 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlankton-FL: Exploration of Federated Learning for Privacy-Preserving Training of Deep Neural Networks for Phytoplankton Classification
Dec 18, 2022



Creating high-performance generalizable deep neural networks for phytoplankton monitoring requires utilizing large-scale data coming from diverse global water sources. A major challenge to training such networks lies in data privacy, where data collected at different facilities are often restricted from being transferred to a centralized location. A promising approach to overcome this challenge is federated learning, where training is done at site level on local data, and only the model parameters are exchanged over the network to generate a global model. In this study, we explore the feasibility of leveraging federated learning for privacy-preserving training of deep neural networks for phytoplankton classification. More specifically, we simulate two different federated learning frameworks, federated learning (FL) and mutually exclusive FL (ME-FL), and compare their performance to a traditional centralized learning (CL) framework. Experimental results from this study demonstrate the feasibility and potential of federated learning for phytoplankton monitoring.
SMPL-IK: Learned Morphology-Aware Inverse Kinematics for AI Driven Artistic Workflows
Aug 16, 2022
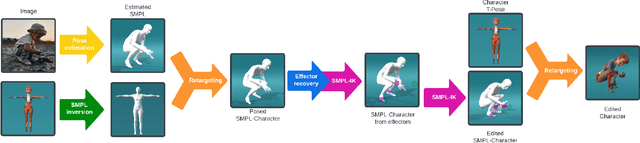


Inverse Kinematics (IK) systems are often rigid with respect to their input character, thus requiring user intervention to be adapted to new skeletons. In this paper we aim at creating a flexible, learned IK solver applicable to a wide variety of human morphologies. We extend a state-of-the-art machine learning IK solver to operate on the well known Skinned Multi-Person Linear model (SMPL). We call our model SMPL-IK, and show that when integrated into real-time 3D software, this extended system opens up opportunities for defining novel AI-assisted animation workflows. For example, pose authoring can be made more flexible with SMPL-IK by allowing users to modify gender and body shape while posing a character. Additionally, when chained with existing pose estimation algorithms, SMPL-IK accelerates posing by allowing users to bootstrap 3D scenes from 2D images while allowing for further editing. Finally, we propose a novel SMPL Shape Inversion mechanism (SMPL-SI) to map arbitrary humanoid characters to the SMPL space, allowing artists to leverage SMPL-IK on custom characters. In addition to qualitative demos showing proposed tools, we present quantitative SMPL-IK baselines on the H36M and AMASS datasets.
Towards Generating Large Synthetic Phytoplankton Datasets for Efficient Monitoring of Harmful Algal Blooms
Aug 03, 2022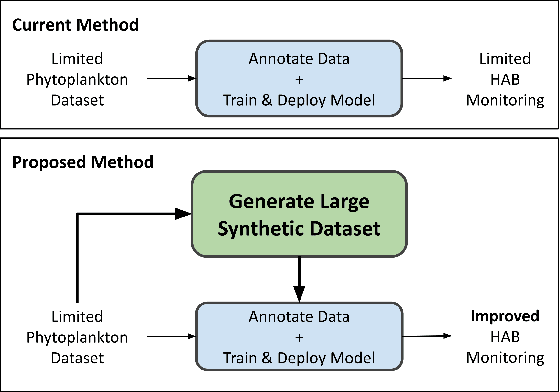
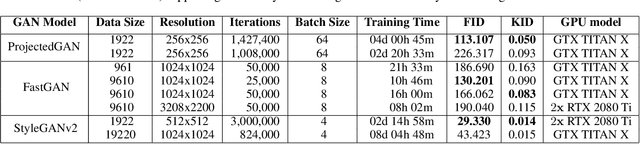


Climate change is increasing the frequency and severity of harmful algal blooms (HABs), which cause significant fish deaths in aquaculture farms. This contributes to ocean pollution and greenhouse gas (GHG) emissions since dead fish are either dumped into the ocean or taken to landfills, which in turn negatively impacts the climate. Currently, the standard method to enumerate harmful algae and other phytoplankton is to manually observe and count them under a microscope. This is a time-consuming, tedious and error-prone process, resulting in compromised management decisions by farmers. Hence, automating this process for quick and accurate HAB monitoring is extremely helpful. However, this requires large and diverse datasets of phytoplankton images, and such datasets are hard to produce quickly. In this work, we explore the feasibility of generating novel high-resolution photorealistic synthetic phytoplankton images, containing multiple species in the same image, given a small dataset of real images. To this end, we employ Generative Adversarial Networks (GANs) to generate synthetic images. We evaluate three different GAN architectures: ProjectedGAN, FastGAN, and StyleGANv2 using standard image quality metrics. We empirically show the generation of high-fidelity synthetic phytoplankton images using a training dataset of only 961 real images. Thus, this work demonstrates the ability of GANs to create large synthetic datasets of phytoplankton from small training datasets, accomplishing a key step towards sustainable systematic monitoring of harmful algal blooms.
MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation
May 30, 2022
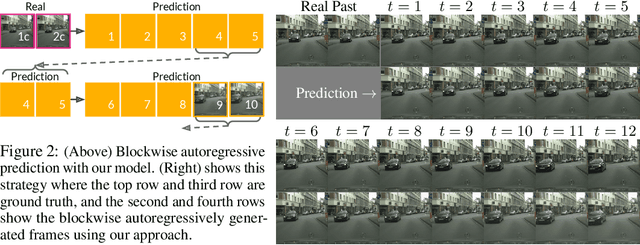
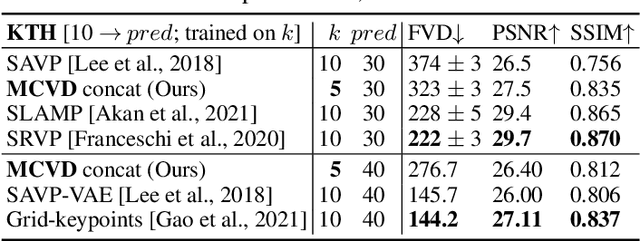
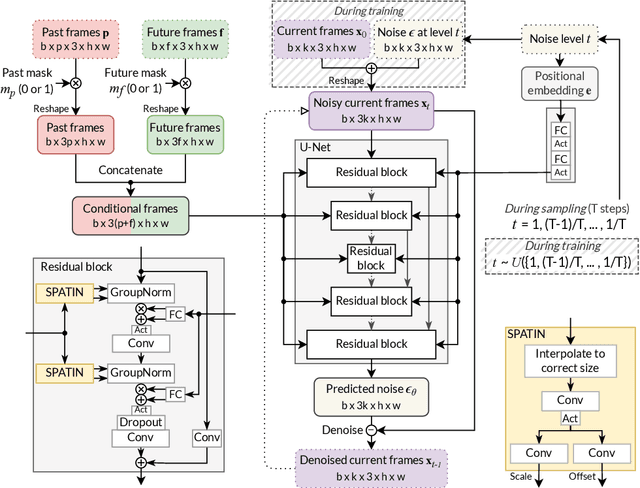
Video prediction is a challenging task. The quality of video frames from current state-of-the-art (SOTA) generative models tends to be poor and generalization beyond the training data is difficult. Furthermore, existing prediction frameworks are typically not capable of simultaneously handling other video-related tasks such as unconditional generation or interpolation. In this work, we devise a general-purpose framework called Masked Conditional Video Diffusion (MCVD) for all of these video synthesis tasks using a probabilistic conditional score-based denoising diffusion model, conditioned on past and/or future frames. We train the model in a manner where we randomly and independently mask all the past frames or all the future frames. This novel but straightforward setup allows us to train a single model that is capable of executing a broad range of video tasks, specifically: future/past prediction -- when only future/past frames are masked; unconditional generation -- when both past and future frames are masked; and interpolation -- when neither past nor future frames are masked. Our experiments show that this approach can generate high-quality frames for diverse types of videos. Our MCVD models are built from simple non-recurrent 2D-convolutional architectures, conditioning on blocks of frames and generating blocks of frames. We generate videos of arbitrary lengths