 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
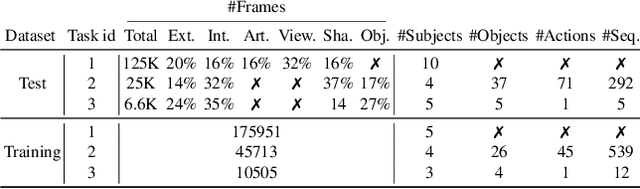
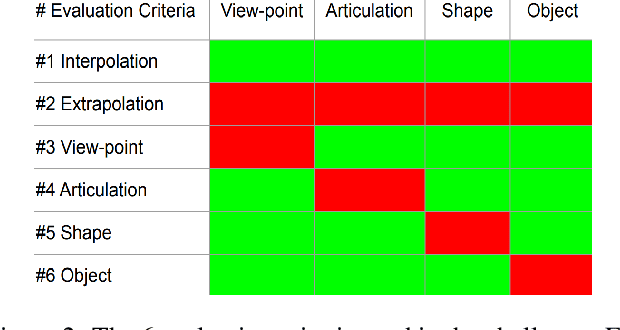
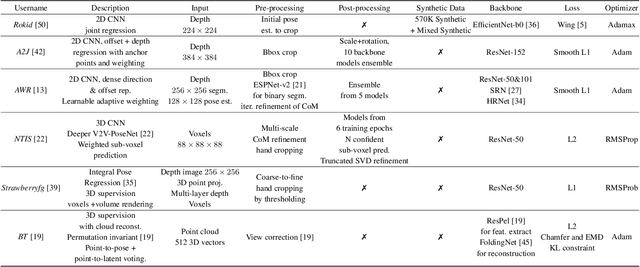
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Predicting Sharp and Accurate Occlusion Boundaries in Monocular Depth Estimation Using Displacement Fields
Feb 28, 2020
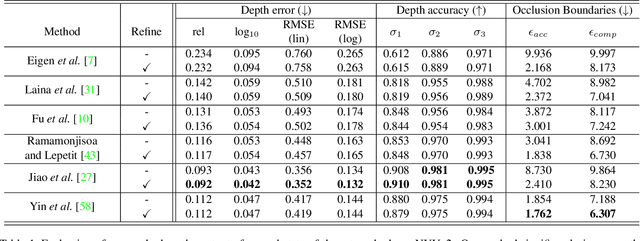

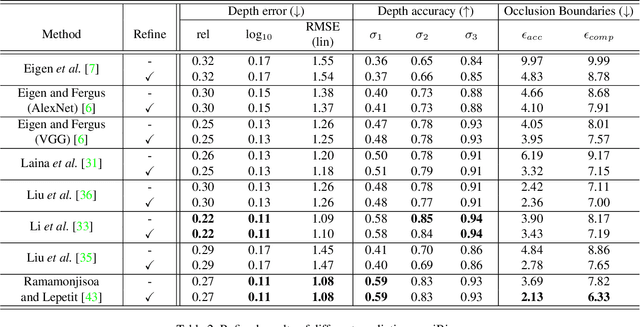
Current methods for depth map prediction from monocular images tend to predict smooth, poorly localized contours for the occlusion boundaries in the input image. This is unfortunate as occlusion boundaries are important cues to recognize objects, and as we show, may lead to a way to discover new objects from scene reconstruction. To improve predicted depth maps, recent methods rely on various forms of filtering or predict an additive residual depth map to refine a first estimate. We instead learn to predict, given a depth map predicted by some reconstruction method, a 2D displacement field able to re-sample pixels around the occlusion boundaries into sharper reconstructions. Our method can be applied to the output of any depth estimation method, in an end-to-end trainable fashion. For evaluation, we manually annotated the occlusion boundaries in all the images in the test split of popular NYUv2-Depth dataset. We show that our approach improves the localization of occlusion boundaries for all state-of-the-art monocular depth estimation methods that we could evaluate, without degrading the depth accuracy for the rest of the images.
