-time in case of 10 concurrent objects compared to tracking each object independently and outperforms existing single object trackers on our new benchmark. Finally, TaMOs achieves highly competitive results on single-object GOT datasets, setting a new state-of-the-art on TrackingNet with a success rate AUC of 84.4%. Our benchmark, code, and trained models will be made publicly available.
From colouring-in to pointillism: revisiting semantic segmentation supervision
Oct 25, 2022The prevailing paradigm for producing semantic segmentation training data relies on densely labelling each pixel of each image in the training set, akin to colouring-in books. This approach becomes a bottleneck when scaling up in the number of images, classes, and annotators. Here we propose instead a pointillist approach for semantic segmentation annotation, where only point-wise yes/no questions are answered. We explore design alternatives for such an active learning approach, measure the speed and consistency of human annotators on this task, show that this strategy enables training good segmentation models, and that it is suitable for evaluating models at test time. As concrete proof of the scalability of our method, we collected and released 22.6M point labels over 4,171 classes on the Open Images dataset. Our results enable to rethink the semantic segmentation pipeline of annotation, training, and evaluation from a pointillism point of view.
Multi-View Photometric Stereo Revisited
Oct 14, 2022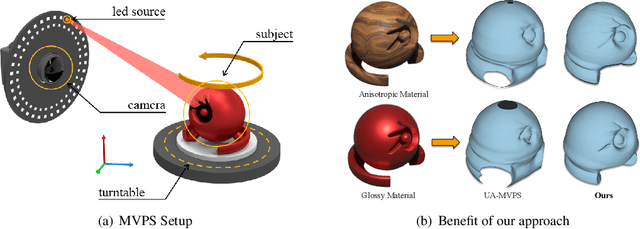

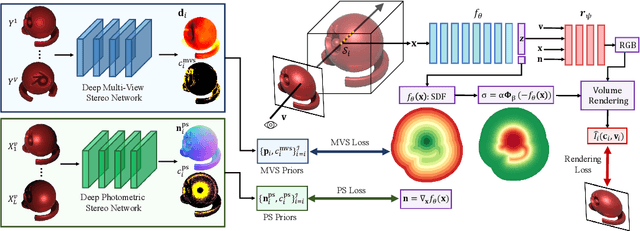
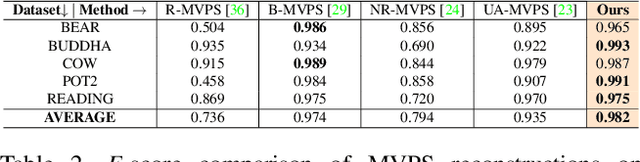
Multi-view photometric stereo (MVPS) is a preferred method for detailed and precise 3D acquisition of an object from images. Although popular methods for MVPS can provide outstanding results, they are often complex to execute and limited to isotropic material objects. To address such limitations, we present a simple, practical approach to MVPS, which works well for isotropic as well as other object material types such as anisotropic and glossy. The proposed approach in this paper exploits the benefit of uncertainty modeling in a deep neural network for a reliable fusion of photometric stereo (PS) and multi-view stereo (MVS) network predictions. Yet, contrary to the recently proposed state-of-the-art, we introduce neural volume rendering methodology for a trustworthy fusion of MVS and PS measurements. The advantage of introducing neural volume rendering is that it helps in the reliable modeling of objects with diverse material types, where existing MVS methods, PS methods, or both may fail. Furthermore, it allows us to work on neural 3D shape representation, which has recently shown outstanding results for many geometric processing tasks. Our suggested new loss function aims to fits the zero level set of the implicit neural function using the most certain MVS and PS network predictions coupled with weighted neural volume rendering cost. The proposed approach shows state-of-the-art results when tested extensively on several benchmark datasets.