autoregressively in a block-wise manner. Our approach yields SOTA results across standard video prediction and interpolation benchmarks, with computation times for training models measured in 1-12 days using $\le$ 4 GPUs. Project page: https://mask-cond-video-diffusion.github.io ; Code : https://github.com/voletiv/mcvd-pytorch
Simple Video Generation using Neural ODEs
Sep 07, 2021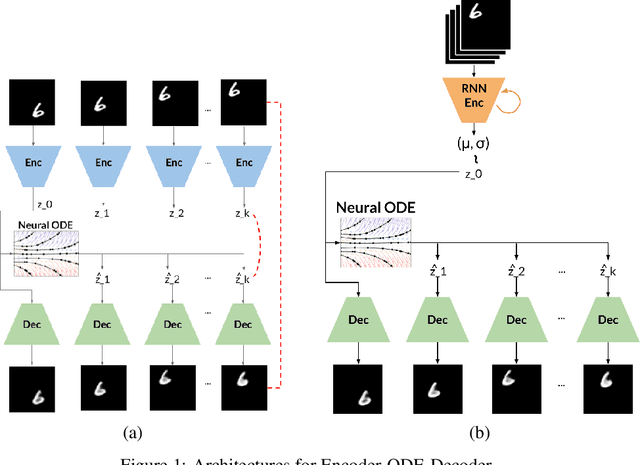
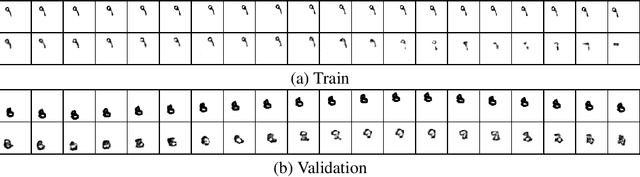
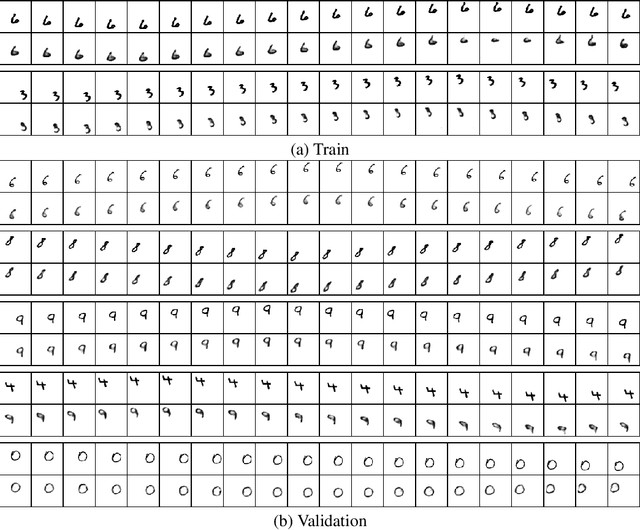
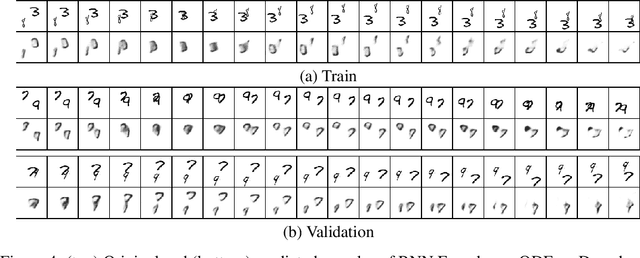
Despite having been studied to a great extent, the task of conditional generation of sequences of frames, or videos, remains extremely challenging. It is a common belief that a key step towards solving this task resides in modelling accurately both spatial and temporal information in video signals. A promising direction to do so has been to learn latent variable models that predict the future in latent space and project back to pixels, as suggested in recent literature. Following this line of work and building on top of a family of models introduced in prior work, Neural ODE, we investigate an approach that models time-continuous dynamics over a continuous latent space with a differential equation with respect to time. The intuition behind this approach is that these trajectories in latent space could then be extrapolated to generate video frames beyond the time steps for which the model is trained. We show that our approach yields promising results in the task of future frame prediction on the Moving MNIST dataset with 1 and 2 digits.