General 3D Room Layout from a Single View by Render-and-Compare
Jan 07, 2020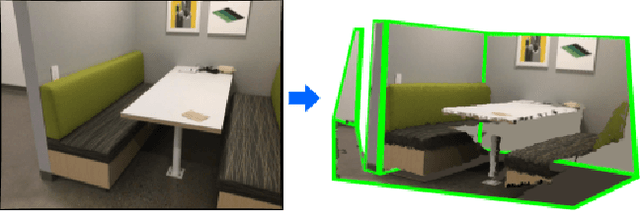



We present a novel method to reconstruct the 3D layout of a room -- walls,floors, ceilings -- from a single perspective view, even for the case of general configurations. This input view can consist of a color image only, but considering a depth map will result in a more accurate reconstruction. Our approach is based on solving a constrained discrete optimization problem, which selects the polygons which are part of the layout from a large set of potential polygons. In order to deal with occlusions between components of the layout, which is a problem ignored by previous works, we introduce an analysis-by-synthesis method to iteratively refine the 3D layout estimate. To the best of our knowledge, our method is the first that can estimate a layout in such general conditions from a single view. We additionally introduce a new annotation dataset made of 91 images from the ScanNet dataset and several metrics, in order to evaluate our results quantitatively.
AssemblyNet: A large ensemble of CNNs for 3D Whole Brain MRI Segmentation
Nov 20, 2019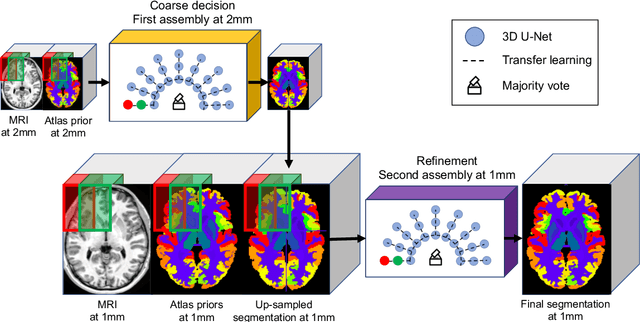
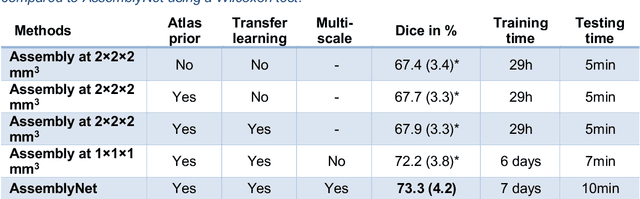
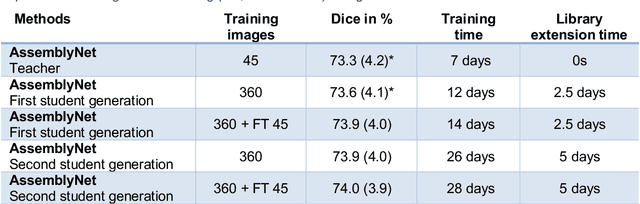
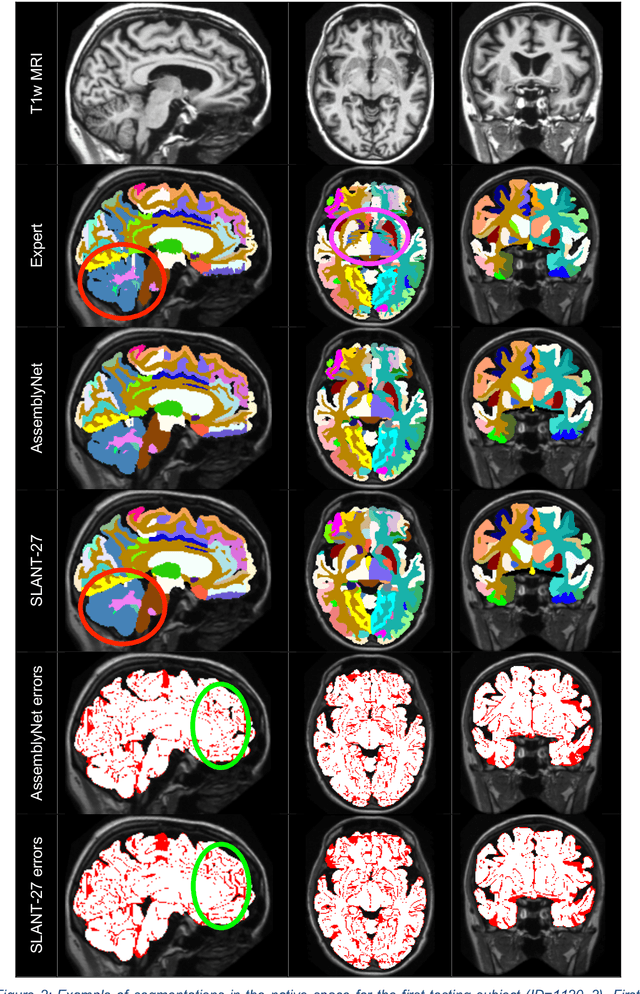
Whole brain segmentation using deep learning (DL) is a very challenging task since the number of anatomical labels is very high compared to the number of available training images. To address this problem, previous DL methods proposed to use a single convolution neural network (CNN) or few independent CNNs. In this paper, we present a novel ensemble method