 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve the Constrained Most Probable Explanation Task in Probabilistic Graphical Models
Paper and Code
Apr 17, 2024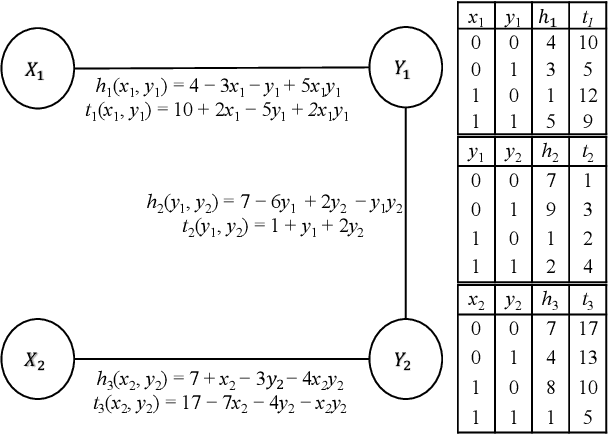
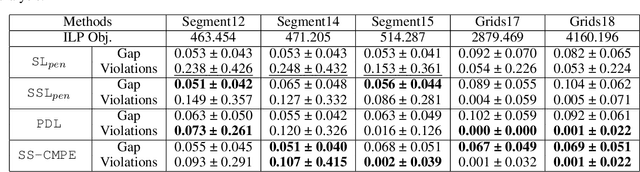
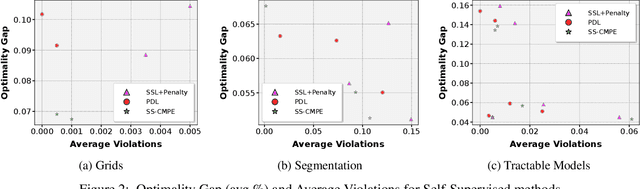
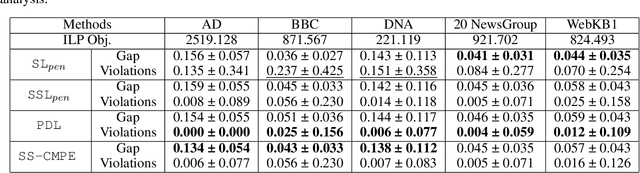
We propose a self-supervised learning approach for solving the following constrained optimization task in log-linear models or Markov networks. Let $f$ and $g$ be two log-linear models defined over the sets $\mathbf{X}$ and $\mathbf{Y}$ of random variables respectively. Given an assignment $\mathbf{x}$ to all variables in $\mathbf{X}$ (evidence) and a real number $q$, the constrained most-probable explanation (CMPE) task seeks to find an assignment $\mathbf{y}$ to all variables in $\mathbf{Y}$ such that $f(\mathbf{x}, \mathbf{y})$ is maximized and $g(\mathbf{x}, \mathbf{y})\leq q$. In our proposed self-supervised approach, given assignments $\mathbf{x}$ to $\mathbf{X}$ (data), we train a deep neural network that learns to output near-optimal solutions to the CMPE problem without requiring access to any pre-computed solutions. The key idea in our approach is to use first principles and approximate inference methods for CMPE to derive novel loss functions that seek to push infeasible solutions towards feasible ones and feasible solutions towards optimal ones. We analyze the properties of our proposed method and experimentally demonstrate its efficacy on several benchmark problems.