* 8 pages, 4 figures, NeurIPS 2019 workshop
SALT: Sea lice Adaptive Lattice Tracking -- An Unsupervised Approach to Generate an Improved Ocean Model
Jun 24, 2021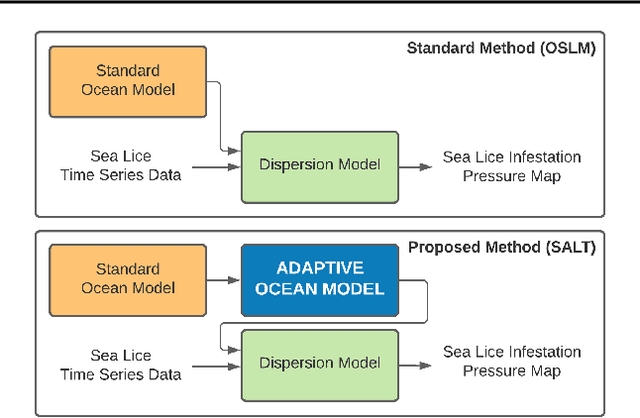
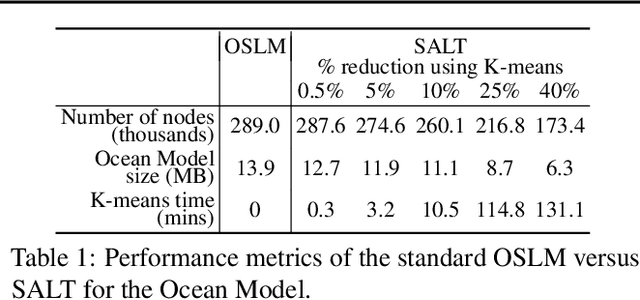
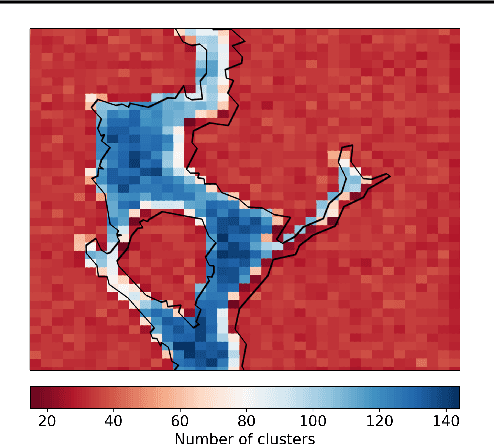
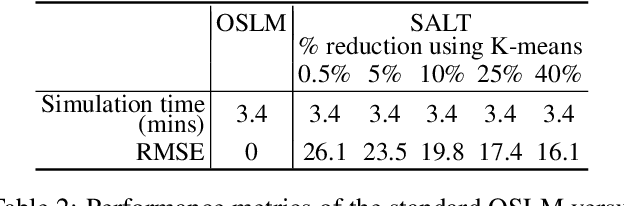
Warming oceans due to climate change are leading to increased numbers of ectoparasitic copepods, also known as sea lice, which can cause significant ecological loss to wild salmon populations and major economic loss to aquaculture sites. The main transport mechanism driving the spread of sea lice populations are near-surface ocean currents. Present strategies to estimate the distribution of sea lice larvae are computationally complex and limit full-scale analysis. Motivated to address this challenge, we propose SALT: Sea lice Adaptive Lattice Tracking approach for efficient estimation of sea lice dispersion and distribution in space and time. Specifically, an adaptive spatial mesh is generated by merging nodes in the lattice graph of the Ocean Model based on local ocean properties, thus enabling highly efficient graph representation. SALT demonstrates improved efficiency while maintaining consistent results with the standard method, using near-surface current data for Hardangerfjord, Norway. The proposed SALT technique shows promise for enhancing proactive aquaculture management through predictive modelling of sea lice infestation pressure maps in a changing climate.
