 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP2C: Geometric Projection Parameter Consensus for Joint 3D Pose and Focal Length Estimation in the Wild
Aug 07, 2019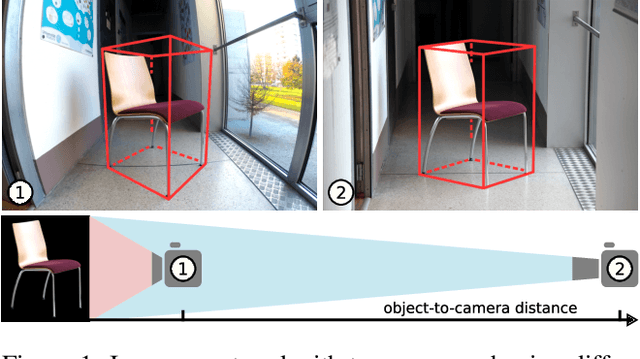
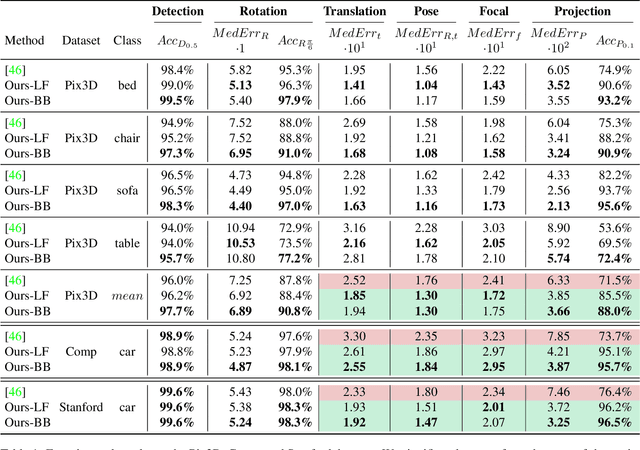
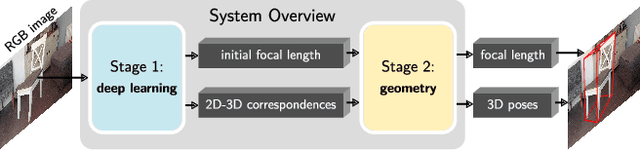
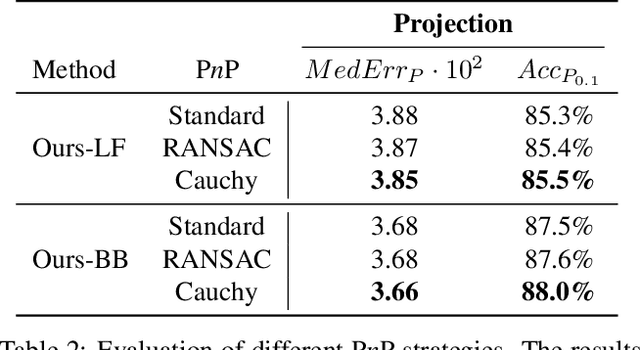
We present a joint 3D pose and focal length estimation approach for object categories in the wild. In contrast to previous methods that predict 3D poses independently of the focal length or assume a constant focal length, we explicitly estimate and integrate the focal length into the 3D pose estimation. For this purpose, we combine deep learning techniques and geometric algorithms in a two-stage approach: First, we estimate an initial focal length and establish 2D-3D correspondences from a single RGB image using a deep network. Second, we recover 3D poses and refine the focal length by minimizing the reprojection error of the predicted correspondences. In this way, we exploit the geometric prior given by the focal length for 3D pose estimation. This results in two advantages: First, we achieve significantly improved 3D translation and 3D pose accuracy compared to existing methods. Second, our approach finds a geometric consensus between the individual projection parameters, which is required for precise 2D-3D alignment. We evaluate our proposed approach on three challenging real-world datasets (Pix3D, Comp, and Stanford) with different object categories and significantly outperform the state-of-the-art by up to 20% absolute in multiple different metrics.
