 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Skill-augmented Agentic Framework and Benchmark for Multi-Video Understanding
Mar 16, 2026Multimodal Large Language Models have achieved strong performance in single-video understanding, yet their ability to reason across multiple videos remains limited. Existing approaches typically concatenate multiple videos into a single input and perform direct inference, which introduces training-inference mismatch, information loss from frame compression, and a lack of explicit cross-video coordination. Meanwhile, current multi-video benchmarks primarily emphasize event-level comparison, leaving identity-level matching, fine-grained discrimination, and structured multi-step reasoning underexplored. To address these gaps, we introduce MVX-Bench, a Multi-Video Cross-Dimension Benchmark that reformulates 11 classical computer vision tasks into a unified multi-video question-answering framework, comprising 1,442 questions over 4,255 videos from diverse real-world datasets. We further propose SAMA, a Skill-Augmented Agentic Framework for Multi-Video Understanding, which integrates visual tools, task-specific skills, and a conflict-aware verification mechanism to enable iterative and structured reasoning. Experimental results show that SAMA outperforms strong open-source baselines and GPT on MVX-Bench, and ablations validate the effectiveness of skill design and conflict resolution.
Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos
Mar 13, 2026Spatio-temporal scene graphs provide a principled representation for modeling evolving object interactions, yet existing methods remain fundamentally frame-centric: they reason only about currently visible objects, discard entities upon occlusion, and operate in 2D. To address this, we first introduce ActionGenome4D, a dataset that upgrades Action Genome videos into 4D scenes via feed-forward 3D reconstruction, world-frame oriented bounding boxes for every object involved in actions, and dense relationship annotations including for objects that are temporarily unobserved due to occlusion or camera motion. Building on this data, we formalize World Scene Graph Generation (WSGG), the task of constructing a world scene graph at each timestamp that encompasses all interacting objects in the scene, both observed and unobserved. We then propose three complementary methods, each exploring a different inductive bias for reasoning about unobserved objects: PWG (Persistent World Graph), which implements object permanence via a zero-order feature buffer; MWAE (Masked World Auto-Encoder), which reframes unobserved-object reasoning as masked completion with cross-view associative retrieval; and 4DST (4D Scene Transformer), which replaces the static buffer with differentiable per-object temporal attention enriched by 3D motion and camera-pose features. We further design and evaluate the performance of strong open-source Vision-Language Models on the WSGG task via a suite of Graph RAG-based approaches, establishing baselines for unlocalized relationship prediction. WSGG thus advances video scene understanding toward world-centric, temporally persistent, and interpretable scene reasoning.
Defeasible Visual Entailment: Benchmark, Evaluator, and Reward-Driven Optimization
Dec 19, 2024We introduce a new task called Defeasible Visual Entailment (DVE), where the goal is to allow the modification of the entailment relationship between an image premise and a text hypothesis based on an additional update. While this concept is well-established in Natural Language Inference, it remains unexplored in visual entailment. At a high level, DVE enables models to refine their initial interpretations, leading to improved accuracy and reliability in various applications such as detecting misleading information in images, enhancing visual question answering, and refining decision-making processes in autonomous systems. Existing metrics do not adequately capture the change in the entailment relationship brought by updates. To address this, we propose a novel inference-aware evaluator designed to capture changes in entailment strength induced by updates, using pairwise contrastive learning and categorical information learning. Additionally, we introduce a reward-driven update optimization method to further enhance the quality of updates generated by multimodal models. Experimental results demonstrate the effectiveness of our proposed evaluator and optimization method.
Towards Unbiased and Robust Spatio-Temporal Scene Graph Generation and Anticipation
Nov 20, 2024



