 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA retrieval conditioned rebinding circuit for dynamic entity tracking in large language models
Jun 07, 2026To interpret context correctly and retrieve relevant information, large language models must bind entities to their attributes and update these bindings as state changes. We analyze how LLMs implement this binding process in a dynamic state tracking. Using causal interventions, we identify a retrieval conditioned rebinding mechanism, a compact attention head circuit that encodes swap relevant binding information and reinstates it at readout. Across Gemma and Llama models, this circuit supports rebinding behavior, but the representational signature of the mechanism differs across model families. In Gemma models, the binding signature is clearly expressed in the query/key subspaces of the relevant attention heads, whereas in Llama models, the binding information is carried primarily in key vectors. Overall, our results reveal an interpretable mechanism for context dependent state tracking in LLMs.
Sparse Mixture-of-Experts Reward Models Learn Interpretable and Specialized Experts for Personalized Preference Modeling
Jun 02, 2026Preference modeling plays a central role in reinforcement learning from human feedback (RLHF), enabling large language models (LLMs) to align with human values. However, most existing approaches assume a universal reward function, neglecting the diversity and heterogeneity of human preferences. To address this limitation without additional annotation costs, recent work has proposed learning multiple preference components from binary data and combining them to model individual preferences. Nevertheless, these components often fail to capture coherent and disentangled patterns, limiting their interpretability and effectiveness for personalization. In this work, we propose a sparse Mixture-of-Experts (MoE) reward model that encourages sparse routing and expert diversity during training on binary preference data. Across controlled and real-world experiments, sparse MoE learns interpretable routing patterns and specialized experts. It also improves test-time personalization, and post-adaptation shifts in expert weights provide a qualitative lens for analyzing how the model adapts to personalized preferences.
Bridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025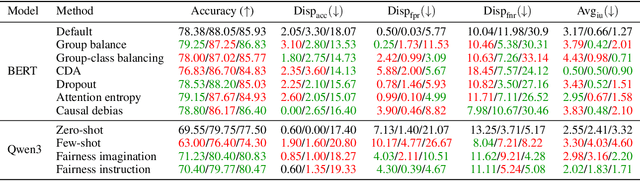
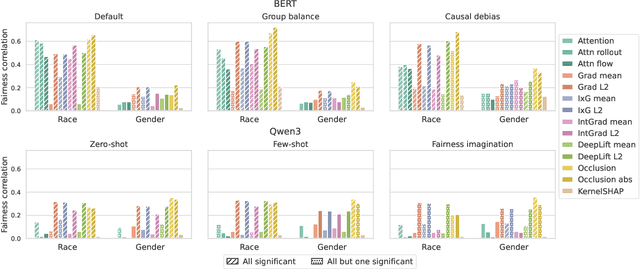
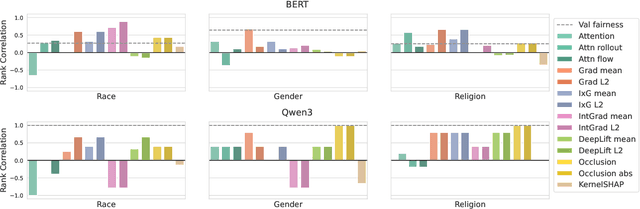

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
May 03, 2023



Sustaining coherent and engaging narratives requires dialogue or storytelling agents to understand how the personas of speakers or listeners ground the narrative. Specifically, these agents must infer personas of their listeners to produce statements that cater to their interests. They must also learn to maintain consistent speaker personas for themselves throughout the narrative, so that their counterparts feel involved in a realistic conversation or story. However, personas are diverse and complex: they entail large quantities of rich interconnected world knowledge that is challenging to robustly represent in general narrative systems (e.g., a singer is good at singing, and may have attended conservatoire). In this work, we construct a new large-scale persona commonsense knowledge graph, PeaCoK, containing ~100K human-validated persona facts. Our knowledge graph schematizes five dimensions of persona knowledge identified in previous studies of human interactive behaviours, and distils facts in this schema from both existing commonsense knowledge graphs and large-scale pretrained language models. Our analysis indicates that PeaCoK contains rich and precise world persona inferences that help downstream systems generate more consistent and engaging narratives.