HO-3D: A Multi-User, Multi-Object Dataset for Joint 3D Hand-Object Pose Estimation
Jul 02, 2019

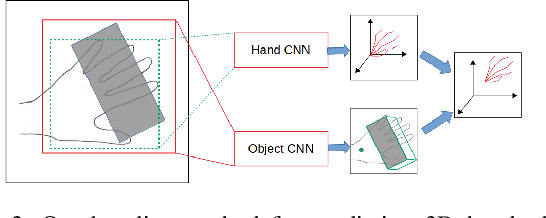

We propose a new dataset for 3D hand+object pose estimation from color images, together with a method for efficiently annotating this dataset, and a 3D pose prediction method based on this dataset. The current lack of training data makes the 3D hand+object pose estimation very challenging. This lack is due to the complexity of labeling many real images with both 3D poses and of generating synthetic images with various realistic interaction. Moreover, even if synthetic images could be used for training, annotated real images are still needed for validation. To tackle this challenge, we capture sequences with a simple setup made of a single RGB-D camera. We also use a color camera imaging the sequences from a side view, but only for validation. We introduce a novel method based on global optimization that exploits depth, color, and temporal constraints for efficiently annotating the sequences, which we use to train another novel method that predicts both the 3D poses of the hand and the object from a single color image. Our hope is to encourage other researchers to develop better annotation methods for our dataset: One can then apply such method to capture and easily annotate sequences captured with a single RGB-D camera to easily create additional training data thus solving one of the main problems of 3D hand+object pose estimation.
AssemblyNet: A Novel Deep Decision-Making Process for Whole Brain MRI Segmentation
Jun 05, 2019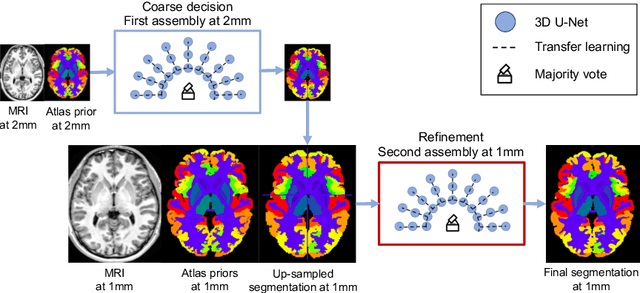

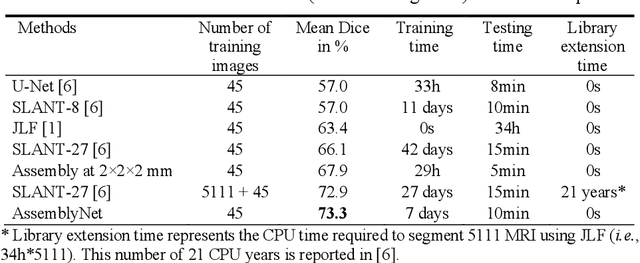
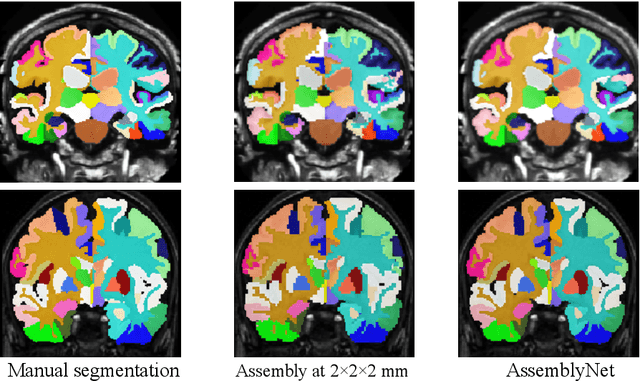
Whole brain segmentation using deep learning (DL) is a very challenging task since the number of anatomical labels is very high compared to the number of available training images. To address this problem, previous DL methods proposed to use a global convolution neural network (CNN) or few independent CNNs. In this paper, we present a novel ensemble method based on a large number of CNNs processing different overlapping brain areas. Inspired by parliamentary decision-making systems, we propose a framework called AssemblyNet, made of two "assemblies" of U-Nets. Such a parliamentary system is capable of dealing with complex decisions and reaching a consensus quickly. AssemblyNet introduces sharing of knowledge among neighboring U-Nets, an "amendment" procedure made by the second assembly at higher-resolution to refine the decision taken by the first one, and a final decision obtained by majority voting. When using the same 45 training images, AssemblyNet outperforms global U-Net by 28% in terms of the Dice metric, patch-based joint label fusion by 15% and SLANT-27 by 10%. Finally, AssemblyNet demonstrates high capacity to deal with limited training data to achieve whole brain segmentation in practical training and testing times.