based on a large number of CNNs processing different overlapping brain areas. Inspired by parliamentary decision-making systems, we propose a framework called AssemblyNet, made of two "assemblies" of U-Nets. Such a parliamentary system is capable of dealing with complex decisions, unseen problem and reaching a consensus quickly. AssemblyNet introduces sharing of knowledge among neighboring U-Nets, an "amendment" procedure made by the second assembly at higher-resolution to refine the decision taken by the first one, and a final decision obtained by majority voting. During our validation, AssemblyNet showed competitive performance compared to state-of-the-art methods such as U-Net, Joint label fusion and SLANT. Moreover, we investigated the scan-rescan consistency and the robustness to disease effects of our method. These experiences demonstrated the reliability of AssemblyNet. Finally, we showed the interest of using semi-supervised learning to improve the performance of our method.
Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation
Oct 27, 2019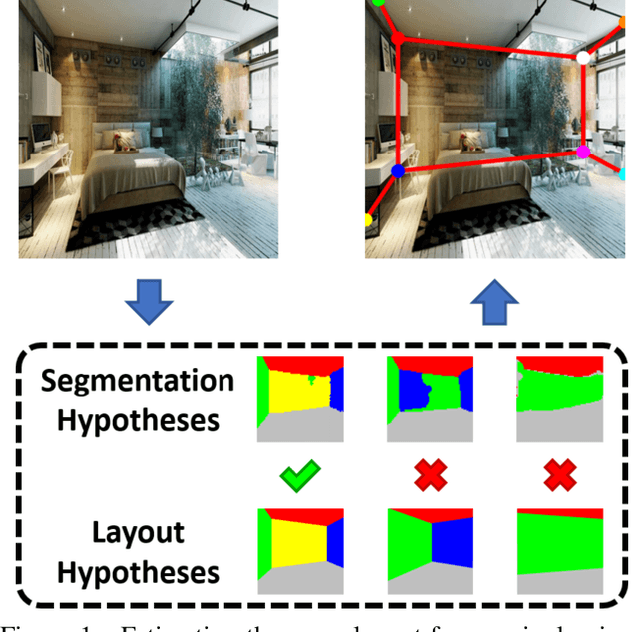
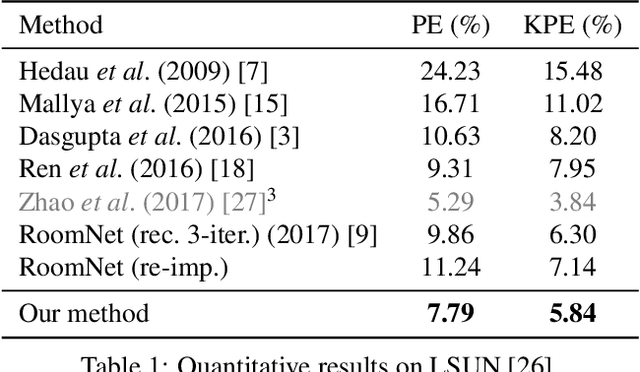

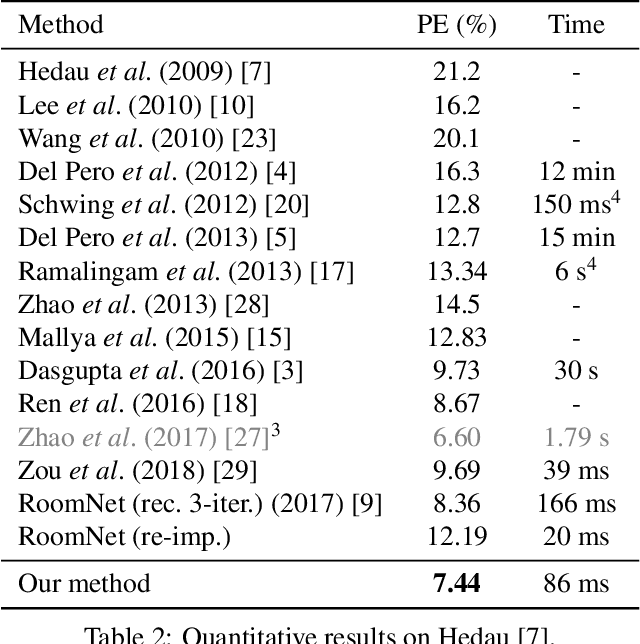
We propose a novel method to efficiently estimate the spatial layout of a room from a single monocular RGB image. As existing approaches based on low-level feature extraction, followed by a vanishing point estimation are very slow and often unreliable in realistic scenarios, we build on semantic segmentation of the input image. To obtain better segmentations, we introduce a robust, accurate and very efficient hypothesize-and-test scheme. The key idea is to use three segmentation hypotheses, each based on