 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalTweets: Investigating Social Media Offensive Language Among Nigerian Musicians
Nov 10, 2024Musicians frequently use social media to express their opinions, but they often convey different messages in their music compared to their posts online. Some utilize these platforms to abuse their colleagues, while others use it to show support for political candidates or engage in activism, as seen during the #EndSars protest. There are extensive research done on offensive language detection on social media, the usage of offensive language by musicians has received limited attention. In this study, we introduce VocalTweets, a code-switched and multilingual dataset comprising tweets from 12 prominent Nigerian musicians, labeled with a binary classification method as Normal or Offensive. We trained a model using HuggingFace's base-Twitter-RoBERTa, achieving an F1 score of 74.5. Additionally, we conducted cross-corpus experiments with the OLID dataset to evaluate the generalizability of our dataset.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022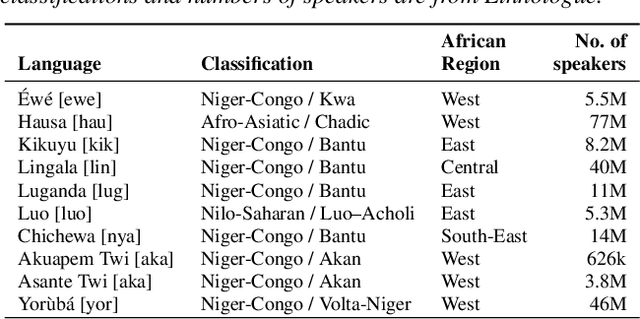
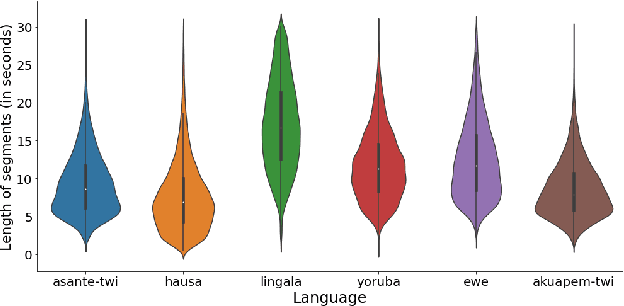
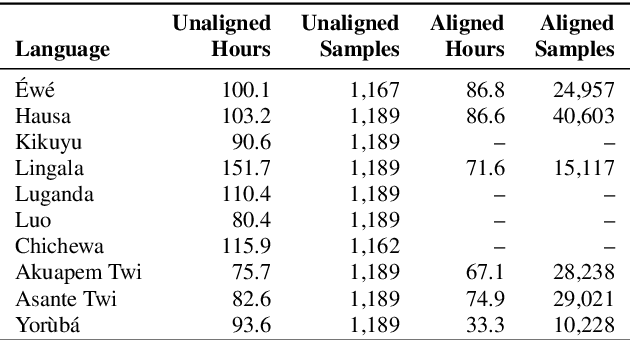
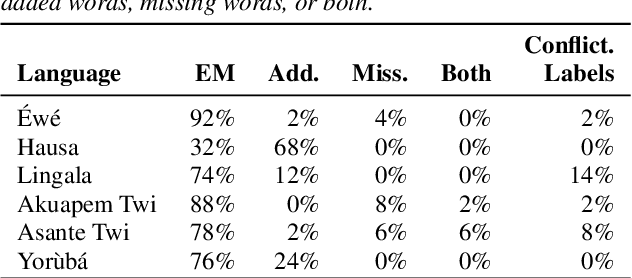
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021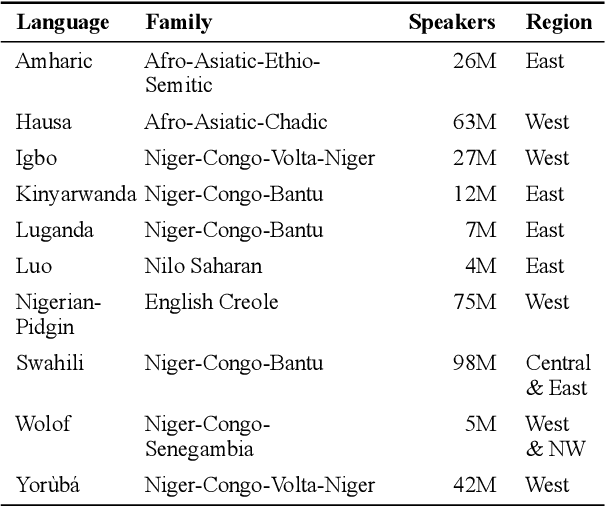

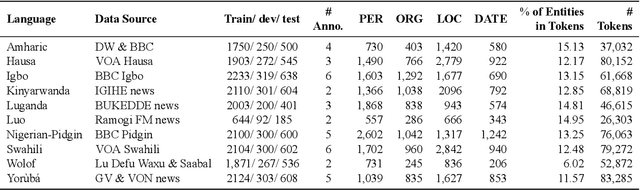
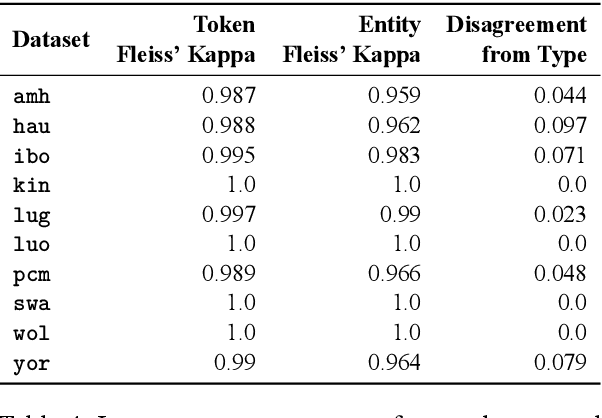
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.