 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Modality Invariance in a Multilingual Speech-Text Model via Neuron-Level Analysis
Jan 24, 2026Multilingual speech-text foundation models aim to process language uniformly across both modality and language, yet it remains unclear whether they internally represent the same language consistently when it is spoken versus written. We investigate this question in SeamlessM4T v2 through three complementary analyses that probe where language and modality information is encoded, how selective neurons causally influence decoding, and how concentrated this influence is across the network. We identify language- and modality-selective neurons using average-precision ranking, investigate their functional role via median-replacement interventions at inference time, and analyze activation-magnitude inequality across languages and modalities. Across experiments, we find evidence of incomplete modality invariance. Although encoder representations become increasingly language-agnostic, this compression makes it more difficult for the shared decoder to recover the language of origin when constructing modality-agnostic representations, particularly when adapting from speech to text. We further observe sharply localized modality-selective structure in cross-attention key and value projections. Finally, speech-conditioned decoding and non-dominant scripts exhibit higher activation concentration, indicating heavier reliance on a small subset of neurons, which may underlie increased brittleness across modalities and languages.
System-Mediated Attention Imbalances Make Vision-Language Models Say Yes
Jan 18, 2026Vision-language model (VLM) hallucination is commonly linked to imbalanced allocation of attention across input modalities: system, image and text. However, existing mitigation strategies tend towards an image-centric interpretation of these imbalances, often prioritising increased image attention while giving less consideration to the roles of the other modalities. In this study, we evaluate a more holistic, system-mediated account, which attributes these imbalances to functionally redundant system weights that reduce attention to image and textual inputs. We show that this framework offers a useful empirical perspective on the yes-bias, a common form of hallucination in which VLMs indiscriminately respond 'yes'. Causally redistributing attention from the system modality to image and textual inputs substantially suppresses this bias, often outperforming existing approaches. We further present evidence suggesting that system-mediated attention imbalances contribute to the yes-bias by encouraging a default reliance on coarse input representations, which are effective for some tasks but ill-suited to others. Taken together, these findings firmly establish system attention as a key factor in VLM hallucination and highlight its potential as a lever for mitigation.
Bridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025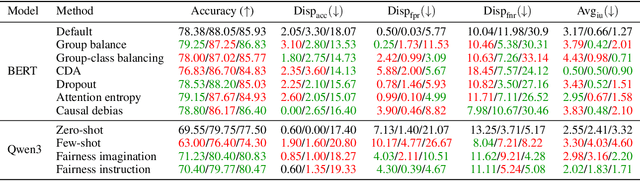
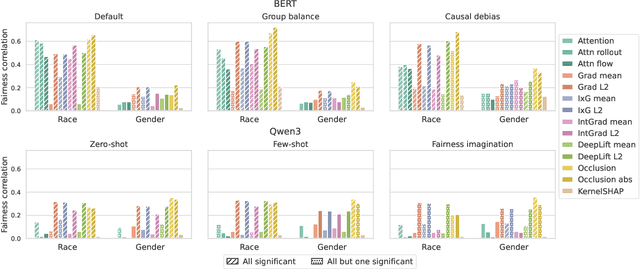
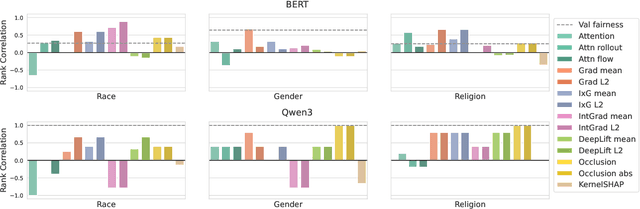

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
Born a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
Explanatory Summarization with Discourse-Driven Planning
Apr 27, 2025Lay summaries for scientific documents typically include explanations to help readers grasp sophisticated concepts or arguments. However, current automatic summarization methods do not explicitly model explanations, which makes it difficult to align the proportion of explanatory content with human-written summaries. In this paper, we present a plan-based approach that leverages discourse frameworks to organize summary generation and guide explanatory sentences by prompting responses to the plan. Specifically, we propose two discourse-driven planning strategies, where the plan is conditioned as part of the input or part of the output prefix, respectively. Empirical experiments on three lay summarization datasets show that our approach outperforms existing state-of-the-art methods in terms of summary quality, and it enhances model robustness, controllability, and mitigates hallucination.
Synthetic Data Augmentation for Cross-domain Implicit Discourse Relation Recognition
Mar 26, 2025



