 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Evaluation of Generative Models with Instruction Tuning
Oct 30, 2023



Automatic evaluation of natural language generation has long been an elusive goal in NLP.A recent paradigm fine-tunes pre-trained language models to emulate human judgements for a particular task and evaluation criterion. Inspired by the generalization ability of instruction-tuned models, we propose a learned metric based on instruction tuning. To test our approach, we collected HEAP, a dataset of human judgements across various NLG tasks and evaluation criteria. Our findings demonstrate that instruction tuning language models on HEAP yields good performance on many evaluation tasks, though some criteria are less trivial to learn than others. Further, jointly training on multiple tasks can yield additional performance improvements, which can be beneficial for future tasks with little to no human annotated data.
GD-COMET: A Geo-Diverse Commonsense Inference Model
Oct 23, 2023



With the increasing integration of AI into everyday life, it's becoming crucial to design AI systems that serve users from diverse backgrounds by making them culturally aware. In this paper, we present GD-COMET, a geo-diverse version of the COMET commonsense inference model. GD-COMET goes beyond Western commonsense knowledge and is capable of generating inferences pertaining to a broad range of cultures. We demonstrate the effectiveness of GD-COMET through a comprehensive human evaluation across 5 diverse cultures, as well as extrinsic evaluation on a geo-diverse task. The evaluation shows that GD-COMET captures and generates culturally nuanced commonsense knowledge, demonstrating its potential to benefit NLP applications across the board and contribute to making NLP more inclusive.
From chocolate bunny to chocolate crocodile: Do Language Models Understand Noun Compounds?
May 24, 2023Noun compound interpretation is the task of expressing a noun compound (e.g. chocolate bunny) in a free-text paraphrase that makes the relationship between the constituent nouns explicit (e.g. bunny-shaped chocolate). We propose modifications to the data and evaluation setup of the standard task (Hendrickx et al., 2013), and show that GPT-3 solves it almost perfectly. We then investigate the task of noun compound conceptualization, i.e. paraphrasing a novel or rare noun compound. E.g., chocolate crocodile is a crocodile-shaped chocolate. This task requires creativity, commonsense, and the ability to generalize knowledge about similar concepts. While GPT-3's performance is not perfect, it is better than that of humans -- likely thanks to its access to vast amounts of knowledge, and because conceptual processing is effortful for people (Connell and Lynott, 2012). Finally, we estimate the extent to which GPT-3 is reasoning about the world vs. parroting its training data. We find that the outputs from GPT-3 often have significant overlap with a large web corpus, but that the parroting strategy is less beneficial for novel noun compounds.
COMET-M: Reasoning about Multiple Events in Complex Sentences
May 24, 2023Understanding the speaker's intended meaning often involves drawing commonsense inferences to reason about what is not stated explicitly. In multi-event sentences, it requires understanding the relationships between events based on contextual knowledge. We propose COMET-M (Multi-Event), an event-centric commonsense model capable of generating commonsense inferences for a target event within a complex sentence. COMET-M builds upon COMET (Bosselut et al., 2019), which excels at generating event-centric inferences for simple sentences, but struggles with the complexity of multi-event sentences prevalent in natural text. To overcome this limitation, we curate a multi-event inference dataset of 35K human-written inferences. We trained COMET-M on the human-written inferences and also created baselines using automatically labeled examples. Experimental results demonstrate the significant performance improvement of COMET-M over COMET in generating multi-event inferences. Moreover, COMET-M successfully produces distinct inferences for each target event, taking the complete context into consideration. COMET-M holds promise for downstream tasks involving natural text such as coreference resolution, dialogue, and story understanding.
Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models
May 24, 2023The escalating debate on AI's capabilities warrants developing reliable metrics to assess machine "intelligence". Recently, many anecdotal examples were used to suggest that newer large language models (LLMs) like ChatGPT and GPT-4 exhibit Neural Theory-of-Mind (N-ToM); however, prior work reached conflicting conclusions regarding those abilities. We investigate the extent of LLMs' N-ToM through an extensive evaluation on 6 tasks and find that while LLMs exhibit certain N-ToM abilities, this behavior is far from being robust. We further examine the factors impacting performance on N-ToM tasks and discover that LLMs struggle with adversarial examples, indicating reliance on shallow heuristics rather than robust ToM abilities. We caution against drawing conclusions from anecdotal examples, limited benchmark testing, and using human-designed psychological tests to evaluate models.
