 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVincent Y. F. Tan
On the Pareto Frontier of Regret Minimization and Best Arm Identification in Stochastic Bandits
Oct 16, 2021
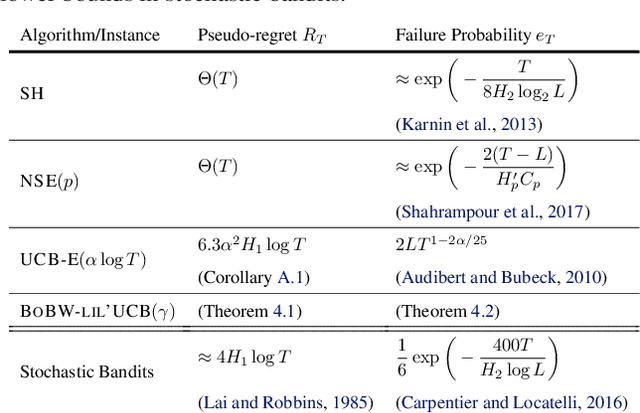
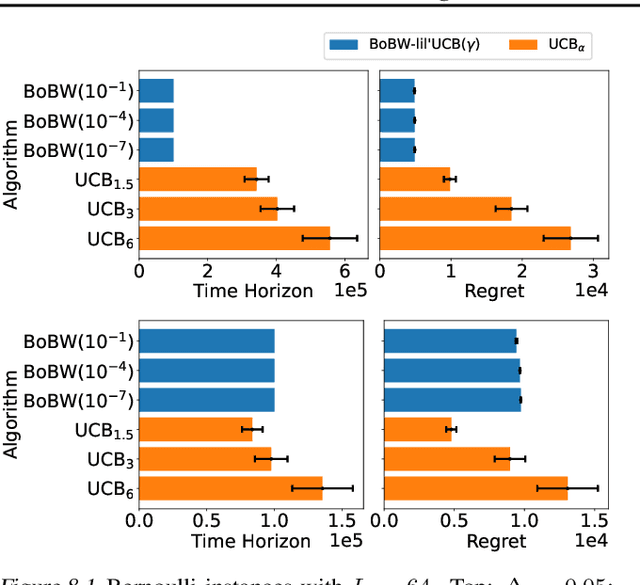
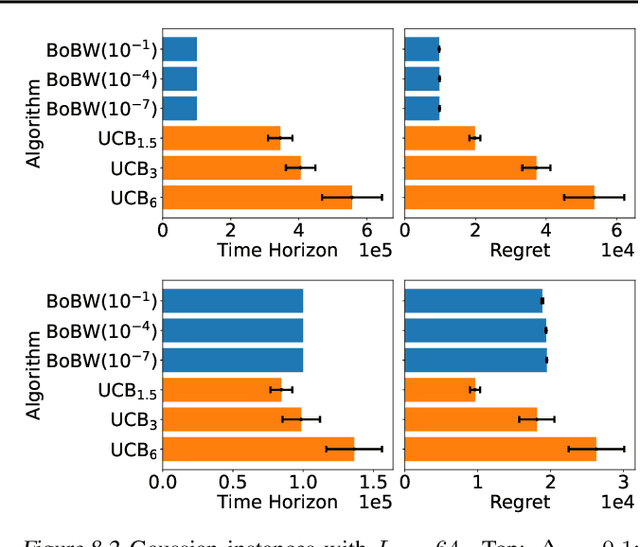

We study the Pareto frontier of two archetypal objectives in stochastic bandits, namely, regret minimization (RM) and best arm identification (BAI) with a fixed horizon. It is folklore that the balance between exploitation and exploration is crucial for both RM and BAI, but exploration is more critical in achieving the optimal performance for the latter objective. To make this precise, we first design and analyze the BoBW-lil'UCB$({\gamma})$ algorithm, which achieves order-wise optimal performance for RM or BAI under different values of ${\gamma}$. Complementarily, we show that no algorithm can simultaneously perform optimally for both the RM and BAI objectives. More precisely, we establish non-trivial lower bounds on the regret achievable by any algorithm with a given BAI failure probability. This analysis shows that in some regimes BoBW-lil'UCB$({\gamma})$ achieves Pareto-optimality up to constant or small terms. Numerical experiments further demonstrate that when applied to difficult instances, BoBW-lil'UCB outperforms a close competitor UCB$_{\alpha}$ (Degenne et al., 2019), which is designed for RM and BAI with a fixed confidence.
