 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic Optimality of Thompson Sampling for Risk-Averse Bandits with Sub-Gaussian Rewards
Jun 08, 2026We prove that $ρ\text{-}\mathrm{NPTS}_{\mathrm{SG}}$, an anchor-free nonparametric Thompson Sampling algorithm for risk-averse bandits, achieves regret matching the instance-dependent lower bound to leading order in $\log n$, establishing it as asymptotically optimal for any continuous risk functional $ρ$ (CVaR, mean-variance, Sharpe ratio, distortion risk measures, and more) on the class of distributions with bounded density and sub-Gaussian tails, including Gaussian arms. Both this result and its bounded-support counterpart require only continuity of $ρ$: strictly weaker than the dominance condition of prior parametric Thompson Sampling results, and strictly weaker than the Lipschitz condition of UCB-type algorithms, yielding the first instance-optimal guarantees for non-Lipschitz functionals such as the Sharpe ratio without parametric reward assumptions. The bounded-support case is developed first as a stepping stone sharing the same proof structure. The key technical contributions are a discretisation lemma (bounded support) and a truncated discretisation lemma (sub-Gaussian tails), each projecting the growing-alphabet Dirichlet posterior onto a fixed grid via the Dirichlet aggregation property, holding all polynomial prefactors at fixed degree independent of sample size and breaking the super-exponential barrier that blocked prior proofs.
A Unifying Theory of Thompson Sampling for Continuous Risk-Averse Bandits
Aug 25, 2021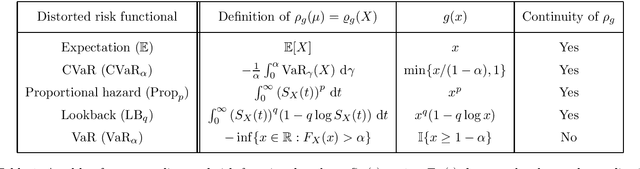
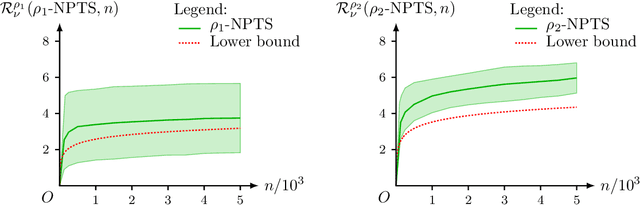
This paper unifies the design and simplifies the analysis of risk-averse Thompson sampling algorithms for the multi-armed bandit problem for a generic class of risk functionals \r{ho} that are continuous. Using the contraction principle in the theory of large deviations, we prove novel concentration bounds for these continuous risk functionals. In contrast to existing works in which the bounds depend on the samples themselves, our bounds only depend on the number of samples. This allows us to sidestep significant analytical challenges and unify existing proofs of the regret bounds of existing Thompson sampling-based algorithms. We show that a wide class of risk functionals as well as "nice" functions of them satisfy the continuity condition. Using our newly developed analytical toolkits, we analyse the algorithms $\rho$-MTS (for multinomial distributions) and $\rho$-NPTS (for bounded distributions) and prove that they admit asymptotically optimal regret bounds of risk-averse algorithms under the mean-variance, CVaR, and other ubiquitous risk measures, as well as a host of newly synthesized risk measures. Numerical simulations show that our bounds are reasonably tight vis-\`a-vis algorithm-independent lower bounds.
Thompson Sampling for Gaussian Entropic Risk Bandits
May 14, 2021The multi-armed bandit (MAB) problem is a ubiquitous decision-making problem that exemplifies exploration-exploitation tradeoff. Standard formulations exclude risk in decision making. Risknotably complicates the basic reward-maximising objectives, in part because there is no universally agreed definition of it. In this paper, we consider an entropic risk (ER) measure and explore the performance of a Thompson sampling-based algorithm ERTS under this risk measure by providing regret bounds for ERTS and corresponding instance dependent lower bounds.
