 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient based Bilevel for Inverse Optimal Control, a Riemannian approach
Jun 09, 2026Inverse Optimal Control (IOC) aims to recover the cost function that explains observed trajectories as solutions of an optimal control problem. Classical IOC formulations rely on bilevel optimization, which repeatedly solves a nested optimal control problem and quickly becomes computationally prohibitive for realistic systems. Recent projection-based approaches offer a promising alternative but suffer from numerical instability when solved with gradient-based methods due to violations of standard constraint qualifications. In this paper, we show that these difficulties stem from the geometric structure of the IOC feasible set. We demonstrate that the set of trajectories satisfying the optimality conditions naturally forms a manifold and reformulate IOC as an optimization problem on this manifold. Based on this insight, we propose a Riemannian Inverse Optimal Control (RIOC) method that projects observed trajectories onto the manifold of optimal solutions while preserving feasibility by construction. Experiments on real human arm trajectories show that the proposed method achieves comparable or better reconstruction accuracy than classical bilevel IOC while reducing computation time by about a factor of four. These results highlight the potential of geometric optimization methods to improve the scalability and reliability of IOC for robotics and human motion analysis.
COSMIK-MPPI: Scaling Constrained Model Predictive Control to Collision Avoidance in Close-Proximity Dynamic Human Environments
Apr 11, 2026Ensuring safe physical interaction between torque-controlled manipulators and humans is essential for deploying robots in everyday environments. Model Predictive Control (MPC) has emerged as a suitable framework thanks to its capacity to handle hard constraints, provide strong guarantees and zero-shot adaptability through predictive reasoning. However, Gradient-Based MPC (GB-MPC) solvers have demonstrated limited performance for collision avoidance in complex environments. Sampling-based approaches such as Model Predictive Path Integral (MPPI) control offer an alternative via stochastic rollouts, but enforcing safety via additive penalties is inherently fragile, as it provides no formal constraint satisfaction guarantees. We propose a collision avoidance framework called COSMIK-MPPI combining MPPI with the toolbox for human motion estimation RT-COSMIK and the Constraints-as-Terminations transcription, which enforces safety by treating constraint violations as terminal events, without relying on large penalty terms or explicit human motion prediction. The proposed approach is evaluated against state-of-the-art GB-MPC and vanilla MPPI in simulation and on a real manipulator arm. Results show that COSMIK-MPPI achieves a 100% task success rate with a constant computation time (22 ms), largely outperforming GB-MPC. In simulated infeasible scenarios, COSMIK-MPPI consistently generates collision-free trajectories, contrary to vanilla MPPI. These properties enabled safe execution of complex real-world human-robot interaction tasks in shared workspaces using an affordable markerless human motion estimator, demonstrating a robust, compliant, and practical solution for predictive collision avoidance (cf. results showcased at https://exquisite-parfait-ffa925.netlify.app)
Learning-Guided Force-Feedback Model Predictive Control with Obstacle Avoidance for Robotic Deburring
Apr 07, 2026Model Predictive Control (MPC) is widely used for torque-controlled robots, but classical formulations often neglect real-time force feedback and struggle with contact-rich industrial tasks under collision constraints. Deburring in particular requires precise tool insertion, stable force regulation, and collision-free circular motions in challenging configurations, which exceeds the capability of standard MPC pipelines. We propose a framework that integrates force-feedback MPC with diffusion-based motion priors to address these challenges. The diffusion model serves as a memory of motion strategies, providing robust initialization and adaptation across multiple task instances, while MPC ensures safe execution with explicit force tracking, torque feasibility, and collision avoidance. We validate our approach on a torque-controlled manipulator performing industrial deburring tasks. Experiments demonstrate reliable tool insertion, accurate normal force tracking, and circular deburring motions even in hard-to-reach configurations and under obstacle constraints. To our knowledge, this is the first integration of diffusion motion priors with force-feedback MPC for collision-aware, contact-rich industrial tasks.