Efficient Sharpness-aware Minimization for Improved Training of Neural Networks
Oct 07, 2021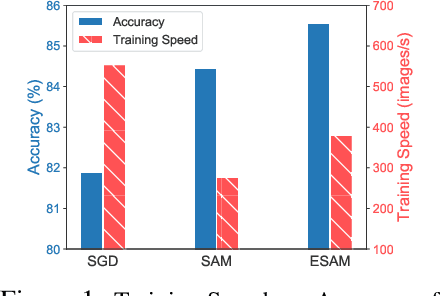
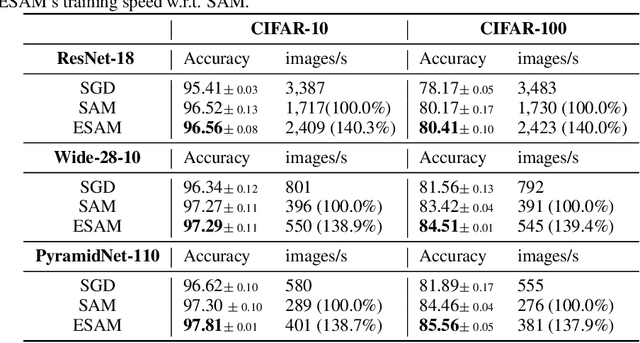
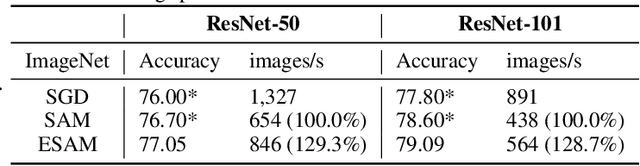
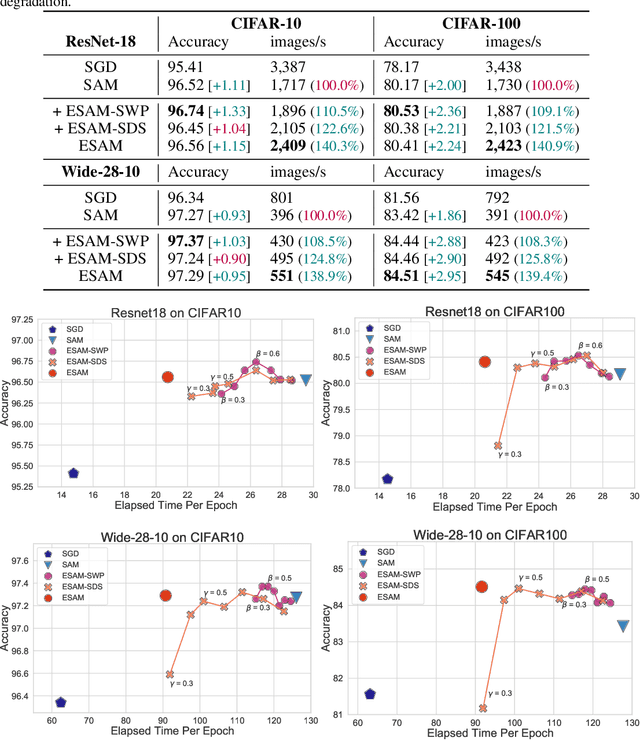
Overparametrized Deep Neural Networks (DNNs) often achieve astounding performances, but may potentially result in severe generalization error. Recently, the relation between the sharpness of the loss landscape and the generalization error has been established by Foret et al. (2020), in which the Sharpness Aware Minimizer (SAM) was proposed to mitigate the degradation of the generalization. Unfortunately, SAM s computational cost is roughly double that of base optimizers, such as Stochastic Gradient Descent (SGD). This paper thus proposes Efficient Sharpness Aware Minimizer (ESAM), which boosts SAM s efficiency at no cost to its generalization performance. ESAM includes two novel and efficient training strategies-StochasticWeight Perturbation and Sharpness-Sensitive Data Selection. In the former, the sharpness measure is approximated by perturbing a stochastically chosen set of weights in each iteration; in the latter, the SAM loss is optimized using only a judiciously selected subset of data that is sensitive to the sharpness. We provide theoretical explanations as to why these strategies perform well. We also show, via extensive experiments on the CIFAR and ImageNet datasets, that ESAM enhances the efficiency over SAM from requiring 100% extra computations to 40% vis-a-vis base optimizers, while test accuracies are preserved or even improved.