Spatio-Temporal Scene Graphs (STSGs) provide a concise and expressive representation of dynamic scenes by modelling objects and their evolving relationships over time. However, real-world visual relationships often exhibit a long-tailed distribution, causing existing methods for tasks like Video Scene Graph Generation (VidSGG) and Scene Graph Anticipation (SGA) to produce biased scene graphs. To this end, we propose ImparTail, a novel training framework that leverages curriculum learning and loss masking to mitigate bias in the generation and anticipation of spatio-temporal scene graphs. Our approach gradually decreases the dominance of the head relationship classes during training and focuses more on tail classes, leading to more balanced training. Furthermore, we introduce two new tasks, Robust Spatio-Temporal Scene Graph Generation and Robust Scene Graph Anticipation, designed to evaluate the robustness of STSG models against distribution shifts. Extensive experiments on the Action Genome dataset demonstrate that our framework significantly enhances the unbiased performance and robustness of STSG models compared to existing methods.
Learning to Solve the Constrained Most Probable Explanation Task in Probabilistic Graphical Models
Apr 17, 2024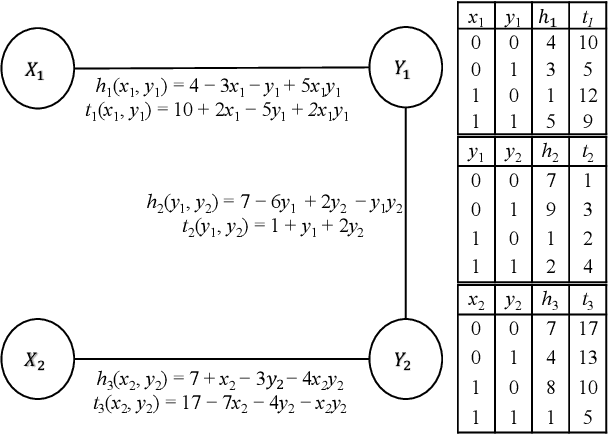
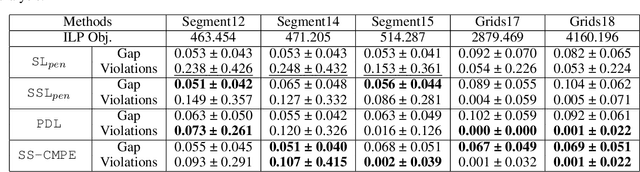
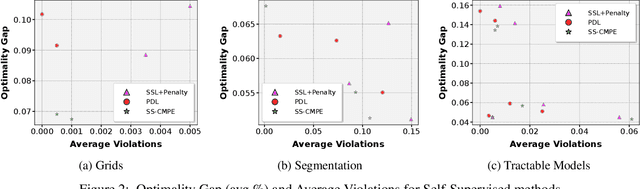
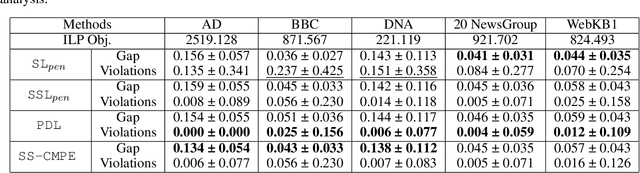
We propose a self-supervised learning approach for solving the following constrained optimization task in log-linear models or Markov networks. Let $f$ and $g$ be two log-linear models defined over the sets $\mathbf{X}$ and $\mathbf{Y}$ of random variables respectively. Given an assignment $\mathbf{x}$ to all variables in $\mathbf{X}$ (evidence) and a real number $q$, the constrained most-probable explanation (CMPE) task seeks to find an assignment $\mathbf{y}$ to all variables in $\mathbf{Y}$ such that $f(\mathbf{x}, \mathbf{y})$ is maximized and $g(\mathbf{x}, \mathbf{y})\leq q$. In our proposed self-supervised approach, given assignments $\mathbf{x}$ to $\mathbf{X}$ (data), we train a deep neural network that learns to output near-optimal solutions to the CMPE problem without requiring access to any pre-computed solutions. The key idea in our approach is to use first principles and approximate inference methods for CMPE to derive novel loss functions that seek to push infeasible solutions towards feasible ones and feasible solutions towards optimal ones. We analyze the properties of our proposed method and experimentally demonstrate its efficacy on several benchmark problems.
Deep Dependency Networks and Advanced Inference Schemes for Multi-Label Classification
Apr 17, 2024



We present a unified framework called deep dependency networks (DDNs) that combines dependency networks and deep learning architectures for multi-label classification, with a particular emphasis on image and video data. The primary advantage of dependency networks is their ease of training, in contrast to other probabilistic graphical models like Markov networks. In particular, when combined with deep learning architectures, they provide an intuitive, easy-to-use loss function for multi-label classification. A drawback of DDNs compared to Markov networks is their lack of advanced inference schemes, necessitating the use of Gibbs sampling. To address this challenge, we propose novel inference schemes based on local search and integer linear programming for computing the most likely assignment to the labels given observations. We evaluate our novel methods on three video datasets (Charades, TACoS, Wetlab) and three image datasets (MS-COCO, PASCAL VOC, NUS-WIDE), comparing their performance with (a) basic neural architectures and (b) neural architectures combined with Markov networks equipped with advanced inference and learning techniques. Our results demonstrate the superiority of our new DDN methods over the two competing approaches.
Grasping Trajectory Optimization with Point Clouds
Mar 08, 2024



We introduce a new trajectory optimization method for robotic grasping based on a point-cloud representation of robots and task spaces. In our method, robots are represented by 3D points on their link surfaces. The task space of a robot is represented by a point cloud that can be obtained from depth sensors. Using the point-cloud representation, goal reaching in grasping can be formulated as point matching, while collision avoidance can be efficiently achieved by querying the signed distance values of the robot points in the signed distance field of the scene points. Consequently, a constrained non-linear optimization problem is formulated to solve the joint motion and grasp planning problem. The advantage of our method is that the point-cloud representation is general to be used with any robot in any environment. We demonstrate the effectiveness of our method by conducting experiments on a tabletop scene and a shelf scene for grasping with a Fetch mobile manipulator and a Franka Panda arm.
Towards Scene Graph Anticipation
Mar 07, 2024



Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
Neural Network Approximators for Marginal MAP in Probabilistic Circuits
Feb 06, 2024



Probabilistic circuits (PCs) such as sum-product networks efficiently represent large multi-variate probability distributions. They are preferred in practice over other probabilistic representations such as Bayesian and Markov networks because PCs can solve marginal inference (MAR) tasks in time that scales linearly in the size of the network. Unfortunately, the maximum-a-posteriori (MAP) and marginal MAP (MMAP) tasks remain NP-hard in these models. Inspired by the recent work on using neural networks for generating near-optimal solutions to optimization problems such as integer linear programming, we propose an approach that uses neural networks to approximate (M)MAP inference in PCs. The key idea in our approach is to approximate the cost of an assignment to the query variables using a continuous multilinear function, and then use the latter as a loss function. The two main benefits of our new method are that it is self-supervised and after the neural network is learned, it requires only linear time to output a solution. We evaluate our new approach on several benchmark datasets and show that it outperforms three competing linear time approximations, max-product inference, max-marginal inference and sequential estimation, which are used in practice to solve MMAP tasks in PCs.
CaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023



Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning