 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsotropic Gaussian Processes on Finite Spaces of Graphs
Nov 03, 2022



We propose a principled way to define Gaussian process priors on various sets of unweighted graphs: directed or undirected, with or without loops. We endow each of these sets with a geometric structure, inducing the notions of closeness and symmetries, by turning them into a vertex set of an appropriate metagraph. Building on this, we describe the class of priors that respect this structure and are analogous to the Euclidean isotropic processes, like squared exponential or Mat\'ern. We propose an efficient computational technique for the ostensibly intractable problem of evaluating these priors' kernels, making such Gaussian processes usable within the usual toolboxes and downstream applications. We go further to consider sets of equivalence classes of unweighted graphs and define the appropriate versions of priors thereon. We prove a hardness result, showing that in this case, exact kernel computation cannot be performed efficiently. However, we propose a simple Monte Carlo approximation for handling moderately sized cases. Inspired by applications in chemistry, we illustrate the proposed techniques on a real molecular property prediction task in the small data regime.
Bringing robotics taxonomies to continuous domains via GPLVM on hyperbolic manifolds
Oct 04, 2022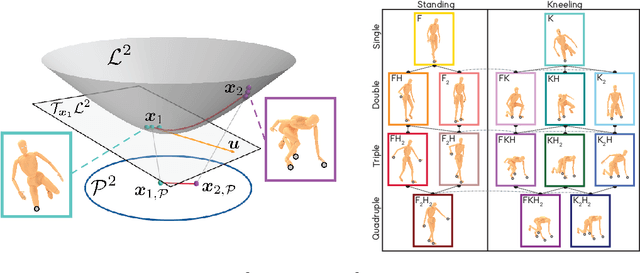
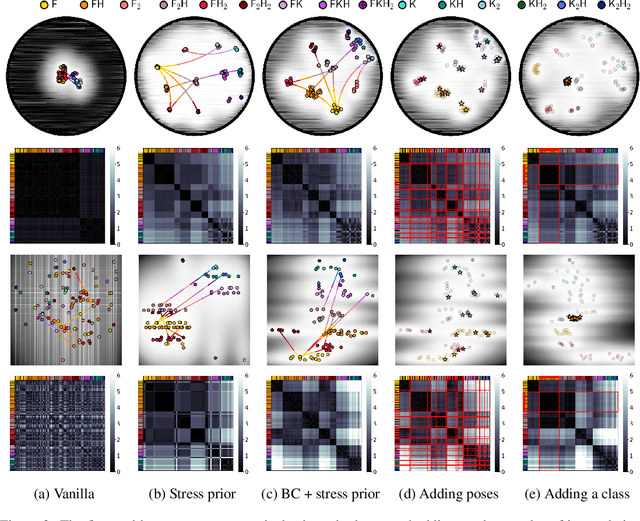

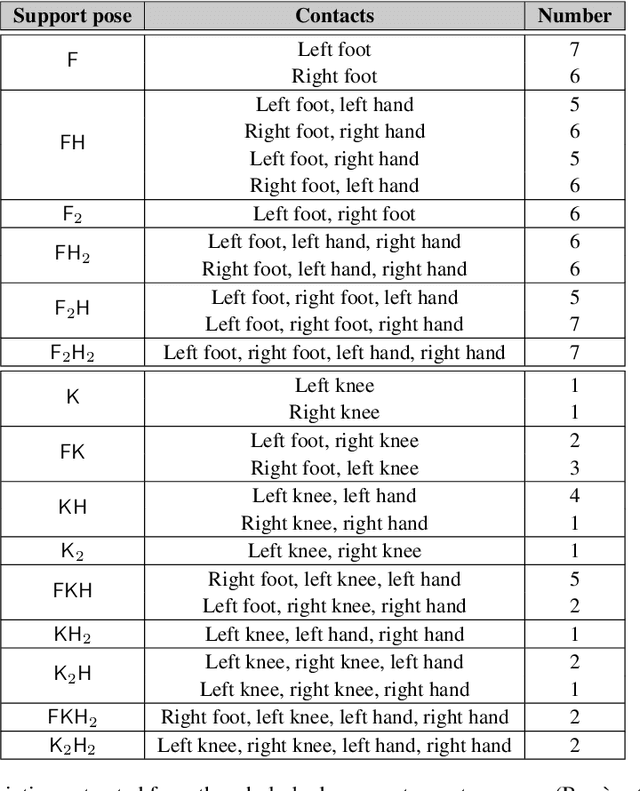
Robotic taxonomies have appeared as high-level hierarchical abstractions that classify how humans move and interact with their environment. They have proven useful to analyse grasps, manipulation skills, and whole-body support poses. Despite the efforts devoted to design their hierarchy and underlying categories, their use in application fields remains scarce. This may be attributed to the lack of computational models that fill the gap between the discrete hierarchical structure of the taxonomy and the high-dimensional heterogeneous data associated to its categories. To overcome this problem, we propose to model taxonomy data via hyperbolic embeddings that capture the associated hierarchical