MemeCap: A Dataset for Captioning and Interpreting Memes
May 23, 2023Memes are a widely popular tool for web users to express their thoughts using visual metaphors. Understanding memes requires recognizing and interpreting visual metaphors with respect to the text inside or around the meme, often while employing background knowledge and reasoning abilities. We present the task of meme captioning and release a new dataset, MemeCap. Our dataset contains 6.3K memes along with the title of the post containing the meme, the meme captions, the literal image caption, and the visual metaphors. Despite the recent success of vision and language (VL) models on tasks such as image captioning and visual question answering, our extensive experiments using state-of-the-art VL models show that they still struggle with visual metaphors, and perform substantially worse than humans.
What happens before and after: Multi-Event Commonsense in Event Coreference Resolution
Feb 21, 2023Event coreference models cluster event mentions pertaining to the same real-world event. Recent models rely on contextualized representations to recognize coreference among lexically or contextually similar mentions. However, models typically fail to leverage commonsense inferences, which is particularly limiting for resolving lexically-divergent mentions. We propose a model that extends event mentions with temporal commonsense inferences. Given a complex sentence with multiple events, e.g., "The man killed his wife and got arrested", with the target event "arrested", our model generates plausible events that happen before the target event - such as "the police arrived", and after it, such as "he was sentenced". We show that incorporating such inferences into an existing event coreference model improves its performance, and we analyze the coreferences in which such temporal knowledge is required.
VLC-BERT: Visual Question Answering with Contextualized Commonsense Knowledge
Oct 24, 2022There has been a growing interest in solving Visual Question Answering (VQA) tasks that require the model to reason beyond the content present in the image. In this work, we focus on questions that require commonsense reasoning. In contrast to previous methods which inject knowledge from static knowledge bases, we investigate the incorporation of contextualized knowledge using Commonsense Transformer (COMET), an existing knowledge model trained on human-curated knowledge bases. We propose a method to generate, select, and encode external commonsense knowledge alongside visual and textual cues in a new pre-trained Vision-Language-Commonsense transformer model, VLC-BERT. Through our evaluation on the knowledge-intensive OK-VQA and A-OKVQA datasets, we show that VLC-BERT is capable of outperforming existing models that utilize static knowledge bases. Furthermore, through a detailed analysis, we explain which questions benefit, and which don't, from contextualized commonsense knowledge from COMET.
