 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawma: The Power of Specialization for Legal Tasks
Jul 23, 2024



Annotation and classification of legal text are central components of empirical legal research. Traditionally, these tasks are often delegated to trained research assistants. Motivated by the advances in language modeling, empirical legal scholars are increasingly turning to prompting commercial models, hoping that it will alleviate the significant cost of human annotation. Despite growing use, our understanding of how to best utilize large language models for legal tasks remains limited. We conduct a comprehensive study of 260 legal text classification tasks, nearly all new to the machine learning community. Starting from GPT-4 as a baseline, we show that it has non-trivial but highly varied zero-shot accuracy, often exhibiting performance that may be insufficient for legal work. We then demonstrate that a lightly fine-tuned Llama 3 model vastly outperforms GPT-4 on almost all tasks, typically by double-digit percentage points. We find that larger models respond better to fine-tuning than smaller models. A few tens to hundreds of examples suffice to achieve high classification accuracy. Notably, we can fine-tune a single model on all 260 tasks simultaneously at a small loss in accuracy relative to having a separate model for each task. Our work points to a viable alternative to the predominant practice of prompting commercial models. For concrete legal tasks with some available labeled data, researchers are better off using a fine-tuned open-source model.
Training on the Test Task Confounds Evaluation and Emergence
Jul 10, 2024



We study a fundamental problem in the evaluation of large language models that we call training on the test task. Unlike wrongful practices like training on the test data, leakage, or data contamination, training on the test task is not a malpractice. Rather, the term describes a growing set of techniques to include task-relevant data in the pretraining stage of a language model. We demonstrate that training on the test task confounds both relative model evaluations and claims about emergent capabilities. We argue that the seeming superiority of one model family over another may be explained by a different degree of training on the test task. To this end, we propose an effective method to adjust for training on the test task by fine-tuning each model under comparison on the same task-relevant data before evaluation. We then show that instances of emergent behavior largely vanish once we adjust for training on the test task. This also applies to reported instances of emergent behavior that cannot be explained by the choice of evaluation metric. Our work promotes a new perspective on the evaluation of large language models with broad implications for benchmarking and the study of emergent capabilities.
Questioning the Survey Responses of Large Language Models
Jun 13, 2023



As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models with varying scientific motivations. In this work, we examine what we can learn from a model's survey responses on the basis of the well-established American Community Survey (ACS) by the U.S. Census Bureau. Evaluating more than a dozen different models, varying in size from a few hundred million to ten billion parameters, hundreds of thousands of times each on questions from the ACS, we systematically establish two dominant patterns. First, smaller models have a significant position and labeling bias, for example, towards survey responses labeled with the letter "A". This A-bias diminishes, albeit slowly, as model size increases. Second, when adjusting for this labeling bias through randomized answer ordering, models still do not trend toward US population statistics or those of any cognizable population. Rather, models across the board trend toward uniformly random aggregate statistics over survey responses. This pattern is robust to various different ways of prompting the model, including what is the de-facto standard. Our findings demonstrate that aggregate statistics of a language model's survey responses lack the signals found in human populations. This absence of statistical signal cautions about the use of survey responses from large language models at present time.
On the Adversarial Robustness of Causal Algorithmic Recourse
Dec 21, 2021
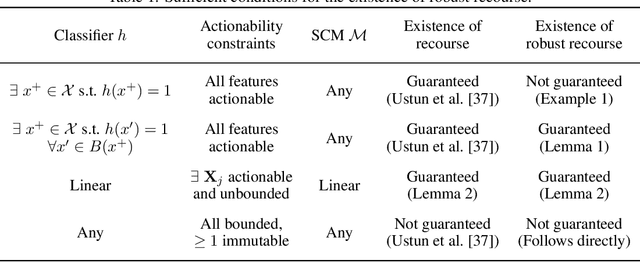
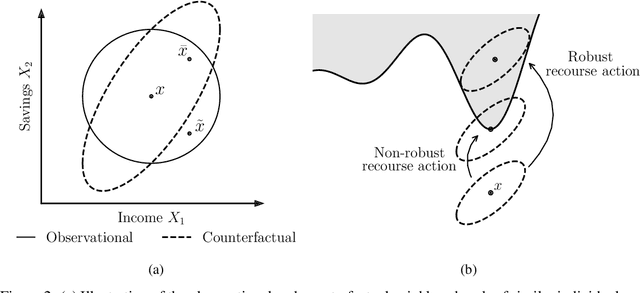
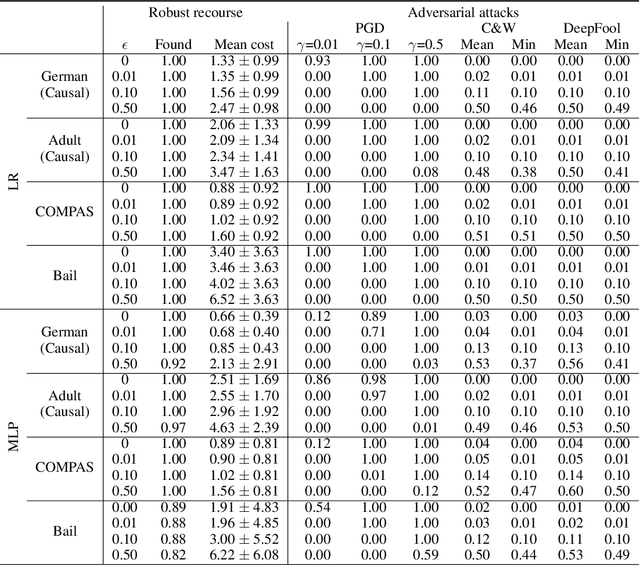
Algorithmic recourse seeks to provide actionable recommendations for individuals to overcome unfavorable outcomes made by automated decision-making systems. Recourse recommendations should ideally be robust to reasonably small uncertainty in the features of the individual seeking recourse. In this work, we formulate the adversarially robust recourse problem and show that recourse methods offering minimally costly recourse fail to be robust. We then present methods for generating adversarially robust recourse in the linear and in the differentiable case. To ensure that recourse is robust, individuals are asked to make more effort than they would have otherwise had to. In order to shift part of the burden of robustness from the decision-subject to the decision-maker, we propose a model regularizer that encourages the additional cost of seeking robust recourse to be low. We show that classifiers trained with our proposed model regularizer, which penalizes relying on unactionable features for prediction, offer potentially less effortful recourse.