a different number of visible walls. For each hypothesis, we predict the image locations of the room corners and select the hypothesis for which the layout estimated from the room corners is consistent with the segmentation. We demonstrate the efficiency and robustness of our method on three challenging benchmark datasets, where we significantly outperform the state-of-the-art.
LU-Net: An Efficient Network for 3D LiDAR Point Cloud Semantic Segmentation Based on End-to-End-Learned 3D Features and U-Net
Aug 30, 2019
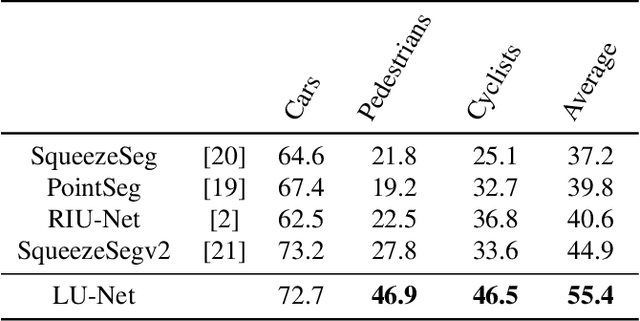

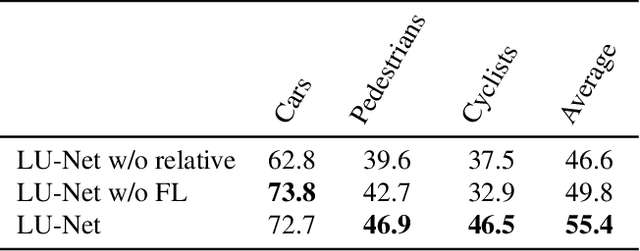
We propose LU-Net -- for LiDAR U-Net, a new method for the semantic segmentation of a 3D LiDAR point cloud. Instead of applying some global 3D segmentation method such as PointNet, we propose an end-to-end architecture for LiDAR point cloud semantic segmentation that efficiently solves the problem as an image processing problem. We first extract high-level 3D features for each point given its 3D neighbors. Then, these features are projected into a 2D multichannel range-image by considering the topology of the sensor. Thanks to these learned features and this projection, we can finally perform the segmentation using a simple U-Net segmentation network, which performs very well while being very efficient. In this way, we can exploit both the 3D nature of the data and the specificity of the LiDAR sensor. This approach outperforms the state-of-the-art by a large margin on the KITTI dataset, as our experiments show. Moreover, this approach operates at 24fps on a single GPU. This is above the acquisition rate of common LiDAR sensors which makes it suitable for real-time applications.