Multi-Resolution Continuous Normalizing Flows
Jun 22, 2021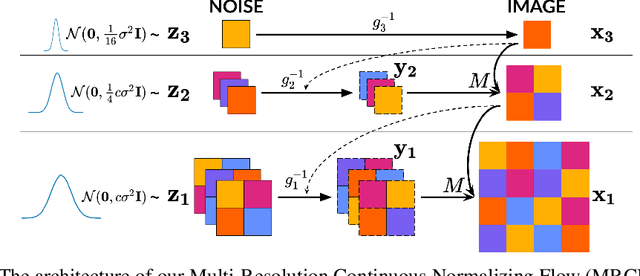
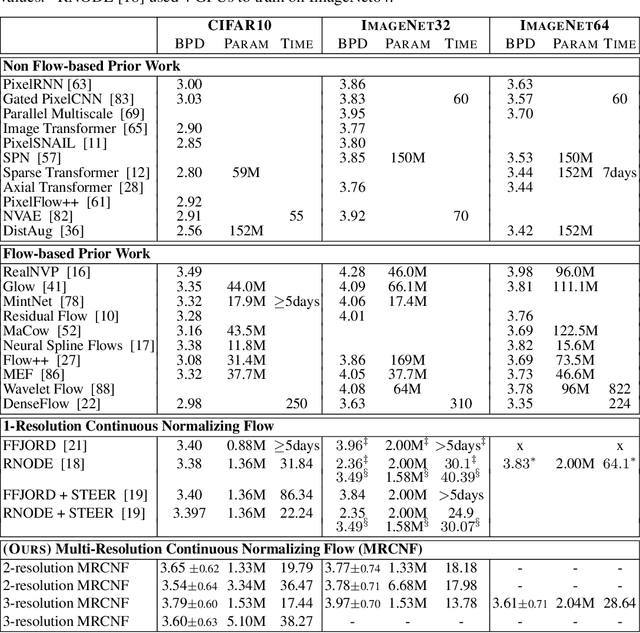
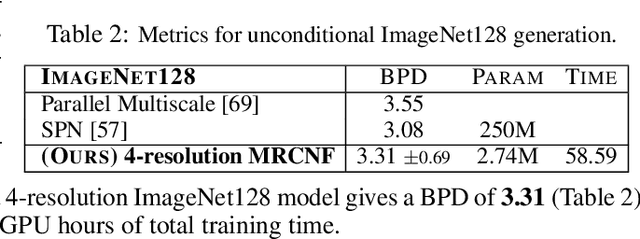

Recent work has shown that Neural Ordinary Differential Equations (ODEs) can serve as generative models of images using the perspective of Continuous Normalizing Flows (CNFs). Such models offer exact likelihood calculation, and invertible generation/density estimation. In this work we introduce a Multi-Resolution variant of such models (MRCNF), by characterizing the conditional distribution over the additional information required to generate a fine image that is consistent with the coarse image. We introduce a transformation between resolutions that allows for no change in the log likelihood. We show that this approach yields comparable likelihood values for various image datasets, with improved performance at higher resolutions, with fewer parameters, using only 1 GPU. Further, we examine the out-of-distribution properties of (Multi-Resolution) Continuous Normalizing Flows, and find that they are similar to those of other likelihood-based generative models.
Improved Predictive Uncertainty using Corruption-based Calibration
Jun 07, 2021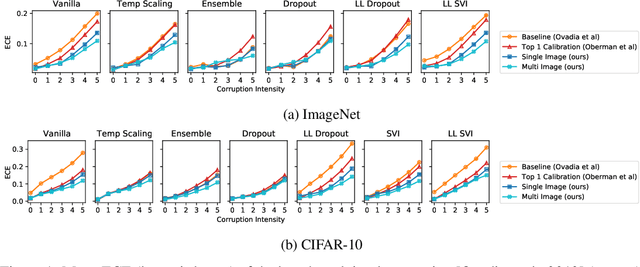
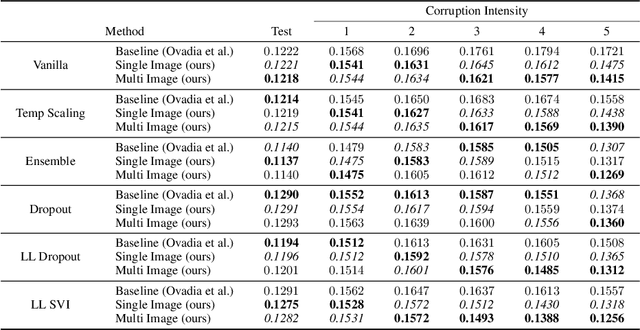
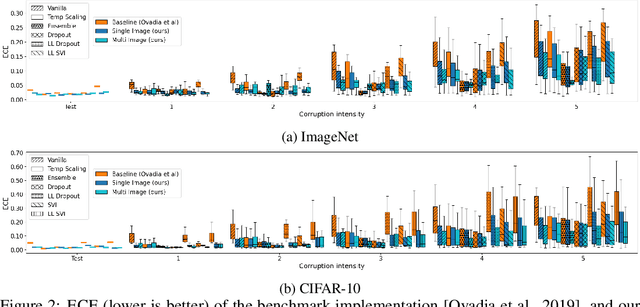
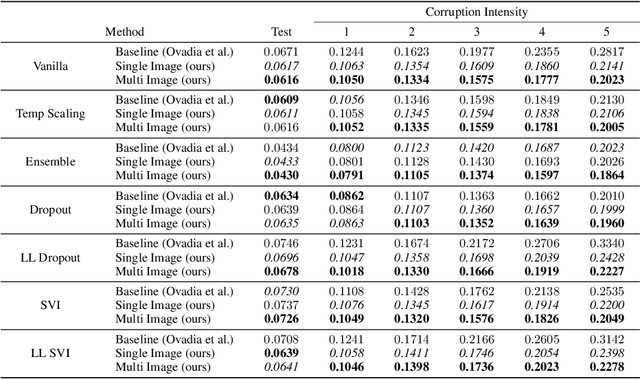