SharpNet: Fast and Accurate Recovery of Occluding Contours in Monocular Depth Estimation
May 21, 2019

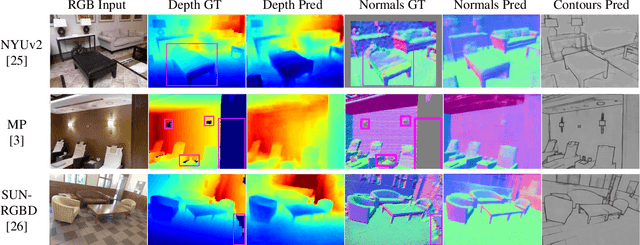

We introduce SharpNet, a method that predicts an accurate depth map for an input color image, with a particular attention to the reconstruction of occluding contours: Occluding contours are an important cue for object recognition, and for realistic integration of virtual objects in Augmented Reality, but they are also notoriously difficult to reconstruct accurately. For example, they are a challenge for stereo-based reconstruction methods, as points around an occluding contour are visible in only one image. Inspired by recent methods that introduce normal estimation to improve depth prediction, we introduce a novel term that constrains depth and occluding contours predictions. Since ground truth depth is difficult to obtain with pixel-perfect accuracy along occluding contours, we use synthetic images for training, followed by fine-tuning on real data. We demonstrate our approach on the challenging NYUv2-Depth dataset, and show that our method outperforms the state-of-the-art along occluding contours, while performing on par with the best recent methods for the rest of the images. Its accuracy along the occluding contours is actually better than the `ground truth' acquired by a depth camera based on structured light. We show this by introducing a new benchmark based on NYUv2-Depth for evaluating occluding contours in monocular reconstruction, which is our second contribution.
Speed Invariant Time Surface for Learning to Detect Corner Points with Event-Based Cameras
Apr 30, 2019
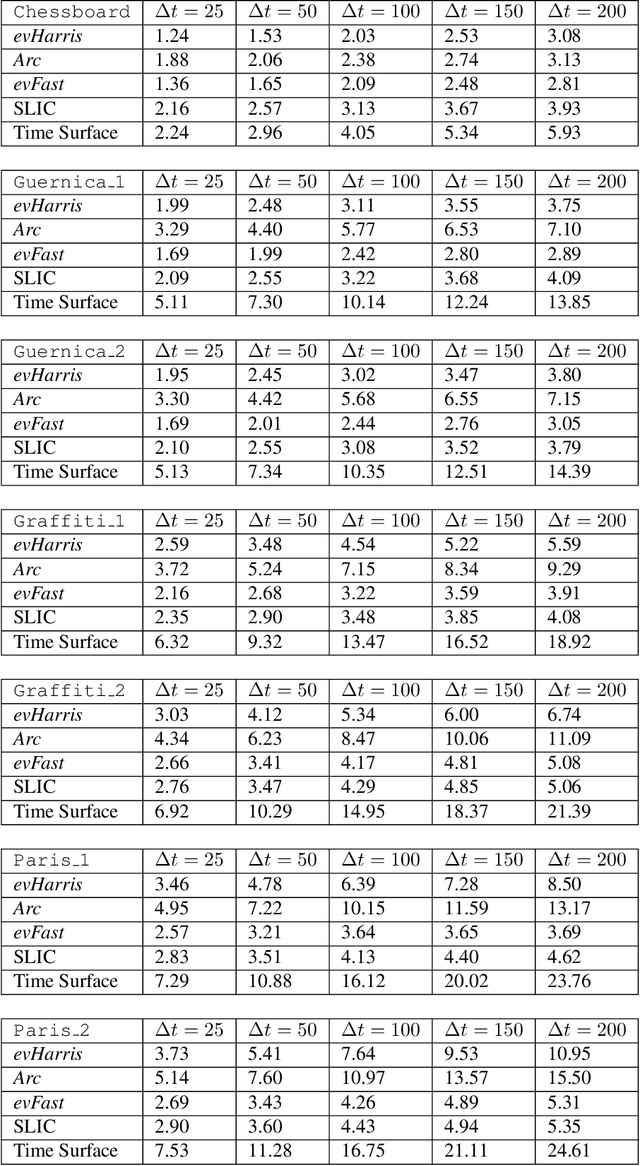

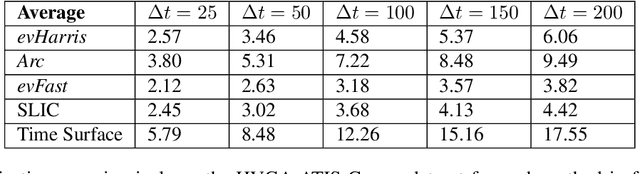
We propose a learning approach to corner detection for event-based cameras that is stable even under fast and abrupt motions. Event-based cameras offer high temporal resolution, power efficiency, and high dynamic range. However, the properties of event-based data are very different compared to standard intensity images, and simple extensions of corner detection methods designed for these images do not perform well on event-based data. We first introduce an efficient way to compute a time surface that is invariant to the speed of the objects. We then show that we can train a Random Forest to recognize events generated by a moving corner from our time surface. Random Forests are also extremely efficient, and therefore a good choice to deal with the high capture frequency of event-based cameras ---our implementation processes up to 1.6Mev/s on a single CPU. Thanks to our time surface formulation and this learning approach, our method is significantly more robust to abrupt changes of direction of the corners compared to previous ones. Our method also naturally assigns a confidence score for the corners, which can be useful for postprocessing. Moreover, we introduce a high-resolution dataset suitable for quantitative evaluation and comparison of corner detection methods for event-based cameras. We call our approach SILC, for Speed Invariant Learned Corners, and compare it to the state-of-the-art with extensive experiments, showing better performance.