Information-Theoretic Generalization Bounds for Iterative Semi-Supervised Learning
Oct 03, 2021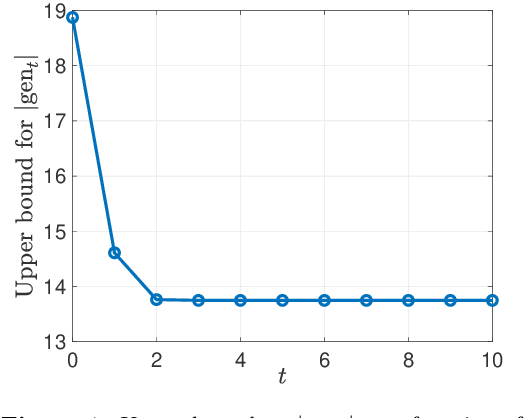


We consider iterative semi-supervised learning (SSL) algorithms that iteratively generate pseudo-labels for a large amount unlabelled data to progressively refine the model parameters. In particular, we seek to understand the behaviour of the {\em generalization error} of iterative SSL algorithms using information-theoretic principles. To obtain bounds that are amenable to numerical evaluation, we first work with a simple model -- namely, the binary Gaussian mixture model. Our theoretical results suggest that when the class conditional variances are not too large, the upper bound on the generalization error decreases monotonically with the number of iterations, but quickly saturates. The theoretical results on the simple model are corroborated by extensive experiments on several benchmark datasets such as the MNIST and CIFAR datasets in which we notice that the generalization error improves after several pseudo-labelling iterations, but saturates afterwards.
A Unifying Theory of Thompson Sampling for Continuous Risk-Averse Bandits
Aug 25, 2021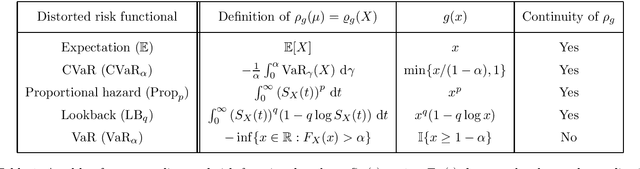
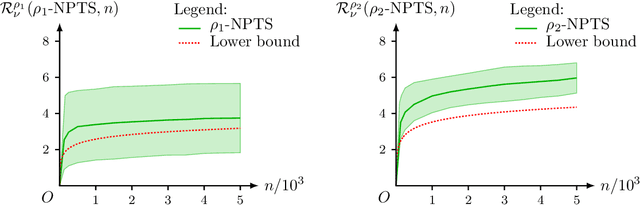
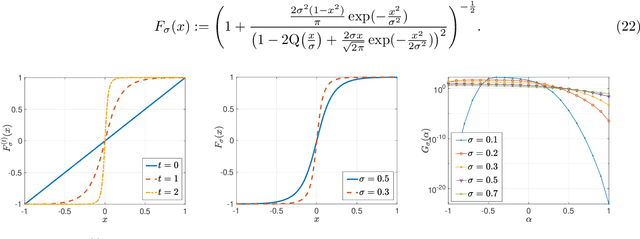
This paper unifies the design and simplifies the analysis of risk-averse Thompson sampling algorithms for the multi-armed bandit problem for a generic class of risk functionals \r{ho} that are continuous. Using the contraction principle in the theory of large deviations, we prove novel concentration bounds for these continuous risk functionals. In contrast to existing works in which the bounds depend on the samples themselves, our bounds only depend on the number of samples. This allows us to sidestep significant analytical challenges and unify existing proofs of the regret bounds of existing Thompson sampling-based algorithms. We show that a wide class of risk functionals as well as "nice" functions of them satisfy the continuity condition. Using our newly developed analytical toolkits, we analyse the algorithms $\rho$-MTS (for multinomial distributions) and $\rho$-NPTS (for bounded distributions) and prove that they admit asymptotically optimal regret bounds of risk-averse algorithms under the mean-variance, CVaR, and other ubiquitous risk measures, as well as a host of newly synthesized risk measures. Numerical simulations show that our bounds are reasonably tight vis-\`a-vis algorithm-independent lower bounds.