Uncovering Implicit Gender Bias in Narratives through Commonsense Inference
Sep 14, 2021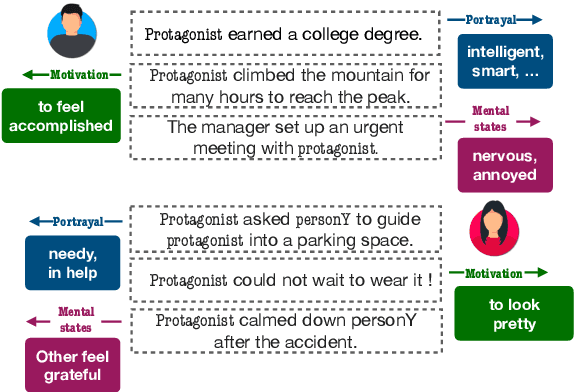
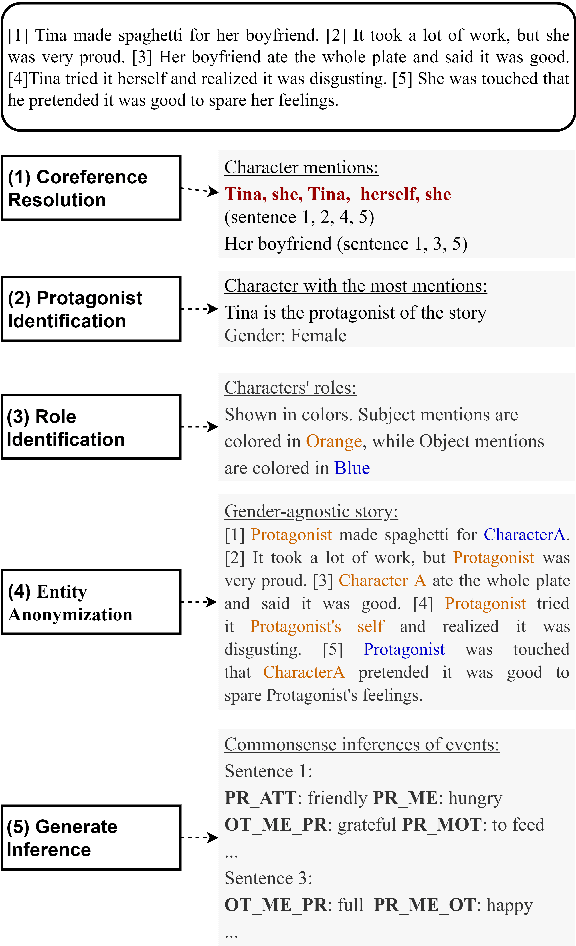
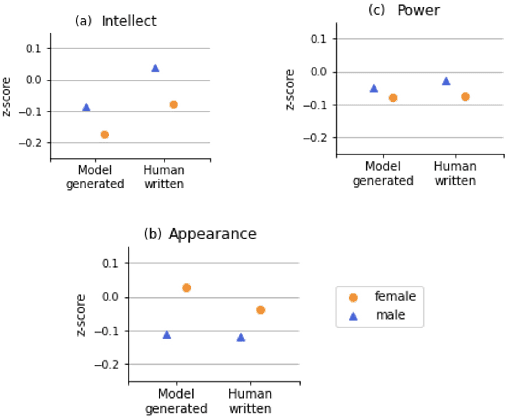
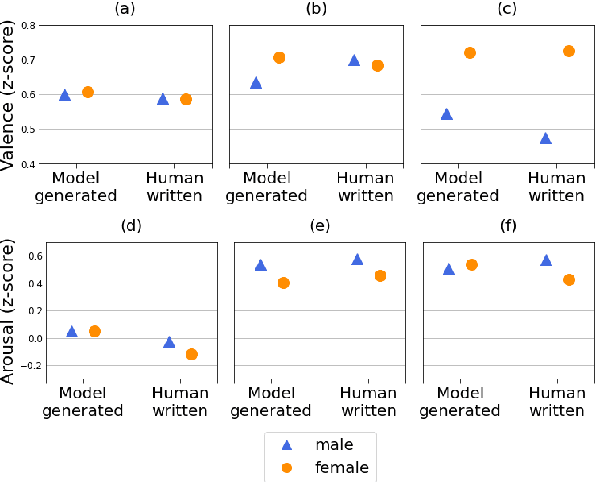
Pre-trained language models learn socially harmful biases from their training corpora, and may repeat these biases when used for generation. We study gender biases associated with the protagonist in model-generated stories. Such biases may be expressed either explicitly ("women can't park") or implicitly (e.g. an unsolicited male character guides her into a parking space). We focus on implicit biases, and use a commonsense reasoning engine to uncover them. Specifically, we infer and analyze the protagonist's motivations, attributes, mental states, and implications on others. Our findings regarding implicit biases are in line with prior work that studied explicit biases, for example showing that female characters' portrayal is centered around appearance, while male figures' focus on intellect.
It's not Rocket Science : Interpreting Figurative Language in Narratives
Aug 31, 2021
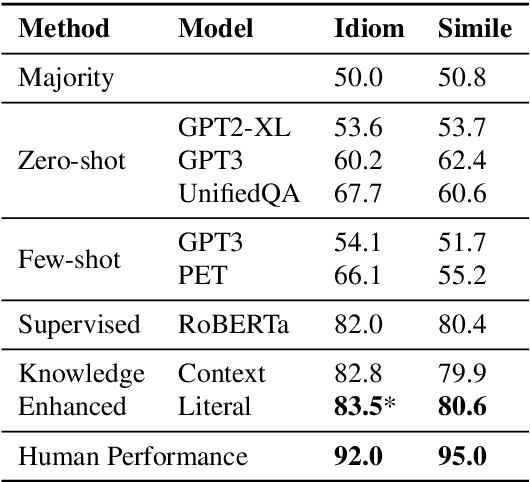

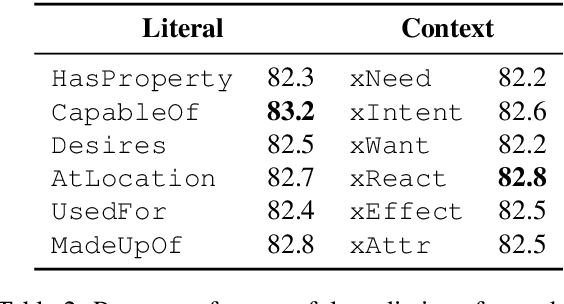
Figurative language is ubiquitous in English. Yet, the vast majority of NLP research focuses on literal language. Existing text representations by design rely on compositionality, while figurative language is often non-compositional. In this paper, we study the interpretation of two non-compositional figurative languages (idioms and similes). We collected datasets of fictional narratives containing a figurative expression along with crowd-sourced plausible and implausible continuations relying on the correct interpretation of the expression. We then trained models to choose or generate the plausible continuation. Our experiments show that models based solely on pre-trained language models perform substantially worse than humans on these tasks. We additionally propose knowledge-enhanced models, adopting human strategies for interpreting figurative language: inferring meaning from the context and relying on the constituent word's literal meanings. The knowledge-enhanced models improve the performance on both the discriminative and generative tasks, further bridging the gap from human performance.