Casting Geometric Constraints in Semantic Segmentation as Semi-Supervised Learning
Apr 30, 2019
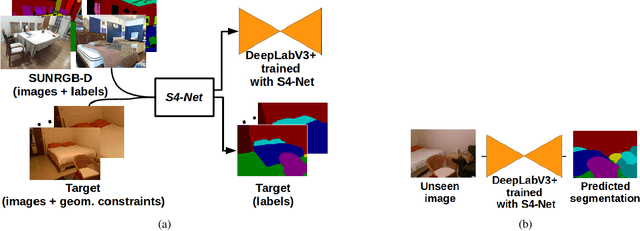

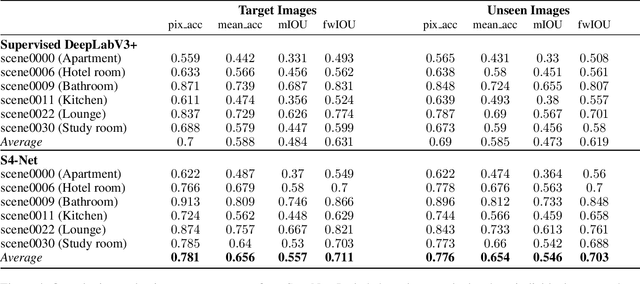
We propose a simple yet effective method to learn to segment new indoor scenes from an RGB-D sequence: State-of-the-art methods trained on one dataset, even as large as SUNRGB-D dataset, can perform poorly when applied to images that are not part of the dataset, because of the dataset bias, a common phenomenon in computer vision. To make semantic segmentation more useful in practice, we learn to segment new indoor scenes from sequences without manual annotations by exploiting geometric constraints and readily available training data from SUNRGB-D. As a result, we can then robustly segment new images of these scenes from color information only. To efficiently exploit geometric constraints for our purpose, we propose to cast these constraints as semi-supervised terms, which enforce the fact that the same class should be predicted for the projections of the same 3D location in different images. We show that this approach results in a simple yet very powerful method, which can annotate sequences of ScanNet and our own sequences using only annotations from SUNRGB-D.