Robustifying Algorithms of Learning Latent Trees with Vector Variables
Jun 03, 2021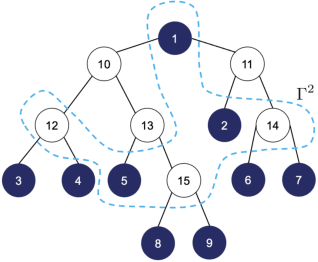

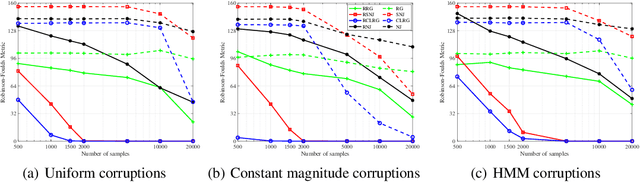
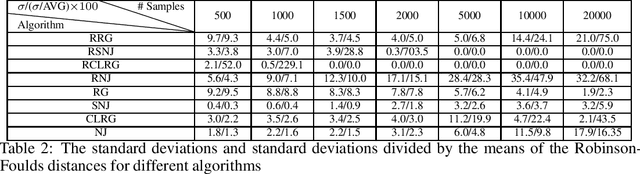
We consider learning the structures of Gaussian latent tree models with vector observations when a subset of them are arbitrarily corrupted. First, we present the sample complexities of Recursive Grouping (RG) and Chow-Liu Recursive Grouping (CLRG) without the assumption that the effective depth is bounded in the number of observed nodes, significantly generalizing the results in Choi et al. (2011). We show that Chow-Liu initialization in CLRG greatly reduces the sample complexity of RG from being exponential in the diameter of the tree to only logarithmic in the diameter for the hidden Markov model (HMM). Second, we robustify RG, CLRG, Neighbor Joining (NJ) and Spectral NJ (SNJ) by using the truncated inner product. These robustified algorithms can tolerate a number of corruptions up to the square root of the number of clean samples. Finally, we derive the first known instance-dependent impossibility result for structure learning of latent trees. The optimalities of the robust version of CLRG and NJ are verified by comparing their sample complexities and the impossibility result.
Towards Minimax Optimal Best Arm Identification in Linear Bandits
May 27, 2021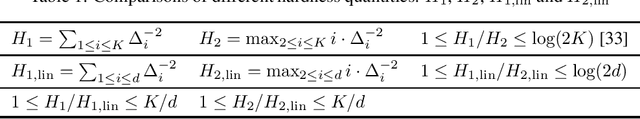
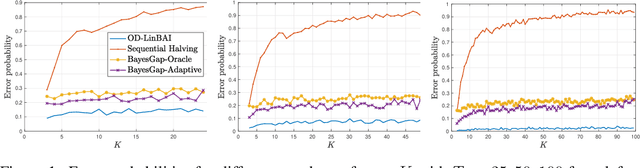
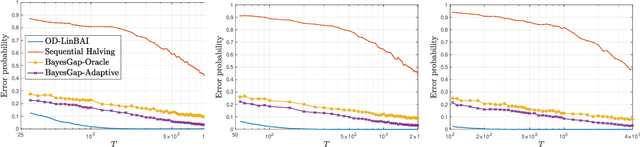
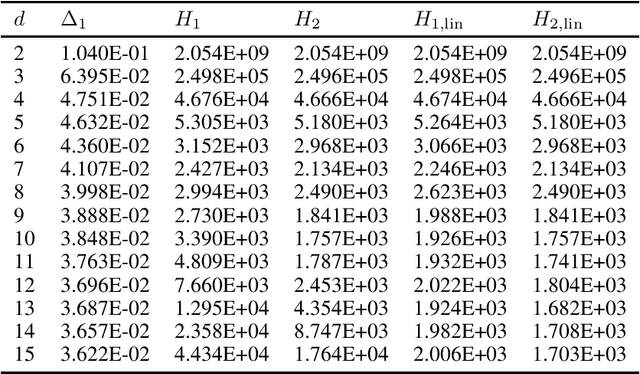
We study the problem of best arm identification in linear bandits in the fixed-budget setting. By leveraging properties of the G-optimal design and incorporating it into the arm allocation rule, we design a parameter-free algorithm, Optimal Design-based Linear Best Arm Identification (OD-LinBAI). We provide a theoretical analysis of the failure probability of OD-LinBAI. While the performances of existing methods (e.g., BayesGap) depend on all the optimality gaps, OD-LinBAI depends on the gaps of the top $d$ arms, where $d$ is the effective dimension of the linear bandit instance. Furthermore, we present a minimax lower bound for this problem. The upper and lower bounds show that OD-LinBAI is minimax optimal up to multiplicative factors in the exponent. Finally, numerical experiments corroborate our theoretical findings.