structure. To do so, we formulate a Gaussian process hyperbolic latent variable model and enforce the taxonomy structure through graph-based priors on the latent space and distance-preserving back constraints. We test our model on the whole-body support pose taxonomy to learn hyperbolic embeddings that comply with the original graph structure. We show that our model properly encodes unseen poses from existing or new taxonomy categories, it can be used to generate trajectories between the embeddings, and it outperforms its Euclidean counterparts.
Stationary Kernels and Gaussian Processes on Lie Groups and their Homogeneous Spaces I: the Compact Case
Aug 31, 2022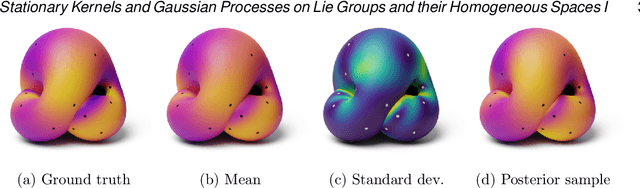
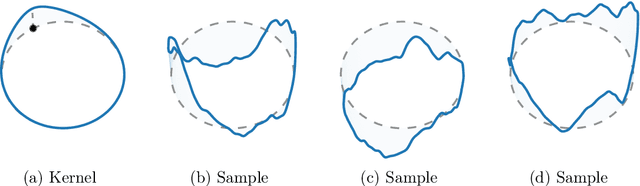
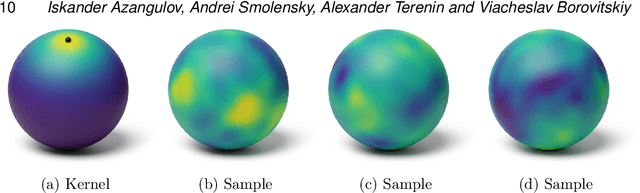
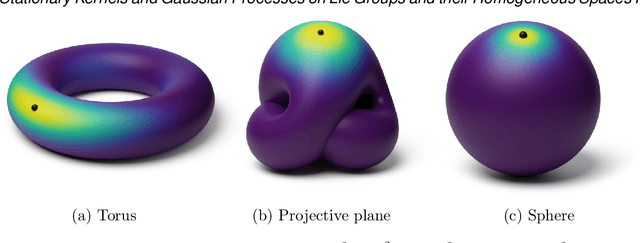
Gaussian processes are arguably the most important model class in spatial statistics. They encode prior information about the modeled function and can be used for exact or approximate Bayesian inference. In many applications, particularly in physical sciences and engineering, but also in areas such as geostatistics and neuroscience, invariance to symmetries is one of the most fundamental forms of prior information one can consider. The invariance of a Gaussian process' covariance to such symmetries gives rise to the most natural generalization of the concept of stationarity to such spaces. In this work, we develop constructive and practical techniques for building stationary Gaussian processes on a very large class of non-Euclidean spaces arising in the context of symmetries. Our techniques make it possible to (i) calculate covariance kernels and (ii) sample from prior and posterior Gaussian processes defined on such spaces, both in a practical manner. This work is split into two parts, each involving different technical considerations: part I studies compact spaces, while part II studies non-compact spaces possessing certain structure. Our contributions make the non-Euclidean Gaussian process models we study compatible with well-understood computational techniques available in standard Gaussian process software packages, thereby making them accessible to practitioners.
Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge Independent Projected Kernels
Nov 25, 2021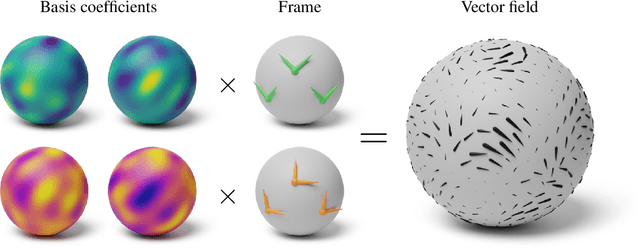


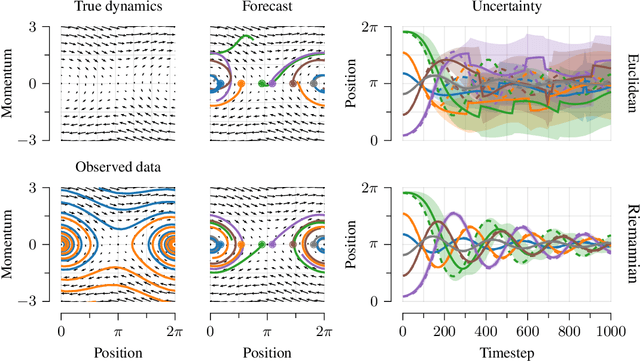
Gaussian processes are machine learning models capable of learning unknown functions in a way that represents uncertainty, thereby facilitating construction of optimal decision-making systems. Motivated by a desire to deploy Gaussian processes in novel areas of science, a rapidly-growing line of research has focused on constructively extending these models to handle non-Euclidean domains, including Riemannian manifolds, such as spheres and tori. We propose techniques that generalize this class to model vector fields on Riemannian manifolds, which are important in a number of application areas in the physical sciences. To do so, we present a general recipe for constructing gauge independent kernels, which induce Gaussian vector fields, i.e. vector-valued Gaussian processes coherent with geometry, from scalar-valued Riemannian kernels. We extend standard Gaussian process training methods, such as variational inference, to this setting. This enables vector-valued Gaussian processes on Riemannian manifolds to be trained using standard methods and makes them accessible to machine learning practitioners.
Geometry-aware Bayesian Optimization in Robotics using Riemannian Matérn Kernels
Nov 02, 2021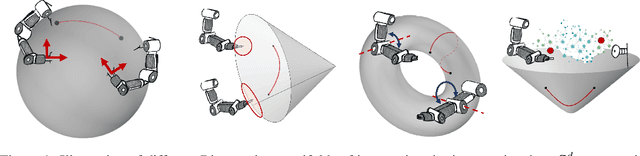
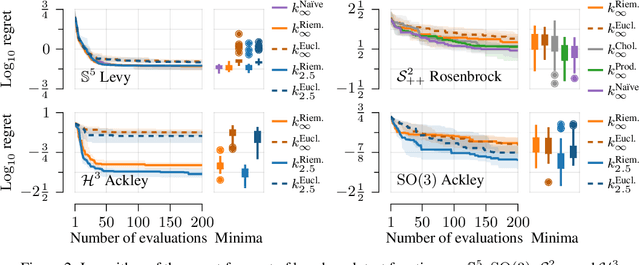
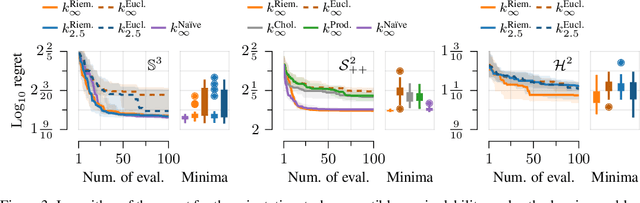
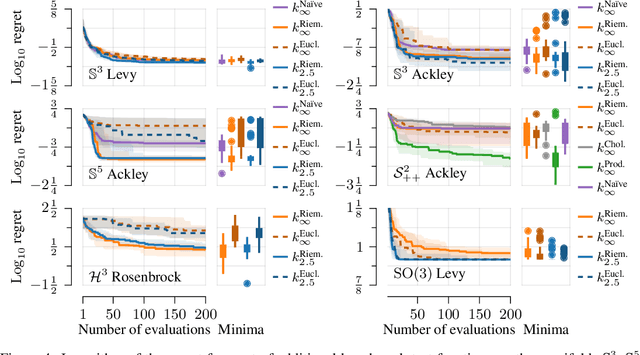
Bayesian optimization is a data-efficient technique which can be used for control parameter tuning, parametric policy adaptation, and structure design in robotics. Many of these problems require optimization of functions defined on non-Euclidean domains like spheres, rotation groups, or spaces of positive-definite matrices. To do so, one must place a Gaussian process prior, or equivalently define a kernel, on the space of interest. Effective kernels typically reflect the geometry of the spaces they are defined on, but designing them is generally non-trivial. Recent work on the Riemannian Mat\'ern kernels, based on stochastic partial differential equations and spectral theory of the Laplace-Beltrami operator, offers promising avenues towards constructing such geometry-aware kernels. In this paper, we study techniques for implementing these kernels on manifolds of interest in robotics, demonstrate their performance on a set of artificial benchmark functions, and illustrate geometry-aware Bayesian optimization for a variety of robotic applications, covering orientation control, manipulability optimization, and motion planning, while showing its improved performance.