The Missing Link: Finding label relations across datasets
Jun 09, 2022

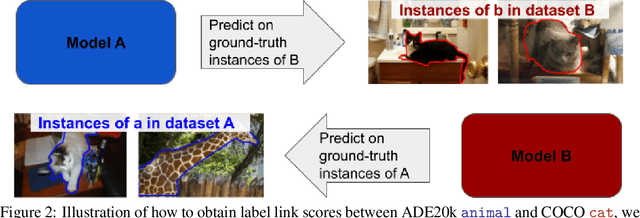
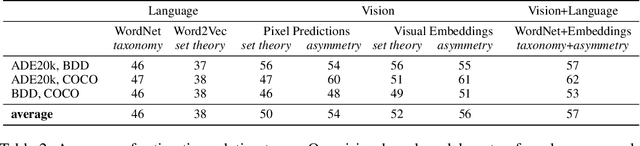
Computer Vision is driven by the many datasets which can be used for training or evaluating novel methods. However, each dataset has different set of class labels, visual definition of classes, images following a specific distribution, annotation protocols, etc. In this paper we explore the automatic discovery of visual-semantic relations between labels across datasets. We want to understand how the instances of a certain class in a dataset relate to the instances of another class in another dataset. Are they in an identity, parent/child, overlap relation? Or is there no link between them at all? To find relations between labels across datasets, we propose methods based on language, on vision, and on a combination of both. Our methods can effectively discover label relations across datasets and the type of the relations. We use these results for a deeper inspection on why instances relate, find missing aspects of a class, and use our relations to create finer-grained annotations. We conclude that label relations cannot be established by looking at the names of classes alone, as they depend strongly on how each of the datasets was constructed.
How stable are Transferability Metrics evaluations?
Apr 11, 2022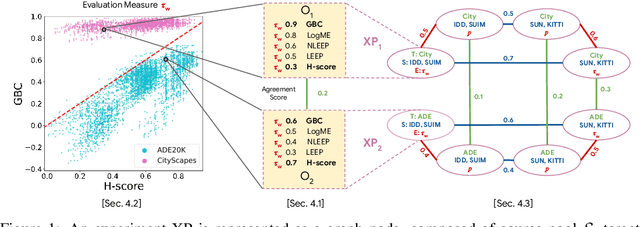
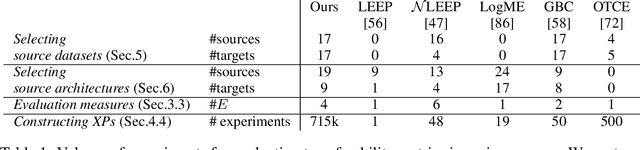
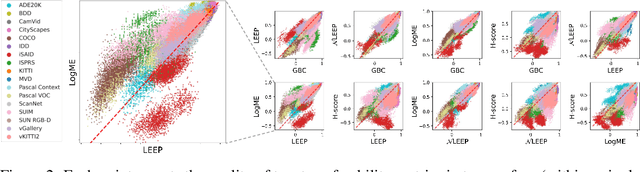
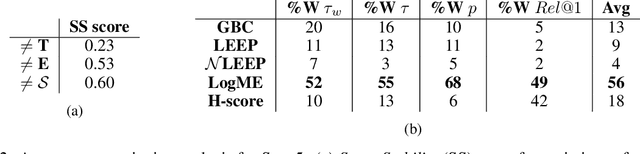
Transferability metrics is a maturing field with increasing interest, which aims at providing heuristics for selecting the most suitable source models to transfer to a given target dataset, without fine-tuning them all. However, existing works rely on custom experimental setups which differ across papers, leading to inconsistent conclusions about which transferability metrics work best. In this paper we conduct a large-scale study by systematically constructing a broad range of 715k experimental setup variations. We discover that even small variations to an experimental setup lead to different conclusions about the superiority of a transferability metric over another. Then we propose better evaluations by aggregating across many experiments, enabling to reach more stable conclusions. As a result, we reveal the superiority of LogME at selecting good source datasets to transfer from in a semantic segmentation scenario, NLEEP at selecting good source architectures in an image classification scenario, and GBC at determining which target task benefits most from a given source model. Yet, no single transferability metric works best in all scenarios.
