 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplace-Approximated Neural Additive Models: Improving Interpretability with Bayesian Inference
May 26, 2023



Deep neural networks (DNNs) have found successful applications in many fields, but their black-box nature hinders interpretability. This is addressed by the neural additive model (NAM), in which the network is divided into additive sub-networks, thus making apparent the interaction between input features and predictions. In this paper, we approach the additive structure from a Bayesian perspective and develop a practical Laplace approximation. This enhances interpretability in three primary ways: a) It provides credible intervals for the recovered feature interactions by estimating function-space uncertainty of the sub-networks; b) it yields a tractable estimate of the marginal likelihood, which can be used to perform an implicit selection of features through an empirical Bayes procedure; and c) it can be used to rank feature pairs as candidates for second-order interactions in fine-tuned interaction models. We show empirically that our proposed Laplace-approximated NAM (LA-NAM) improves performance and interpretability on tabular regression and classification datasets and challenging real-world medical tasks.
Promises and Pitfalls of the Linearized Laplace in Bayesian Optimization
Apr 17, 2023



The linearized-Laplace approximation (LLA) has been shown to be effective and efficient in constructing Bayesian neural networks. It is theoretically compelling since it can be seen as a Gaussian process posterior with the mean function given by the neural network's maximum-a-posteriori predictive function and the covariance function induced by the empirical neural tangent kernel. However, while its efficacy has been studied in large-scale tasks like image classification, it has not been studied in sequential decision-making problems like Bayesian optimization where Gaussian processes -- with simple mean functions and kernels such as the radial basis function -- are the de-facto surrogate models. In this work, we study the usefulness of the LLA in Bayesian optimization and highlight its strong performance and flexibility. However, we also present some pitfalls that might arise and a potential problem with the LLA when the search space is unbounded.
Incorporating Unlabelled Data into Bayesian Neural Networks
Apr 04, 2023We develop a contrastive framework for learning better prior distributions for Bayesian Neural Networks (BNNs) using unlabelled data. With this framework, we propose a practical BNN algorithm that offers the label-efficiency of self-supervised learning and the principled uncertainty estimates of Bayesian methods. Finally, we demonstrate the advantages of our approach for data-efficient learning in semi-supervised and low-budget active learning problems.
PAC-Bayesian Meta-Learning: From Theory to Practice
Nov 14, 2022Meta-Learning aims to accelerate the learning on new tasks by acquiring useful inductive biases from related data sources. In practice, the number of tasks available for meta-learning is often small. Yet, most of the existing approaches rely on an abundance of meta-training tasks, making them prone to overfitting. How to regularize the meta-learner to ensure generalization to unseen tasks, is a central question in the literature. We provide a theoretical analysis using the PAC-Bayesian framework and derive the first bound for meta-learners with unbounded loss functions. Crucially, our bounds allow us to derive the PAC-optimal hyper-posterior (PACOH) - the closed-form-solution of the PAC-Bayesian meta-learning problem, thereby avoiding the reliance on nested optimization, giving rise to an optimization problem amenable to standard variational methods that scale well. Our experiments show that, when instantiating the PACOH with Gaussian processes and Bayesian Neural Networks as base learners, the resulting methods are more scalable, and yield state-of-the-art performance, both in terms of predictive accuracy and the quality of uncertainty estimates. Finally, thanks to the principled treatment of uncertainty, our meta-learners can also be successfully employed for sequential decision problems.
Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations
Feb 22, 2022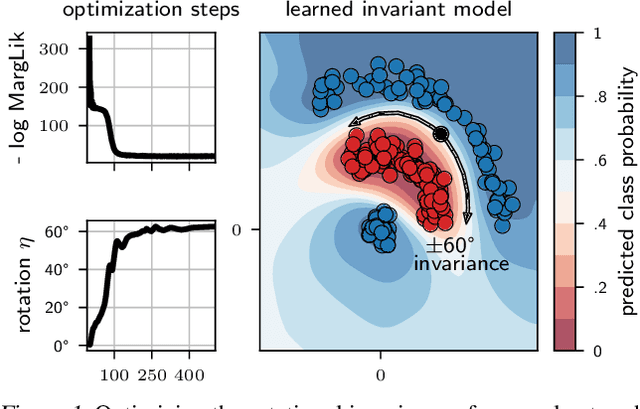
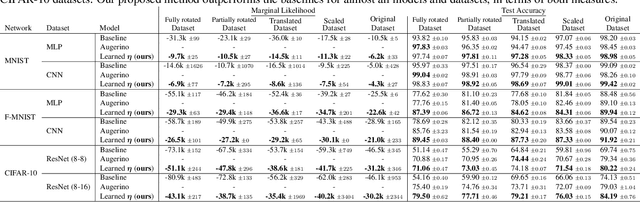
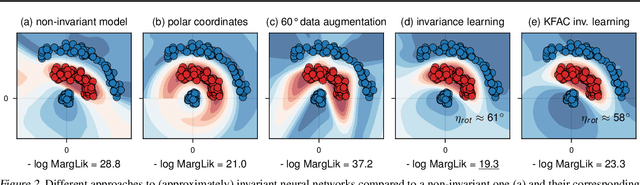

