 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhases of Muon: When Muon Eclipses SignSGD
May 10, 2026Recently, Muon and related spectral optimizers have demonstrated strong empirical performance as scalable stochastic methods, often outperforming Adam. Yet their behaviour remains poorly understood. We analyze stochastic spectral optimizers, including Muon, on a high-dimensional matrix-valued least squares problem. We derive explicit deterministic dynamics that provide a tractable framework for studying learning behaviour with a focus on (stochastic) SignSVD, which Muon approximates, and (stochastic) SignSGD, the latter serving as a proxy for Adam. Our analysis shows that for large batch size, SignSVD performs a square-root preconditioning with respect to the data covariance spectrum, while for small batch size smaller eigenmodes behave like SGD, slowing down convergence. We contrast with SignSGD which for generic covariance performs no preconditioning and has no transition, leading to different optimal learning rates and convergence characteristics. The two methods match up to a constant factor with isotropic data, but behave differently with anisotropic data. An analysis of a power law covariance model with data exponent $α$ and target exponent $β$ shows there are three phases in the $(α,β)$ plane: one where SignSGD is uniformly favored, one where SignSVD is uniformly favored, and a third where the two methods exhibit a trade-off in performance.
Exact Risk Curves of signSGD in High-Dimensions: Quantifying Preconditioning and Noise-Compression Effects
Nov 19, 2024



In recent years, signSGD has garnered interest as both a practical optimizer as well as a simple model to understand adaptive optimizers like Adam. Though there is a general consensus that signSGD acts to precondition optimization and reshapes noise, quantitatively understanding these effects in theoretically solvable settings remains difficult. We present an analysis of signSGD in a high dimensional limit, and derive a limiting SDE and ODE to describe the risk. Using this framework we quantify four effects of signSGD: effective learning rate, noise compression, diagonal preconditioning, and gradient noise reshaping. Our analysis is consistent with experimental observations but moves beyond that by quantifying the dependence of these effects on the data and noise distributions. We conclude with a conjecture on how these results might be extended to Adam.
A Clipped Trip: the Dynamics of SGD with Gradient Clipping in High-Dimensions
Jun 17, 2024The success of modern machine learning is due in part to the adaptive optimization methods that have been developed to deal with the difficulties of training large models over complex datasets. One such method is gradient clipping: a practical procedure with limited theoretical underpinnings. In this work, we study clipping in a least squares problem under streaming SGD. We develop a theoretical analysis of the learning dynamics in the limit of large intrinsic dimension-a model and dataset dependent notion of dimensionality. In this limit we find a deterministic equation that describes the evolution of the loss. We show that with Gaussian noise clipping cannot improve SGD performance. Yet, in other noisy settings, clipping can provide benefits with tuning of the clipping threshold. In these cases, clipping biases updates in a way beneficial to training which cannot be recovered by SGD under any schedule. We conclude with a discussion about the links between high-dimensional clipping and neural network training.
Bias Mitigation of Face Recognition Models Through Calibration
Jun 07, 2021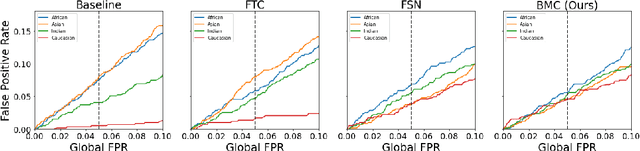

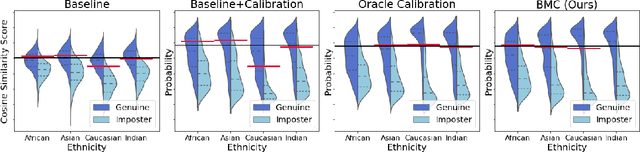
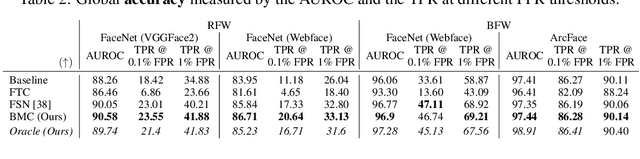
Face recognition models suffer from bias: for example, the probability of a false positive (incorrect face match) strongly depends on sensitive attributes like ethnicity. As a result, these models may disproportionately and negatively impact minority groups when used in law enforcement. In this work, we introduce the Bias Mitigation Calibration (BMC) method, which (i) increases model accuracy (improving the state-of-the-art), (ii) produces fairly-calibrated probabilities, (iii) significantly reduces the gap in the false positive rates, and (iv) does not require knowledge of the sensitive attribute.