Quadric hypersurface intersection for manifold learning in feature space
Feb 11, 2021
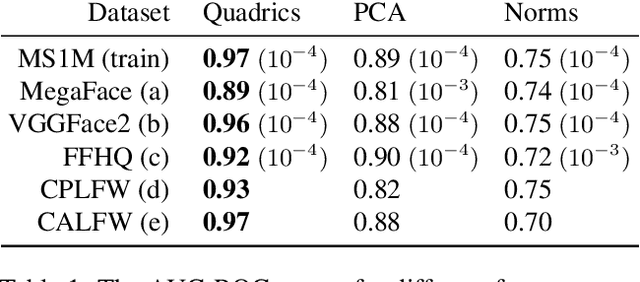
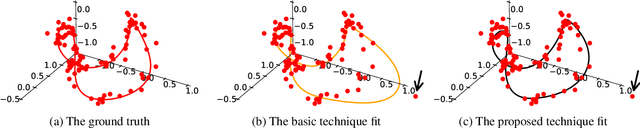
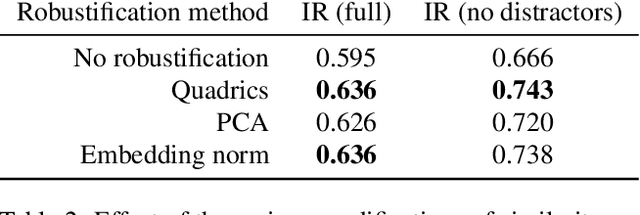
The knowledge that data lies close to a particular submanifold of the ambient Euclidean space may be useful in a number of ways. For instance, one may want to automatically mark any point far away from the submanifold as an outlier, or to use its geodesic distance to measure similarity between points. Classical problems for manifold learning are often posed in a very high dimension, e.g. for spaces of images or spaces of representations of words. Today, with deep representation learning on the rise in areas such as computer vision and natural language processing, many problems of this kind may be transformed into problems of moderately high dimension, typically of the order of hundreds. Motivated by this, we propose a manifold learning technique suitable for moderately high dimension and large datasets. The manifold is learned from the training data in the form of an intersection of quadric hypersurfaces -- simple but expressive objects. At test time, this manifold can be used to introduce an outlier score for arbitrary new points and to improve a given similarity metric by incorporating learned geometric structure into it.