Data augmentation is commonly applied to improve performance of deep learning by enforcing the knowledge that certain transformations on the input preserve the output. Currently, the correct data augmentation is chosen by human effort and costly cross-validation, which makes it cumbersome to apply to new datasets. We develop a convenient gradient-based method for selecting the data augmentation. Our approach relies on phrasing data augmentation as an invariance in the prior distribution and learning it using Bayesian model selection, which has been shown to work in Gaussian processes, but not yet for deep neural networks. We use a differentiable Kronecker-factored Laplace approximation to the marginal likelihood as our objective, which can be optimised without human supervision or validation data. We show that our method can successfully recover invariances present in the data, and that this improves generalisation on image datasets.
Probing as Quantifying the Inductive Bias of Pre-trained Representations
Oct 15, 2021Pre-trained contextual representations have led to dramatic performance improvements on a range of downstream tasks. This has motivated researchers to quantify and understand the linguistic information encoded in them. In general, this is done by probing, which consists of training a supervised model to predict a linguistic property from said representations. Unfortunately, this definition of probing has been subject to extensive criticism, and can lead to paradoxical or counter-intuitive results. In this work, we present a novel framework for probing where the goal is to evaluate the inductive bias of representations for a particular task, and provide a practical avenue to do this using Bayesian inference. We apply our framework to a series of token-, arc-, and sentence-level tasks. Our results suggest that our framework solves problems of previous approaches and that fastText can offer a better inductive bias than BERT in certain situations.
Pathologies in priors and inference for Bayesian transformers
Oct 15, 2021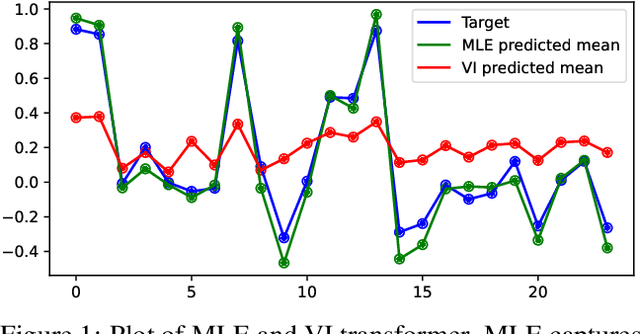
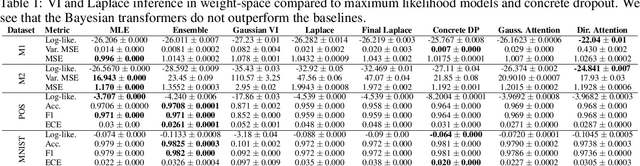


In recent years, the transformer has established itself as a workhorse in many applications ranging from natural language processing to reinforcement learning. Similarly, Bayesian deep learning has become the gold-standard for uncertainty estimation in safety-critical applications, where robustness and calibration are crucial. Surprisingly, no successful attempts to improve transformer models in terms of predictive uncertainty using Bayesian inference exist. In this work, we study this curiously underpopulated area of Bayesian transformers. We find that weight-space inference in transformers does not work well, regardless of the approximate posterior. We also find that the prior is at least partially at fault, but that it is very hard to find well-specified weight priors for these models. We hypothesize that these problems stem from the complexity of obtaining a meaningful mapping from weight-space to function-space distributions in the transformer. Therefore, moving closer to function-space, we propose a novel method based on the implicit reparameterization of the Dirichlet distribution to apply variational inference directly to the attention weights. We find that this proposed method performs competitively with our baselines.
Sparse MoEs meet Efficient Ensembles
Oct 07, 2021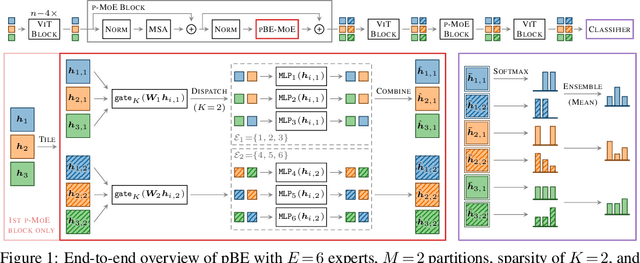