Uncertainty-Aware Deep Multi-View Photometric Stereo
Mar 28, 2022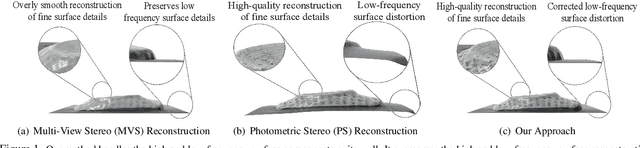

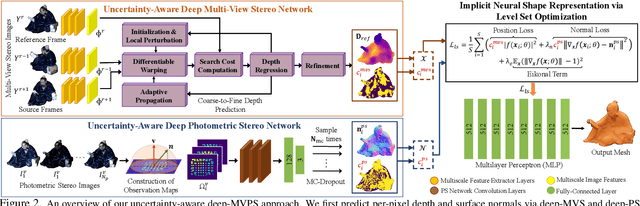

This paper presents a simple and effective solution to the longstanding classical multi-view photometric stereo (MVPS) problem. It is well-known that photometric stereo (PS) is excellent at recovering high-frequency surface details, whereas multi-view stereo (MVS) can help remove the low-frequency distortion due to PS and retain the global geometry of the shape. This paper proposes an approach that can effectively utilize such complementary strengths of PS and MVS. Our key idea is to combine them suitably while considering the per-pixel uncertainty of their estimates. To this end, we estimate per-pixel surface normals and depth using an uncertainty-aware deep-PS network and deep-MVS network, respectively. Uncertainty modeling helps select reliable surface normal and depth estimates at each pixel which then act as a true representative of the dense surface geometry. At each pixel, our approach either selects or discards deep-PS and deep-MVS network prediction depending on the prediction uncertainty measure. For dense, detailed, and precise inference of the object's surface profile, we propose to learn the implicit neural shape representation via a multilayer perceptron (MLP). Our approach encourages the MLP to converge to a natural zero-level set surface using the confident prediction from deep-PS and deep-MVS networks, providing superior dense surface reconstruction. Extensive experiments on the DiLiGenT-MV benchmark dataset show that our method provides high-quality shape recovery with a much lower memory footprint while outperforming almost all of the existing approaches.
RayTran: 3D pose estimation and shape reconstruction of multiple objects from videos with ray-traced transformers
Mar 24, 2022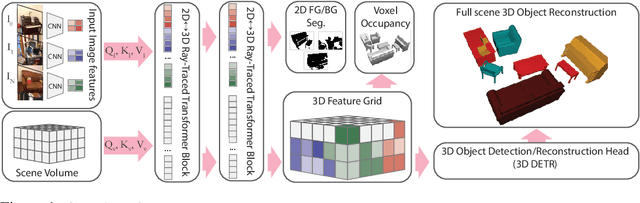
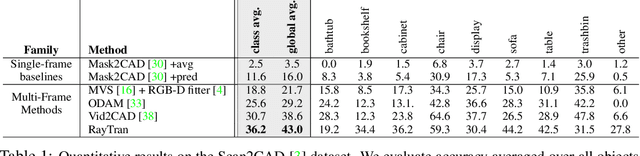
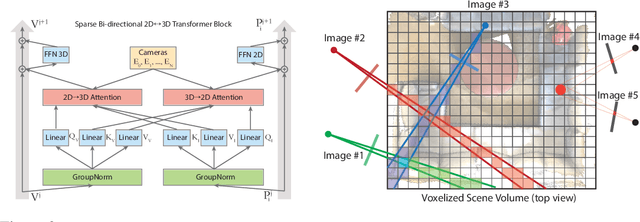
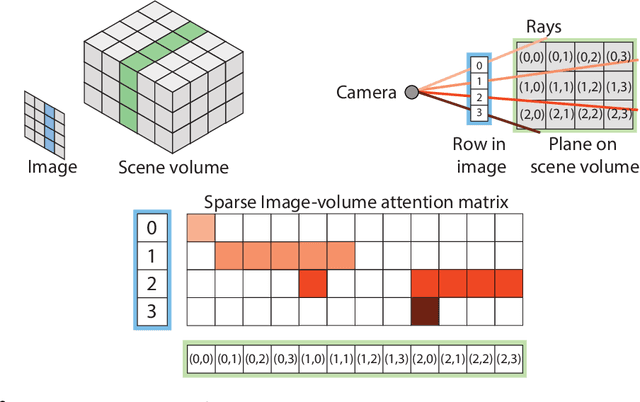
We propose a transformer-based neural network architecture for multi-object 3D reconstruction from RGB videos. It relies on two alternative ways to represent its knowledge: as a global 3D grid of features and an array of view-specific 2D grids. We progressively exchange information between the two with a dedicated bidirectional attention mechanism. We exploit knowledge about the image formation process to significantly sparsify the attention weight matrix, making our architecture feasible on current hardware, both in terms of memory and computation. We attach a DETR-style head on top of the 3D feature grid in order to detect the objects in the scene and to predict their 3D pose and 3D shape. Compared to previous methods, our architecture is single stage, end-to-end trainable, and it can reason holistically about a scene from multiple video frames without needing a brittle tracking step. We evaluate our method on the challenging Scan2CAD dataset, where we outperform (1) recent state-of-the-art methods for 3D object pose estimation from RGB videos; and (2) a strong alternative method combining Multi-view Stereo with RGB-D CAD alignment. We plan to release our source code.