Exact Recovery in the General Hypergraph Stochastic Block Model
May 11, 2021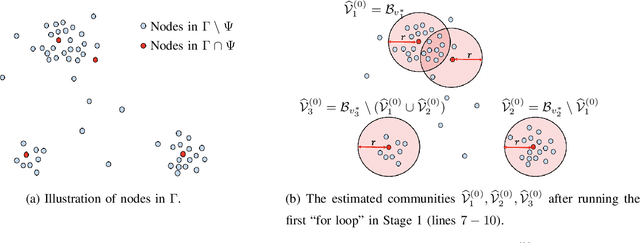
This paper investigates fundamental limits of exact recovery in the general d-uniform hypergraph stochastic block model (d-HSBM), wherein n nodes are partitioned into k disjoint communities with relative sizes (p1,..., pk). Each subset of nodes with cardinality d is generated independently as an order-d hyperedge with a certain probability that depends on the ground-truth communities that the d nodes belong to. The goal is to exactly recover the k hidden communities based on the observed hypergraph. We show that there exists a sharp threshold such that exact recovery is achievable above the threshold and impossible below the threshold (apart from a small regime of parameters that will be specified precisely). This threshold is represented in terms of a quantity which we term as the generalized Chernoff-Hellinger divergence between communities. Our result for this general model recovers prior results for the standard SBM and d-HSBM with two symmetric communities as special cases. En route to proving our achievability results, we develop a polynomial-time two-stage algorithm that meets the threshold. The first stage adopts a certain hypergraph spectral clustering method to obtain a coarse estimate of communities, and the second stage refines each node individually via local refinement steps to ensure exact recovery.
Adversarially-Trained Nonnegative Matrix Factorization
Apr 10, 2021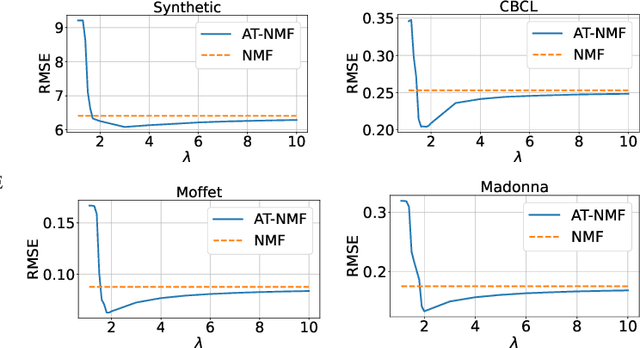
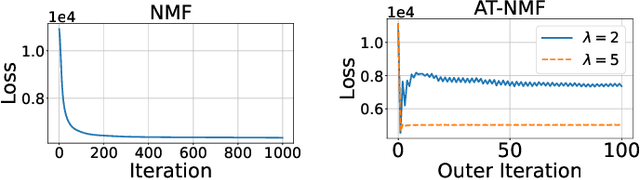
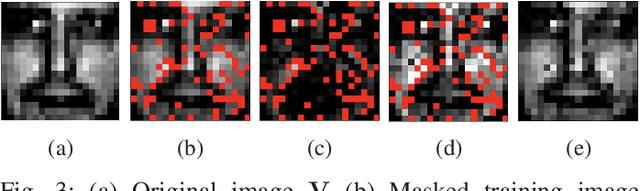

We consider an adversarially-trained version of the nonnegative matrix factorization, a popular latent dimensionality reduction technique. In our formulation, an attacker adds an arbitrary matrix of bounded norm to the given data matrix. We design efficient algorithms inspired by adversarial training to optimize for dictionary and coefficient matrices with enhanced generalization abilities. Extensive simulations on synthetic and benchmark datasets demonstrate the superior predictive performance on matrix completion tasks of our proposed method compared to state-of-the-art competitors, including other variants of adversarial nonnegative matrix factorization.
CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection
Feb 10, 2021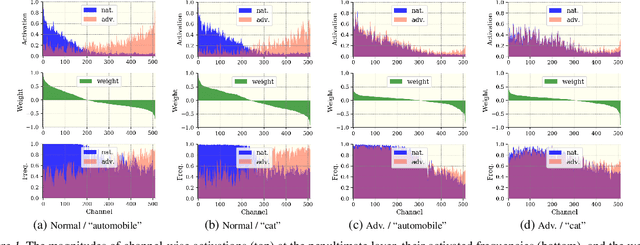
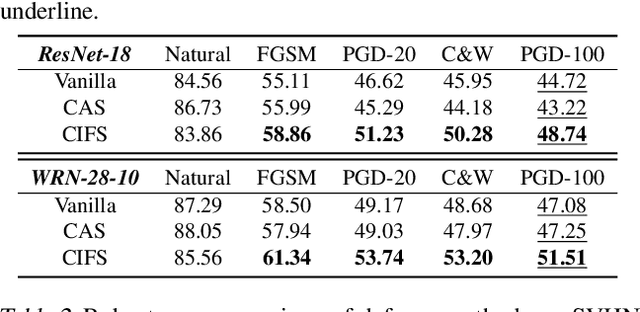
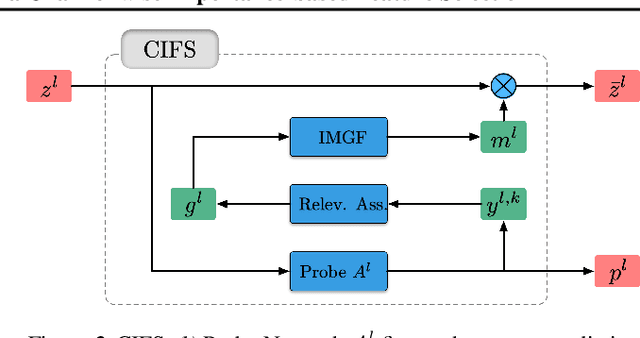
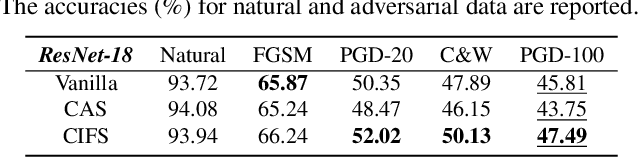
We investigate the adversarial robustness of CNNs from the perspective of channel-wise activations. By comparing \textit{non-robust} (normally trained) and \textit{robustified} (adversarially trained) models, we observe that adversarial training (AT) robustifies CNNs by aligning the channel-wise activations of adversarial data with those of their natural counterparts. However, the channels that are \textit{negatively-relevant} (NR) to predictions are still over-activated when processing adversarial data. Besides, we also observe that AT does not result in similar robustness for all classes. For the robust classes, channels with larger activation magnitudes are usually more \textit{positively-relevant} (PR) to predictions, but this alignment does not hold for the non-robust classes. Given these observations, we hypothesize that suppressing NR channels and aligning PR ones with their relevances further enhances the robustness of CNNs under AT. To examine this hypothesis, we introduce a novel mechanism, i.e., \underline{C}hannel-wise \underline{I}mportance-based \underline{F}eature \underline{S}election (CIFS). The CIFS manipulates channels' activations of certain layers by generating non-negative multipliers to these channels based on their relevances to predictions. Extensive experiments on benchmark datasets including CIFAR10 and SVHN clearly verify the hypothesis and CIFS's effectiveness of robustifying CNNs.