Pathwise Conditioning of Gaussian Processes
Nov 08, 2020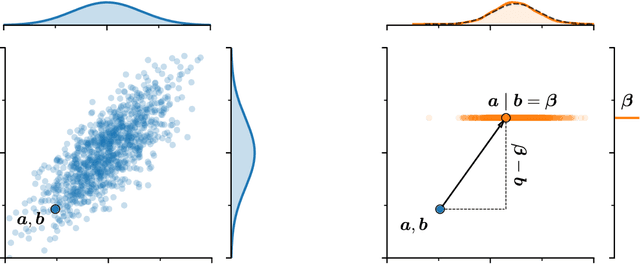
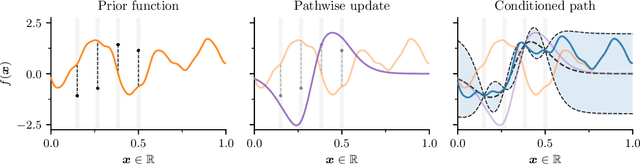
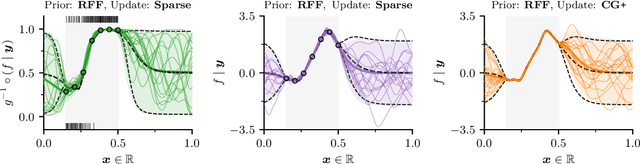
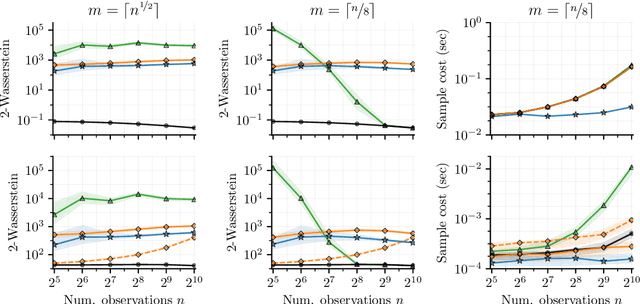
As Gaussian processes are integrated into increasingly complex problem settings, analytic solutions to quantities of interest become scarcer and scarcer. Monte Carlo methods act as a convenient bridge for connecting intractable mathematical expressions with actionable estimates via sampling. Conventional approaches for simulating Gaussian process posteriors view samples as vectors drawn from marginal distributions over process values at a finite number of input location. This distribution-based characterization leads to generative strategies that scale cubically in the size of the desired random vector. These methods are, therefore, prohibitively expensive in cases where high-dimensional vectors - let alone continuous functions - are required. In this work, we investigate a different line of reasoning. Rather than focusing on distributions, we articulate Gaussian conditionals at the level of random variables. We show how this pathwise interpretation of conditioning gives rise to a general family of approximations that lend themselves to fast sampling from Gaussian process posteriors. We analyze these methods, along with the approximation errors they introduce, from first principles. We then complement this theory, by exploring the practical ramifications of pathwise conditioning in a various applied settings.
Matern Gaussian Processes on Graphs
Oct 29, 2020
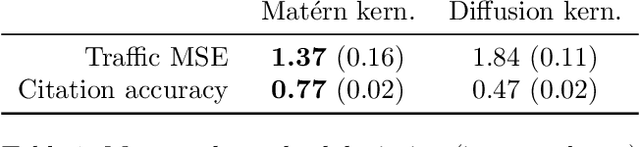
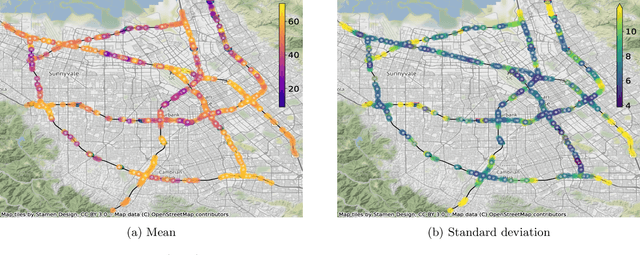
Gaussian processes are a versatile framework for learning unknown functions in a manner that permits one to utilize prior information about their properties. Although many different Gaussian process models are readily available when the input space is Euclidean, the choice is much more limited for Gaussian processes whose input space is an undirected graph. In this work, we leverage the stochastic partial differential equation characterization of Mat\'{e}rn Gaussian processes - a widely-used model class in the Euclidean setting - to study their analog for undirected graphs. We show that the resulting Gaussian processes inherit various attractive properties of their Euclidean and Riemannian analogs and provide techniques that allow them to be trained using standard methods, such as inducing points. This enables graph Mat\'{e}rn Gaussian processes to be employed in mini-batch and non-conjugate settings, thereby making them more accessible to practitioners and easier to deploy within larger learning frameworks.