Implicit discourse relation recognition (IDRR) -- the task of identifying the implicit coherence relation between two text spans -- requires deep semantic understanding. Recent studies have shown that zero- or few-shot approaches significantly lag behind supervised models, but LLMs may be useful for synthetic data augmentation, where LLMs generate a second argument following a specified coherence relation. We applied this approach in a cross-domain setting, generating discourse continuations using unlabelled target-domain data to adapt a base model which was trained on source-domain labelled data. Evaluations conducted on a large-scale test set revealed that different variations of the approach did not result in any significant improvements. We conclude that LLMs often fail to generate useful samples for IDRR, and emphasize the importance of considering both statistical significance and comparability when evaluating IDRR models.
LLMs syntactically adapt their language use to their conversational partner
Mar 10, 2025It has been frequently observed that human speakers align their language use with each other during conversations. In this paper, we study empirically whether large language models (LLMs) exhibit the same behavior of conversational adaptation. We construct a corpus of conversations between LLMs and find that two LLM agents end up making more similar syntactic choices as conversations go on, confirming that modern LLMs adapt their language use to their conversational partners in at least a rudimentary way.
Enhancing Spoken Discourse Modeling in Language Models Using Gestural Cues
Mar 05, 2025



Research in linguistics shows that non-verbal cues, such as gestures, play a crucial role in spoken discourse. For example, speakers perform hand gestures to indicate topic shifts, helping listeners identify transitions in discourse. In this work, we investigate whether the joint modeling of gestures using human motion sequences and language can improve spoken discourse modeling in language models. To integrate gestures into language models, we first encode 3D human motion sequences into discrete gesture tokens using a VQ-VAE. These gesture token embeddings are then aligned with text embeddings through feature alignment, mapping them into the text embedding space. To evaluate the gesture-aligned language model on spoken discourse, we construct text infilling tasks targeting three key discourse cues grounded in linguistic research: discourse connectives, stance markers, and quantifiers. Results show that incorporating gestures enhances marker prediction accuracy across the three tasks, highlighting the complementary information that gestures can offer in modeling spoken discourse. We view this work as an initial step toward leveraging non-verbal cues to advance spoken language modeling in language models.
Pragmatic Reasoning improves LLM Code Generation
Feb 28, 2025Large Language Models (LLMs) have demonstrated impressive potential in translating natural language (NL) instructions into program code. However, user instructions often contain inherent ambiguities, making it challenging for LLMs to generate code that accurately reflects the user's true intent. To address this challenge, researchers have proposed to produce multiple candidates of the program code and then rerank them to identify the best solution. In this paper, we propose CodeRSA, a novel code candidate reranking mechanism built upon the Rational Speech Act (RSA) framework, designed to guide LLMs toward more comprehensive pragmatic reasoning about user intent. We evaluate CodeRSA using one of the latest LLMs on a popular code generation dataset. Our experiment results show that CodeRSA consistently outperforms common baselines, surpasses the state-of-the-art approach in most cases, and demonstrates robust overall performance. These findings underscore the effectiveness of integrating pragmatic reasoning into code candidate reranking, offering a promising direction for enhancing code generation quality in LLMs.
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Feb 18, 2025Post-hoc explanation methods for black-box models often struggle with faithfulness and human interpretability due to the lack of explainability in current neural models. Meanwhile, B-cos networks have been introduced to improve model explainability through architectural and computational adaptations, but their application has so far been limited to computer vision models and their associated training pipelines. In this work, we introduce B-cos LMs, i.e., B-cos networks empowered for NLP tasks. Our approach directly transforms pre-trained language models into B-cos LMs by combining B-cos conversion and task fine-tuning, improving efficiency compared to previous B-cos methods. Our automatic and human evaluation results demonstrate that B-cos LMs produce more faithful and human interpretable explanations than post hoc methods, while maintaining task performance comparable to conventional fine-tuning. Our in-depth analysis explores how B-cos LMs differ from conventionally fine-tuned models in their learning processes and explanation patterns. Finally, we provide practical guidelines for effectively building B-cos LMs based on our findings. Our code is available at https://anonymous.4open.science/r/bcos_lm.