Risk-Constrained Thompson Sampling for CVaR Bandits
Nov 17, 2020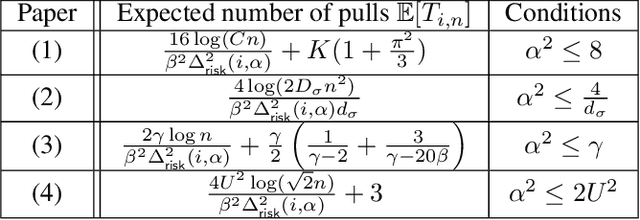
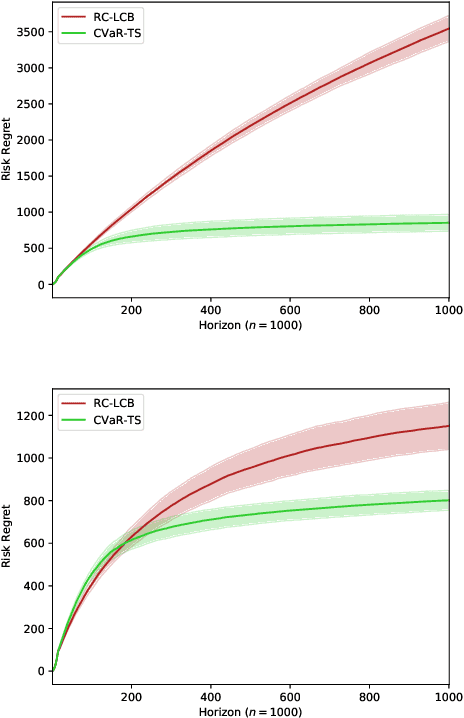
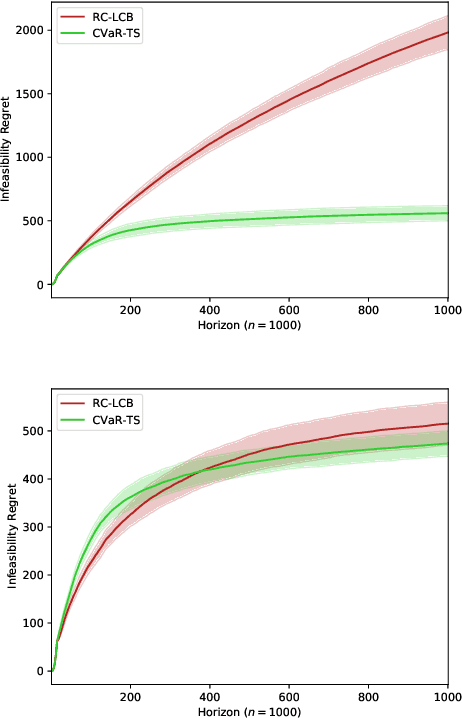
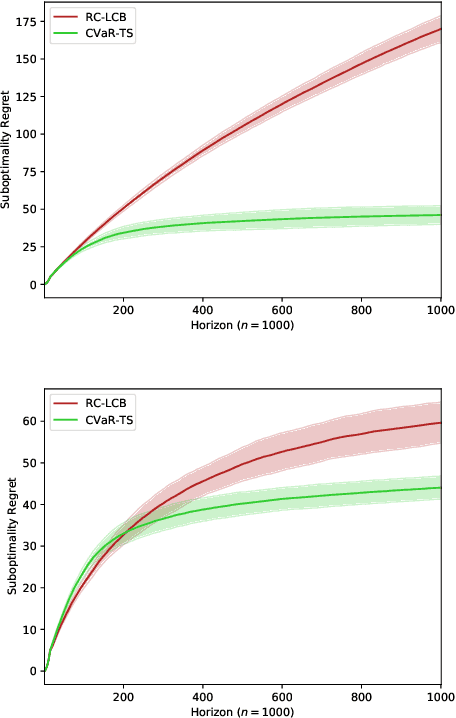
The multi-armed bandit (MAB) problem is a ubiquitous decision-making problem that exemplifies the exploration-exploitation tradeoff. Standard formulations exclude risk in decision making. Risk notably complicates the basic reward-maximising objective, in part because there is no universally agreed definition of it. In this paper, we consider a popular risk measure in quantitative finance known as the Conditional Value at Risk (CVaR). We explore the performance of a Thompson Sampling-based algorithm CVaR-TS under this risk measure. We provide comprehensive comparisons between our regret bounds with state-of-the-art L/UCB-based algorithms in comparable settings and demonstrate their clear improvement in performance. We also include numerical simulations to empirically verify that CVaR-TS outperforms other L/UCB-based algorithms.