We propose a simple post hoc calibration method to estimate the confidence/uncertainty that a model prediction is correct on data with covariate shift, as represented by the large-scale corrupted data benchmark [Ovadia et al, 2019]. We achieve this by synthesizing surrogate calibration sets by corrupting the calibration set with varying intensities of a known corruption. Our method demonstrates significant improvements on the benchmark on a wide range of covariate shifts.
Bias Mitigation of Face Recognition Models Through Calibration
Jun 07, 2021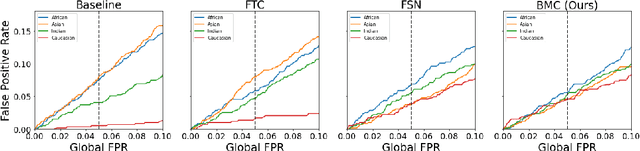

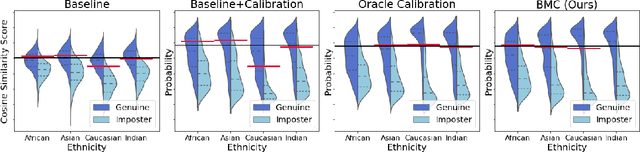
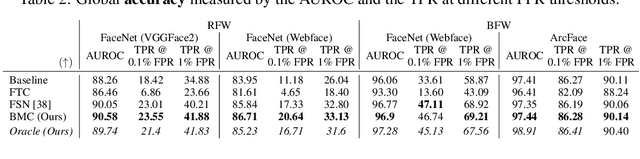
Face recognition models suffer from bias: for example, the probability of a false positive (incorrect face match) strongly depends on sensitive attributes like ethnicity. As a result, these models may disproportionately and negatively impact minority groups when used in law enforcement. In this work, we introduce the Bias Mitigation Calibration (BMC) method, which (i) increases model accuracy (improving the state-of-the-art), (ii) produces fairly-calibrated probabilities, (iii) significantly reduces the gap in the false positive rates, and (iv) does not require knowledge of the sensitive attribute.
gradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
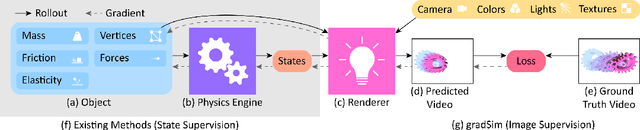
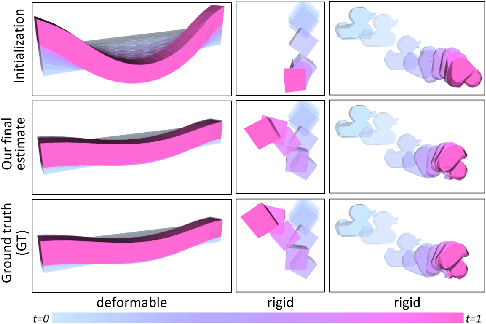

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.