Generalized Feedback Loop for Joint Hand-Object Pose Estimation
Mar 25, 2019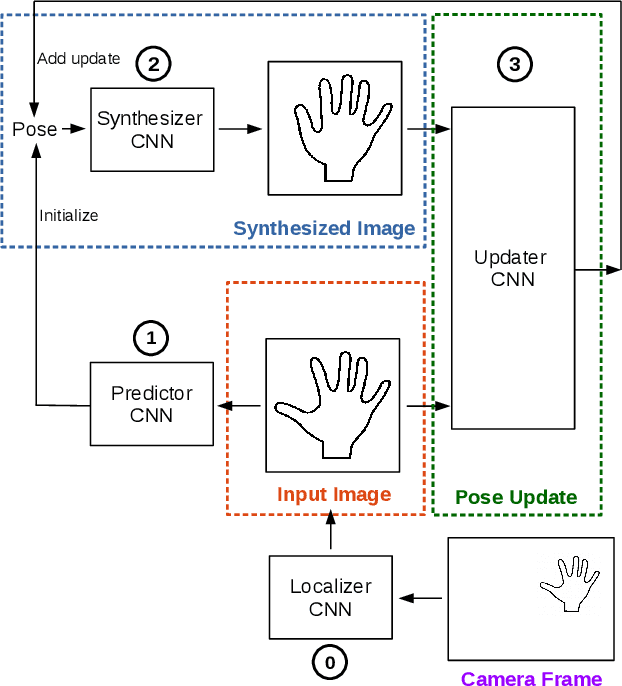
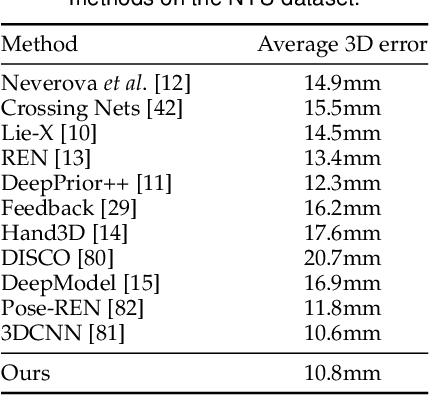
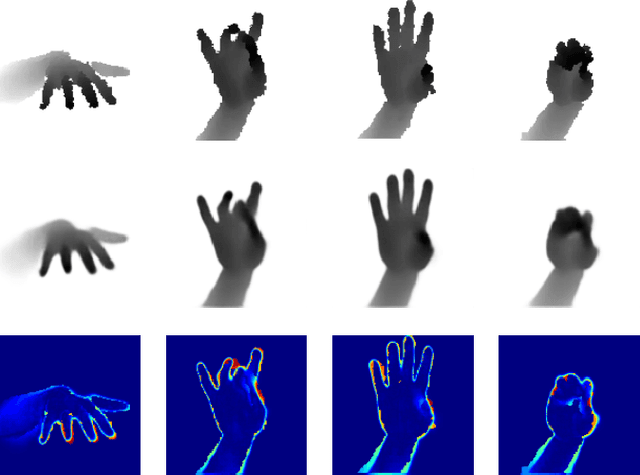
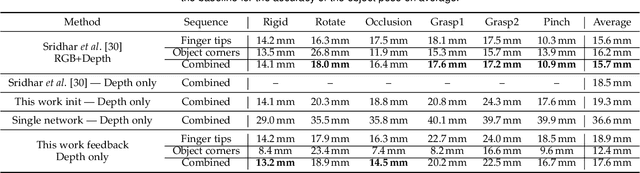
We propose an approach to estimating the 3D pose of a hand, possibly handling an object, given a depth image. We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop. The components of this feedback loop are also Deep Networks, optimized using training data. This approach can be generalized to a hand interacting with an object. Therefore, we jointly estimate the 3D pose of the hand and the 3D pose of the object. Our approach performs en-par with state-of-the-art methods for 3D hand pose estimation, and outperforms state-of-the-art methods for joint hand-object pose estimation when using depth images only. Also, our approach is efficient as our implementation runs in real-time on a single GPU.
* arXiv admin note: substantial text overlap with arXiv:1609.09698
S4-Net: Geometry-Consistent Semi-Supervised Semantic Segmentation
Jan 09, 2019

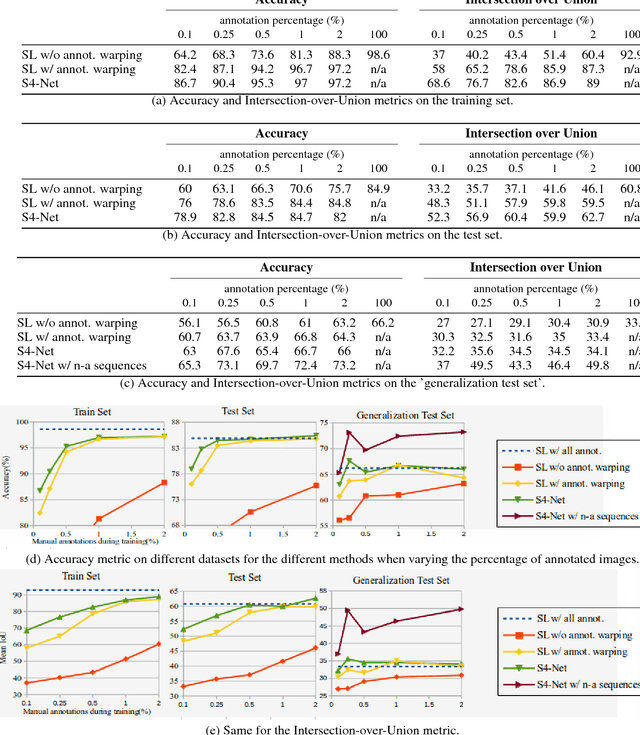

We show that it is possible to learn semantic segmentation from very limited amounts of manual annotations, by enforcing geometric 3D constraints between multiple views. More exactly, image locations corresponding to the same physical 3D point should all have the same label. We show that introducing such constraints during learning is very effective, even when no manual label is available for a 3D point, and can be done simply by employing techniques from 'general' semi-supervised learning to the context of semantic segmentation. To demonstrate this idea, we use RGB-D image sequences of rigid scenes, for a 4-class segmentation problem derived from the ScanNet dataset. Starting from RGB-D sequences with a few annotated frames, we show that we can incorporate RGB-D sequences without any manual annotations to improve the performance, which makes our approach very convenient. Furthermore, we demonstrate our approach for semantic segmentation of objects on the LabelFusion dataset, where we show that one manually labeled image in a scene is sufficient for high performance on the whole scene.