Urban Radiance Fields
Nov 29, 2021
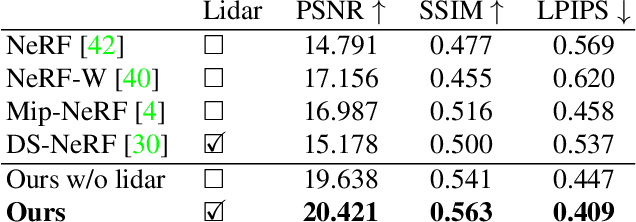


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
Motion-from-Blur: 3D Shape and Motion Estimation of Motion-blurred Objects in Videos
Nov 29, 2021
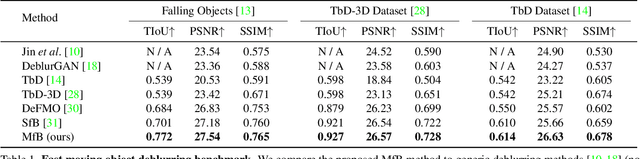
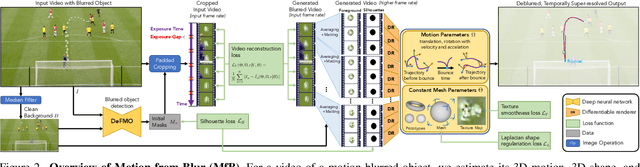
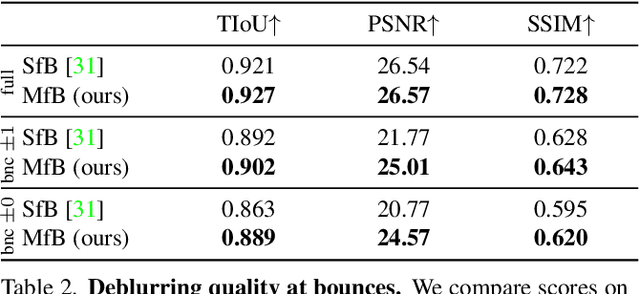
We propose a method for jointly estimating the 3D motion, 3D shape, and appearance of highly motion-blurred objects from a video. To this end, we model the blurred appearance of a fast moving object in a generative fashion by parametrizing its 3D position, rotation, velocity, acceleration, bounces, shape, and texture over the duration of a predefined time window spanning multiple frames. Using differentiable rendering, we are able to estimate all parameters by minimizing the pixel-wise reprojection error to the input video via backpropagating through a rendering pipeline that accounts for motion blur by averaging the graphics output over short time intervals. For that purpose, we also estimate the camera exposure gap time within the same optimization. To account for abrupt motion changes like bounces, we model the motion trajectory as a piece-wise polynomial, and we are able to estimate the specific time of the bounce at sub-frame accuracy. Experiments on established benchmark datasets demonstrate that our method outperforms previous methods for fast moving object deblurring and 3D reconstruction.