Toward Global Intent Inference for Human Motion by Inverse Reinforcement Learning
Mar 08, 2026This paper investigates whether a single, unified cost function can explain and predict human reaching movements, in contrast with existing approaches that rely on subject- or posture-specific optimization criteria. Using the Minimal Observation Inverse Reinforcement Learning (MO-IRL) algorithm, together with a seven-dimensional set of candidate cost terms, we efficiently estimate time-varying cost weights for a standard planar reaching task. MO-IRL provides orders-of-magnitude faster convergence than bilevel formulations, while using only a fraction of the available data, enabling the practical exploration of time-varying cost structures. Three levels of generality are evaluated: Subject-Dependent Posture-Dependent, Subject-Dependent Posture-Independent, and Subject-Independent Posture-Independent. Across all cases, time-varying weights substantially improve trajectory reconstruction, yielding an average 27% reduction in RMSE compared to the baseline. The inferred costs consistently highlight a dominant role for joint-acceleration regulation, complemented by smaller contributions from torque-change smoothness. Overall, a single subject- and posture-agnostic time-varying cost function is shown to predict human reaching trajectories with high accuracy, supporting the existence of a unified optimality principle governing this class of movements.
Adapted Pepper
Sep 08, 2020
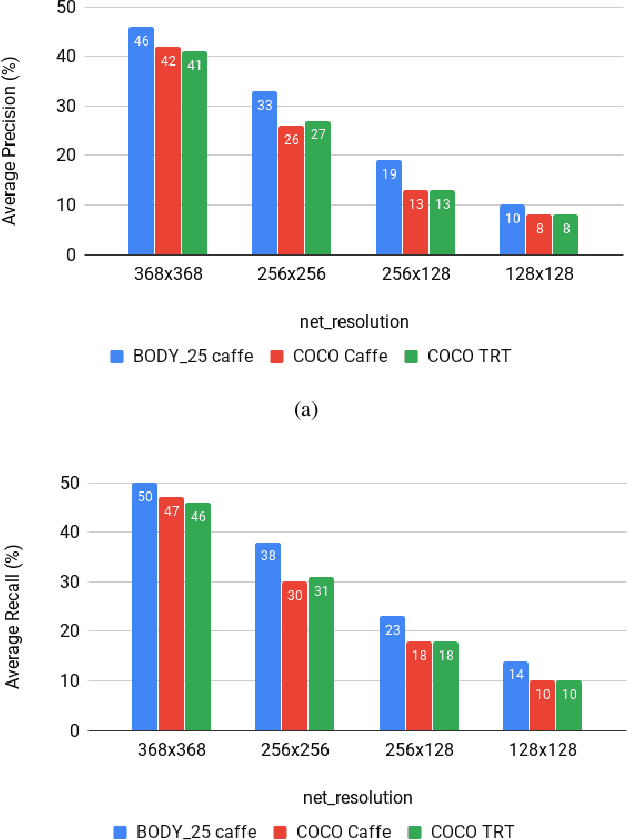
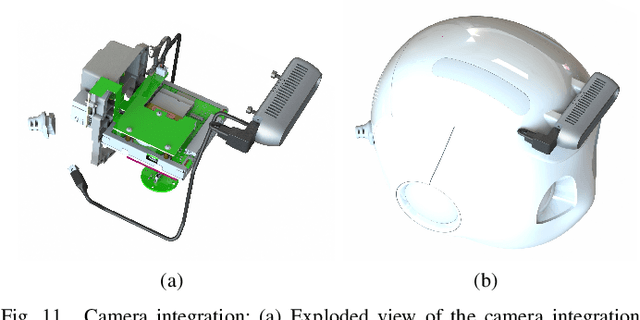
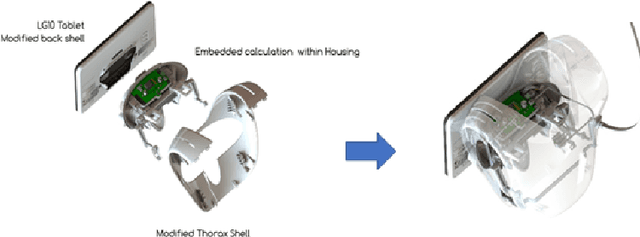
One of the main issue in robotics is the lack of embedded computational power. Recently, state of the art algorithms providing a better understanding of the surroundings (Object detection, skeleton tracking, etc.) are requiring more and more computational power. The lack of embedded computational power is more significant in mass-produced robots because of the difficulties to follow the increasing computational requirements of state of the art algorithms. The integration of an additional GPU allows to overcome this lack of embedded computational power. We introduce in this paper a prototype of Pepper with an embedded GPU, but also with an additional 3D camera on the head of the robot and plugged to the late GPU. This prototype, called Adapted Pepper, was built for the European project called MuMMER (MultiModal Mall Entertainment Robot) in order to embed algorithms like OpenPose, YOLO or to process sensors information and, in all cases, avoid network dependency for deported computation.