Efficient Condition-based Representations for Long-Term Visual Localization
Dec 10, 2018
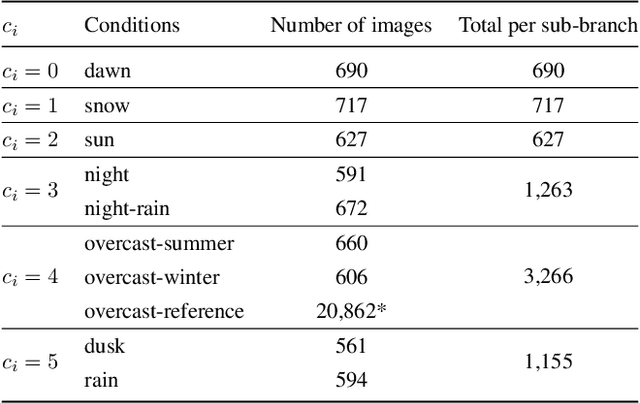
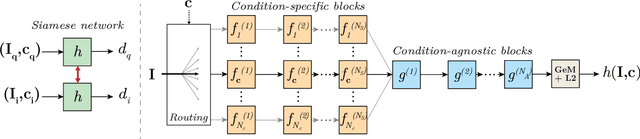

We propose an approach to localization from images that is designed to explicitly handle the strong variations in appearance happening when capturing conditions change throughout the day or across seasons. As revealed by recent long-term localization benchmarks, both traditional feature-based and retrieval-based approaches still struggle to handle such changes. Our novel retrieval-based method introduces condition-specific sub-networks allowing the computation of global image descriptors that are explicitly dependent of the capturing conditions. We compare our approach to previous localization methods on very recent challenging benchmarks, and observe that our method outperforms them by a large margin in case of day-night variation, where repeatable feature points cannot be identified or matched.
HANDS18: Methods, Techniques and Applications for Hand Observation
Oct 25, 2018
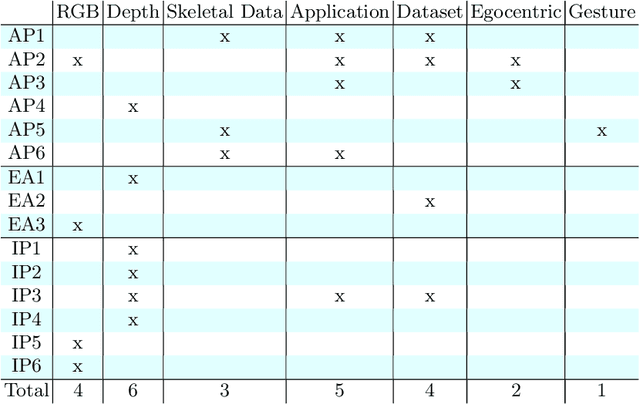
This report outlines the proceedings of the Fourth International Workshop on Observing and Understanding Hands in Action (HANDS 2018). The fourth instantiation of this workshop attracted significant interest from both academia and the industry. The program of the workshop included regular papers that are published as the workshop's proceedings, extended abstracts, invited posters, and invited talks. Topics of the submitted works and invited talks and posters included novel methods for hand pose estimation from RGB, depth, or skeletal data, datasets for special cases and real-world applications, and techniques for hand motion re-targeting and hand gesture recognition. The invited speakers are leaders in their respective areas of specialization, coming from both industry and academia. The main conclusions that can be drawn are the turn of the community towards RGB data and the maturation of some methods and techniques, which in turn has led to increasing interest for real-world applications.