CorNet: Generic 3D Corners for 6D Pose Estimation of New Objects without Retraining
Aug 29, 2019
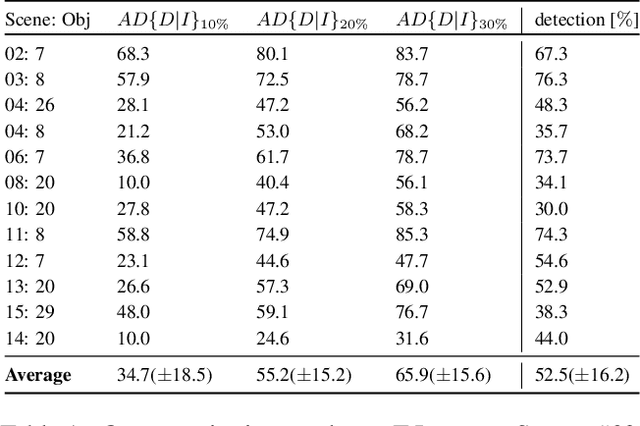
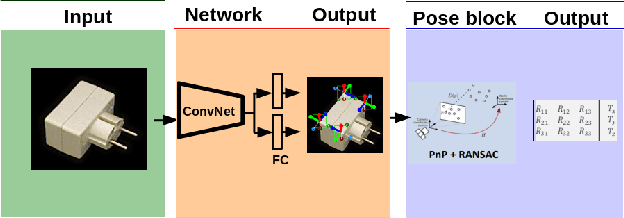
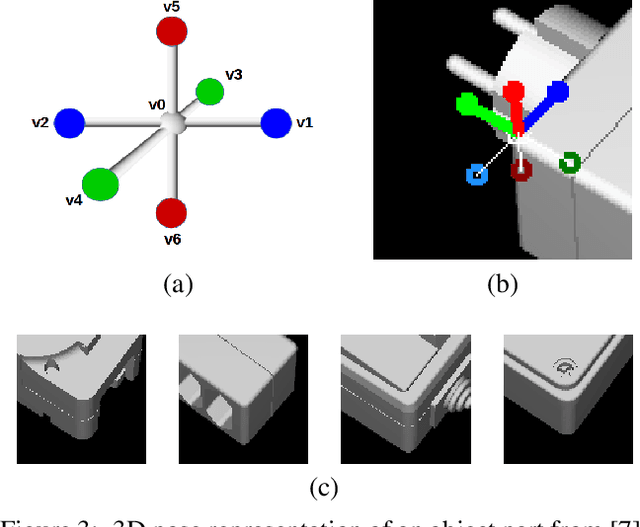
We present a novel approach to the detection and 3D pose estimation of objects in color images. Its main contribution is that it does not require any training phases nor data for new objects, while state-of-the-art methods typically require hours of training time and hundreds of training registered images. Instead, our method relies only on the objects' geometries. Our method focuses on objects with prominent corners, which covers a large number of industrial objects. We first learn to detect object corners of various shapes in images and also to predict their 3D poses, by using training images of a small set of objects. To detect a new object in a given image, we first identify its corners from its CAD model; we also detect the corners visible in the image and predict their 3D poses. We then introduce a RANSAC-like algorithm that robustly and efficiently detects and estimates the object's 3D pose by matching its corners on the CAD model with their detected counterparts in the image. Because we also estimate the 3D poses of the corners in the image, detecting only 1 or 2 corners is sufficient to estimate the pose of the object, which makes the approach robust to occlusions. We finally rely on a final check that exploits the full 3D geometry of the objects, in case multiple objects have the same corner spatial arrangement. The advantages of our approach make it particularly attractive for industrial contexts, and we demonstrate our approach on the challenging T-LESS dataset.