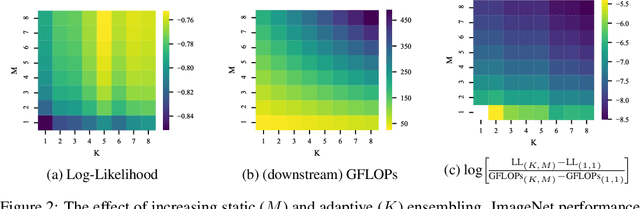
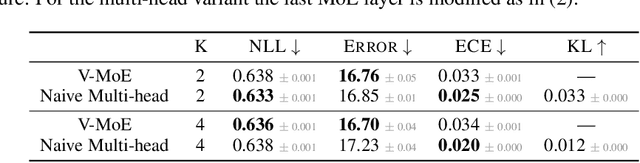
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, lead to strong performance. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that these two approaches have complementary features whose combination is beneficial. Then, we present partitioned batch ensembles, an efficient ensemble of sparse MoEs that takes the best of both classes of models. Extensive experiments on fine-tuned vision transformers demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty calibration improvements of our approach over several challenging baselines. Partitioned batch ensembles not only scale to models with up to 2.7B parameters, but also provide larger performance gains for larger models.
Deep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021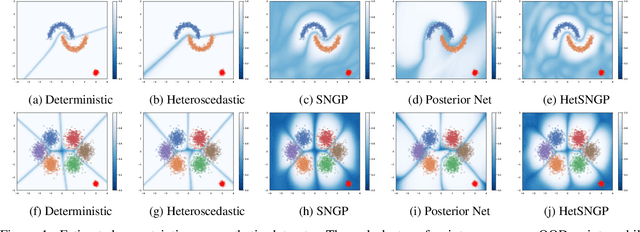



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
Neural Variational Gradient Descent
Jul 29, 2021
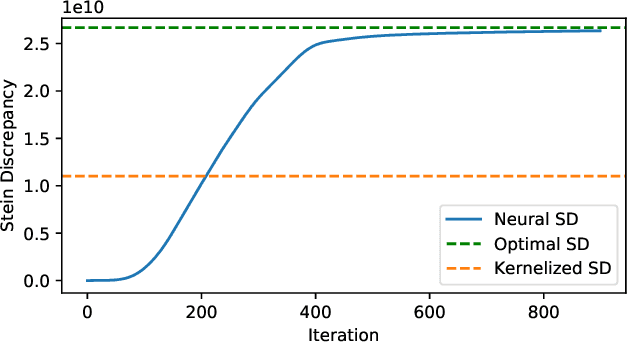
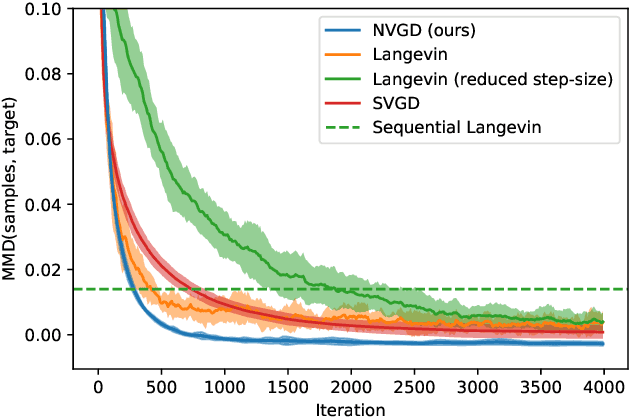
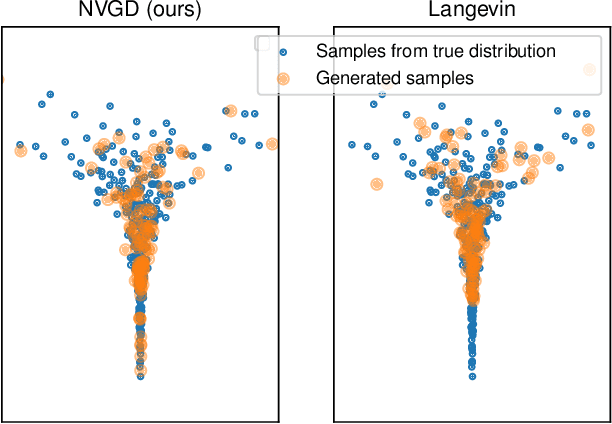
Particle-based approximate Bayesian inference approaches such as Stein Variational Gradient Descent (SVGD) combine the flexibility and convergence guarantees of sampling methods with the computational benefits of variational inference. In practice, SVGD relies on the choice of an appropriate kernel function, which impacts its ability to model the target distribution -- a challenging problem with only heuristic solutions. We propose Neural Variational Gradient Descent (NVGD), which is based on parameterizing the witness function of the Stein discrepancy by a deep neural network whose parameters are learned in parallel to the inference, mitigating the necessity to make any kernel choices whatsoever. We empirically evaluate our method on popular synthetic inference problems, real-world Bayesian linear regression, and Bayesian neural network inference.