 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSP-Laplace: Function-Space Priors for the Laplace Approximation in Bayesian Deep Learning
Jul 18, 2024



Laplace approximations are popular techniques for endowing deep networks with epistemic uncertainty estimates as they can be applied without altering the predictions of the neural network, and they scale to large models and datasets. While the choice of prior strongly affects the resulting posterior distribution, computational tractability and lack of interpretability of weight space typically limit the Laplace approximation to isotropic Gaussian priors, which are known to cause pathological behavior as depth increases. As a remedy, we directly place a prior on function space. More precisely, since Lebesgue densities do not exist on infinite-dimensional function spaces, we have to recast training as finding the so-called weak mode of the posterior measure under a Gaussian process (GP) prior restricted to the space of functions representable by the neural network. Through the GP prior, one can express structured and interpretable inductive biases, such as regularity or periodicity, directly in function space, while still exploiting the implicit inductive biases that allow deep networks to generalize. After model linearization, the training objective induces a negative log-posterior density to which we apply a Laplace approximation, leveraging highly scalable methods from matrix-free linear algebra. Our method provides improved results where prior knowledge is abundant, e.g., in many scientific inference tasks. At the same time, it stays competitive for black-box regression and classification tasks where neural networks typically excel.
Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks
Jun 06, 2024



Bayesian neural networks (BNN) promise to combine the predictive performance of neural networks with principled uncertainty modeling important for safety-critical systems and decision making. However, posterior uncertainty estimates depend on the choice of prior, and finding informative priors in weight-space has proven difficult. This has motivated variational inference (VI) methods that pose priors directly on the function generated by the BNN rather than on weights. In this paper, we address a fundamental issue with such function-space VI approaches pointed out by Burt et al. (2020), who showed that the objective function (ELBO) is negative infinite for most priors of interest. Our solution builds on generalized VI (Knoblauch et al., 2019) with the regularized KL divergence (Quang, 2019) and is, to the best of our knowledge, the first well-defined variational objective for function-space inference in BNNs with Gaussian process (GP) priors. Experiments show that our method incorporates the properties specified by the GP prior on synthetic and small real-world data sets, and provides competitive uncertainty estimates for regression, classification and out-of-distribution detection compared to BNN baselines with both function and weight-space priors.
Variational Boosted Soft Trees
Feb 22, 2023Gradient boosting machines (GBMs) based on decision trees consistently demonstrate state-of-the-art results on regression and classification tasks with tabular data, often outperforming deep neural networks. However, these models do not provide well-calibrated predictive uncertainties, which prevents their use for decision making in high-risk applications. The Bayesian treatment is known to improve predictive uncertainty calibration, but previously proposed Bayesian GBM methods are either computationally expensive, or resort to crude approximations. Variational inference is often used to implement Bayesian neural networks, but is difficult to apply to GBMs, because the decision trees used as weak learners are non-differentiable. In this paper, we propose to implement Bayesian GBMs using variational inference with soft decision trees, a fully differentiable alternative to standard decision trees introduced by Irsoy et al. Our experiments demonstrate that variational soft trees and variational soft GBMs provide useful uncertainty estimates, while retaining good predictive performance. The proposed models show higher test likelihoods when compared to the state-of-the-art Bayesian GBMs in 7/10 tabular regression datasets and improved out-of-distribution detection in 5/10 datasets.
Pathologies in priors and inference for Bayesian transformers
Oct 15, 2021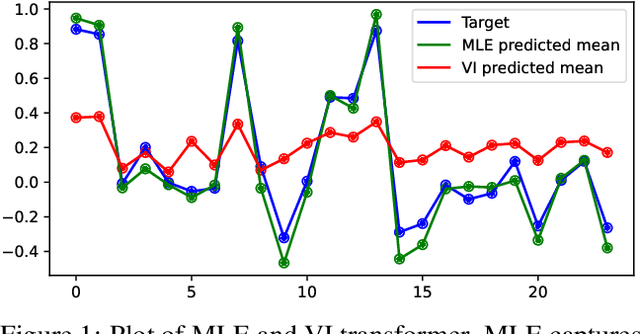
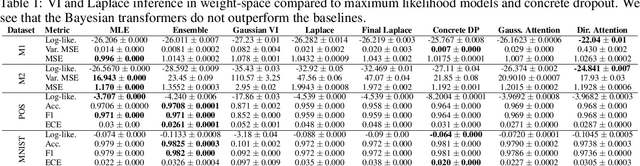


In recent years, the transformer has established itself as a workhorse in many applications ranging from natural language processing to reinforcement learning. Similarly, Bayesian deep learning has become the gold-standard for uncertainty estimation in safety-critical applications, where robustness and calibration are crucial. Surprisingly, no successful attempts to improve transformer models in terms of predictive uncertainty using Bayesian inference exist. In this work, we study this curiously underpopulated area of Bayesian transformers. We find that weight-space inference in transformers does not work well, regardless of the approximate posterior. We also find that the prior is at least partially at fault, but that it is very hard to find well-specified weight priors for these models. We hypothesize that these problems stem from the complexity of obtaining a meaningful mapping from weight-space to function-space distributions in the transformer. Therefore, moving closer to function-space, we propose a novel method based on the implicit reparameterization of the Dirichlet distribution to apply variational inference directly to the attention weights. We find that this proposed method performs competitively with our baselines.