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
Aug 21, 2019
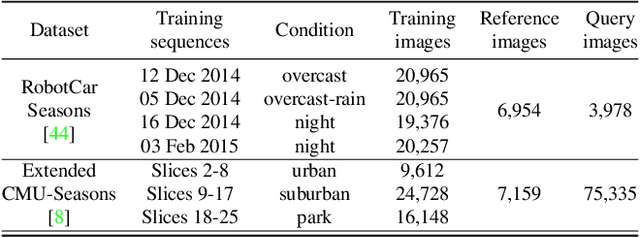
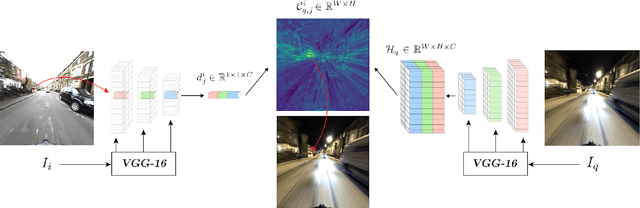
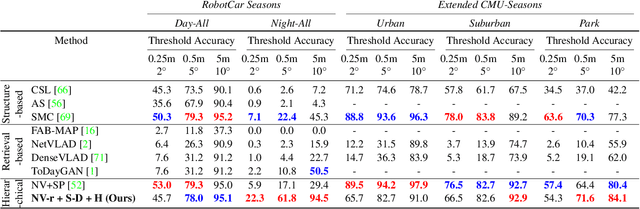
We propose a novel approach to feature point matching, suitable for robust and accurate outdoor visual localization in long-term scenarios. Given a query image, we first match it against a database of registered reference images, using recent retrieval techniques. This gives us a first estimate of the camera pose. To refine this estimate, like previous approaches, we match 2D points across the query image and the retrieved reference image. This step, however, is prone to fail as it is still very difficult to detect and match sparse feature points across images captured in potentially very different conditions. Our key contribution is to show that we need to extract sparse feature points only in the retrieved reference image: We then search for the corresponding 2D locations in the query image exhaustively. This search can be performed efficiently using convolutional operations, and robustly by using hypercolumn descriptors, i.e. image features computed for retrieval. We refer to this method as Sparse-to-Dense Hypercolumn Matching. Because we know the 3D locations of the sparse feature points in the reference images thanks to an offline reconstruction stage, it is then possible to accurately estimate the camera pose from these matches. Our experiments show that this method allows us to outperform the state-of-the-art on several challenging outdoor datasets.
On Object Symmetries and 6D Pose Estimation from Images
Aug 20, 2019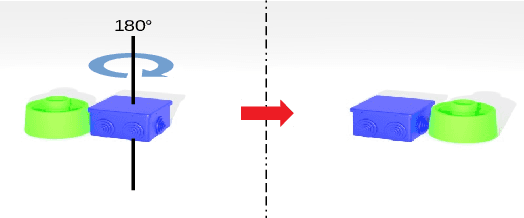
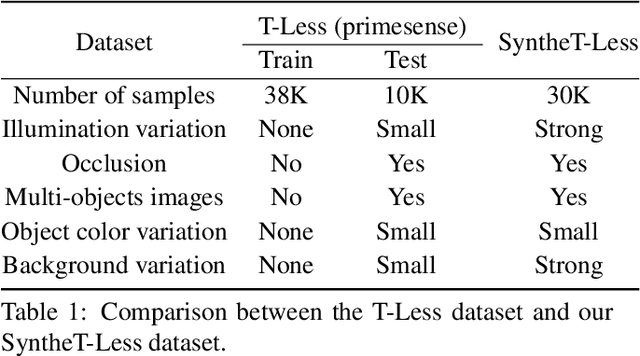
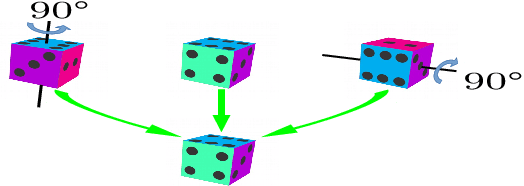
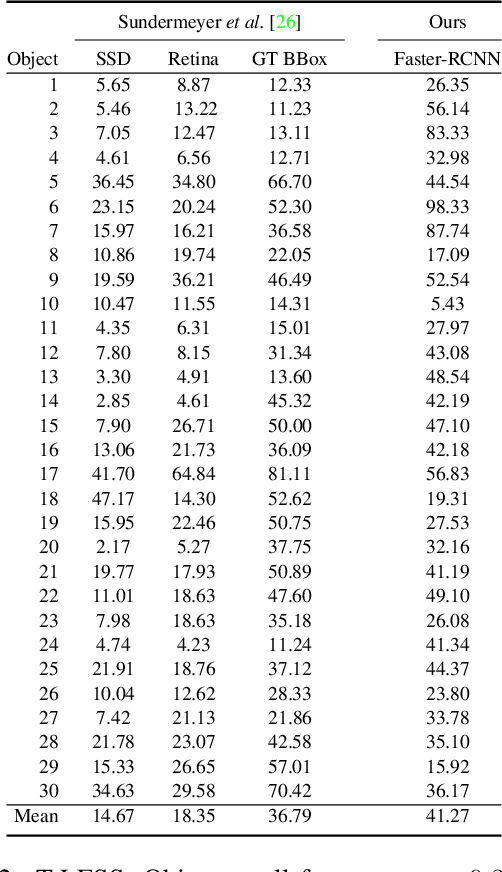
Objects with symmetries are common in our daily life and in industrial contexts, but are often ignored in the recent literature on 6D pose estimation from images. In this paper, we study in an analytical way the link between the symmetries of a 3D object and its appearance in images. We explain why symmetrical objects can be a challenge when training machine learning algorithms that aim at estimating their 6D pose from images. We propose an efficient and simple solution that relies on the normalization of the pose rotation. Our approach is general and can be used with any 6D pose estimation algorithm. Moreover, our method is also beneficial for objects that are 'almost symmetrical', i.e. objects for which only a detail breaks the symmetry. We validate our approach within a Faster-RCNN framework on a synthetic dataset made with objects from the T-Less dataset, which exhibit various types of symmetries, as well as real sequences from T-Less.