Matern Gaussian processes on Riemannian manifolds
Jun 17, 2020
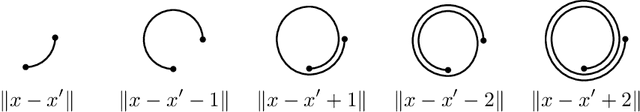

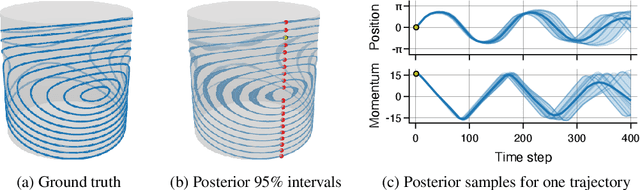
Gaussian processes are an effective model class for learning unknown functions, particularly in settings where accurately representing predictive uncertainty is of key importance. Motivated by applications in the physical sciences, the widely-used Mat\'{e}rn class of Gaussian processes has recently been generalized to model functions whose domains are Riemannian manifolds, by re-expressing said processes as solutions of stochastic partial differential equations. In this work, we propose techniques for computing the kernels of these processes via spectral theory of the Laplace--Beltrami operator in a fully constructive manner, thereby allowing them to be trained via standard scalable techniques such as inducing point methods. We also extend the generalization from the Mat\'{e}rn to the widely-used squared exponential Gaussian process. By allowing Riemannian Mat\'{e}rn Gaussian processes to be trained using well-understood techniques, our work enables their use in mini-batch, online, and non-conjugate settings, and makes them more accessible to machine learning practitioners.
Efficiently sampling functions from Gaussian process posteriors
Feb 21, 2020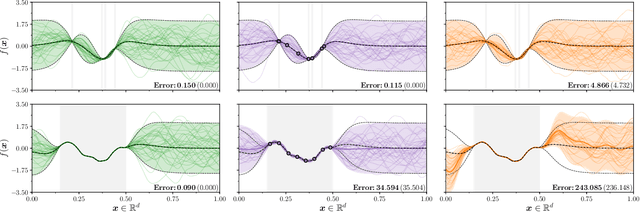
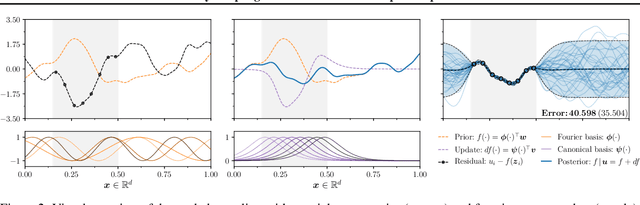
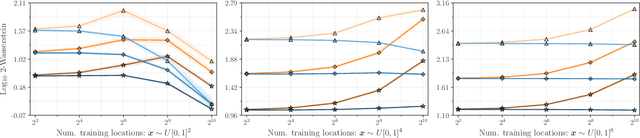
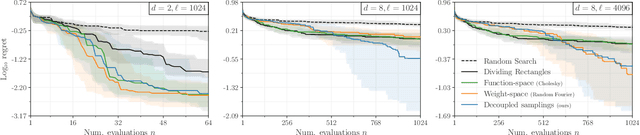
Gaussian processes are the gold standard for many real-world modeling problems, especially in cases where a model's success hinges upon its ability to faithfully represent predictive uncertainty. These problems typically exist as parts of larger frameworks, where quantities of interest are ultimately defined by integrating over posterior distributions. However, these algorithms' inner workings rarely allow for closed-form integration, giving rise to a need for Monte Carlo methods. Despite substantial progress in scaling up Gaussian processes to large training sets, methods for accurately generating draws from their posterior distributions still scale cubically in the number of test locations. We identify a decomposition of Gaussian processes that naturally lends itself to scalable sampling by enabling us to efficiently generate functions that accurately represent their posteriors. Building off of this factorization, we propose decoupled sampling, an easy-to-use and general-purpose approach for fast posterior sampling. Decoupled sampling works as a drop-in strategy that seamlessly pairs with sparse approximations to Gaussian processes to afford scalability both during training and at test time. In a series of experiments designed to test competing sampling schemes' statistical behaviors and practical ramifications, we empirically show that functions drawn using decoupled sampling faithfully represent Gaussian process posteriors at a fraction of the usual cost.