SGA: A Robust Algorithm for Partial Recovery of Tree-Structured Graphical Models with Noisy Samples
Jan 22, 2021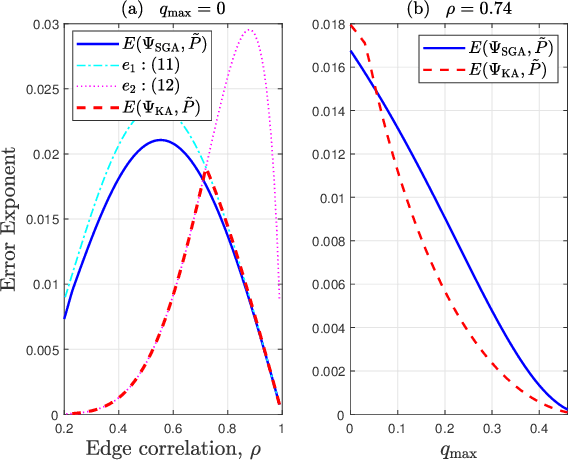
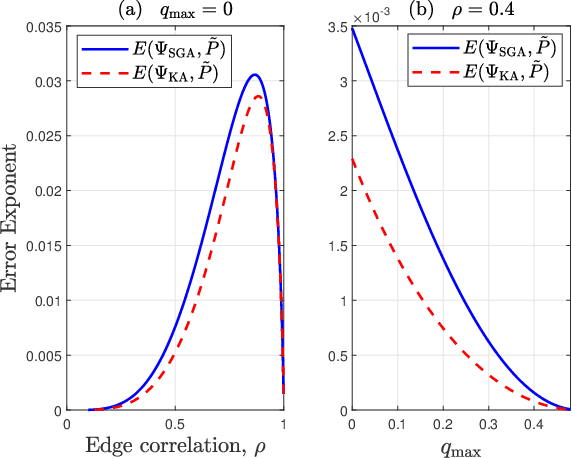
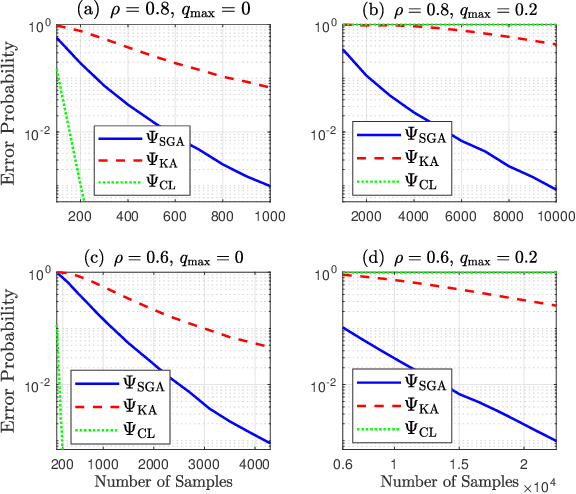
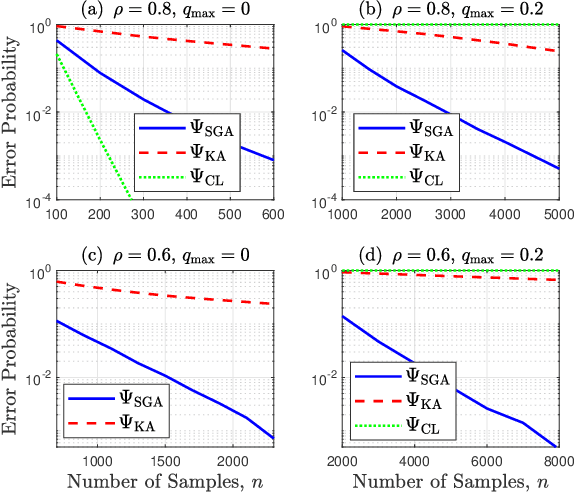
We consider learning Ising tree models when the observations from the nodes are corrupted by independent but non-identically distributed noise with unknown statistics. Katiyar et al. (2020) showed that although the exact tree structure cannot be recovered, one can recover a partial tree structure; that is, a structure belonging to the equivalence class containing the true tree. This paper presents a systematic improvement of Katiyar et al. (2020). First, we present a novel impossibility result by deriving a bound on the necessary number of samples for partial recovery. Second, we derive a significantly improved sample complexity result in which the dependence on the minimum correlation $\rho_{\min}$ is $\rho_{\min}^{-8}$ instead of $\rho_{\min}^{-24}$. Finally, we propose Symmetrized Geometric Averaging (SGA), a more statistically robust algorithm for partial tree recovery. We provide error exponent analyses and extensive numerical results on a variety of trees to show that the sample complexity of SGA is significantly better than the algorithm of Katiyar et al. (2020). SGA can be readily extended to Gaussian models and is shown via numerical experiments to be similarly superior.