Location Field Descriptors: Single Image 3D Model Retrieval in the Wild
Aug 07, 2019
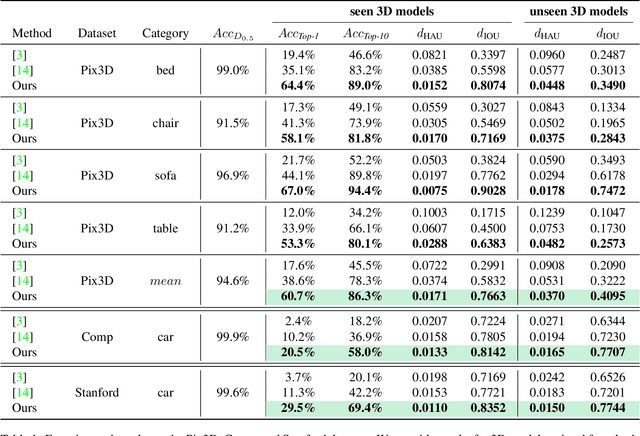
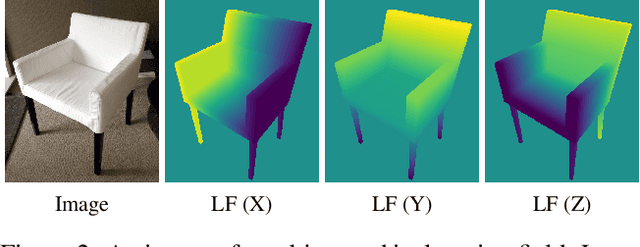
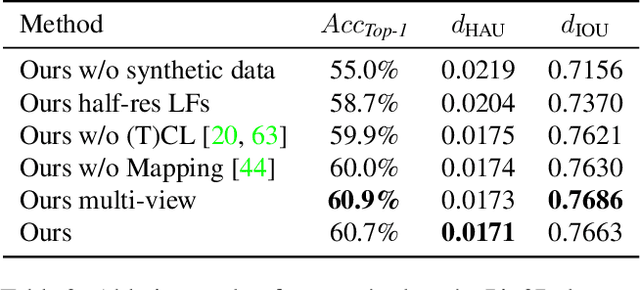
We present Location Field Descriptors, a novel approach for single image 3D model retrieval in the wild. In contrast to previous methods that directly map 3D models and RGB images to an embedding space, we establish a common low-level representation in the form of location fields from which we compute pose invariant 3D shape descriptors. Location fields encode correspondences between 2D pixels and 3D surface coordinates and, thus, explicitly capture 3D shape and 3D pose information without appearance variations which are irrelevant for the task. This early fusion of 3D models and RGB images results in three main advantages: First, the bottleneck location field prediction acts as a regularizer during training. Second, major parts of the system benefit from training on a virtually infinite amount of synthetic data. Finally, the predicted location fields are visually interpretable and unblackbox the system. We evaluate our proposed approach on three challenging real-world datasets (Pix3D, Comp, and Stanford) with different object categories and significantly outperform the state-of-the-art by up to 20% absolute in multiple 3D retrieval metrics.