 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022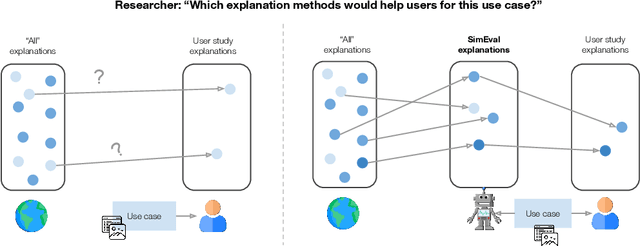
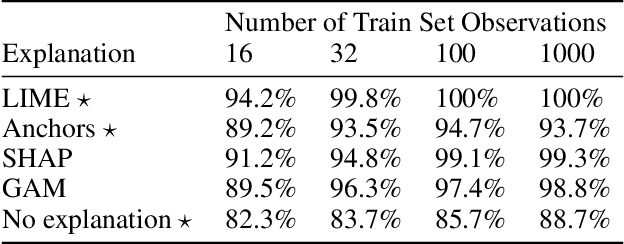
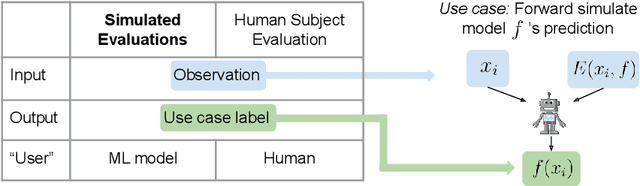
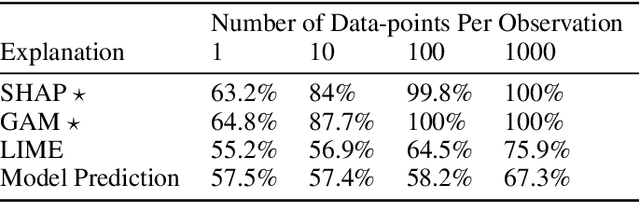
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
Perspectives on Incorporating Expert Feedback into Model Updates
May 13, 2022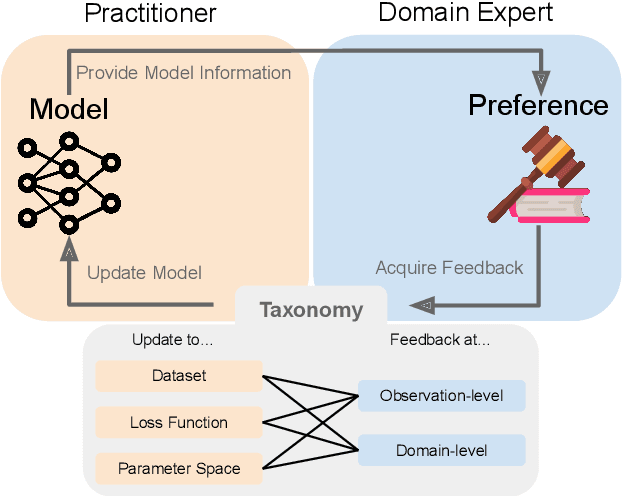
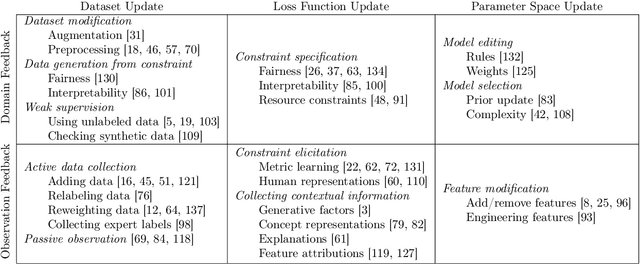
Machine learning (ML) practitioners are increasingly tasked with developing models that are aligned with non-technical experts' values and goals. However, there has been insufficient consideration on how practitioners should translate domain expertise into ML updates. In this paper, we consider how to capture interactions between practitioners and experts systematically. We devise a taxonomy to match expert feedback types with practitioner updates. A practitioner may receive feedback from an expert at the observation- or domain-level, and convert this feedback into updates to the dataset, loss function, or parameter space. We review existing work from ML and human-computer interaction to describe this feedback-update taxonomy, and highlight the insufficient consideration given to incorporating feedback from non-technical experts. We end with a set of open questions that naturally arise from our proposed taxonomy and subsequent survey.
Bayesian Persuasion for Algorithmic Recourse
Dec 12, 2021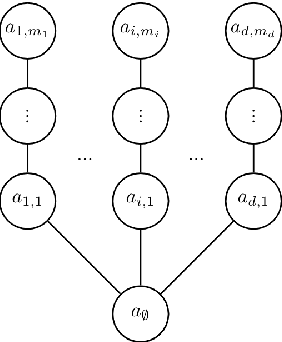
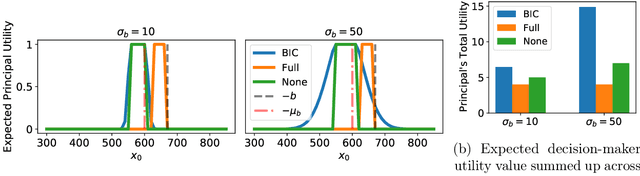
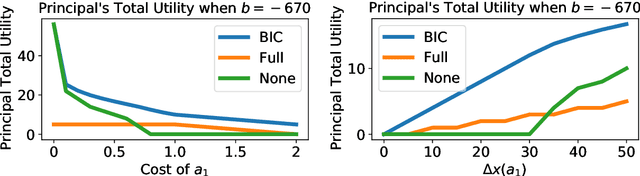
When subjected to automated decision-making, decision-subjects will strategically modify their observable features in ways they believe will maximize their chances of receiving a desirable outcome. In many situations, the underlying predictive model is deliberately kept secret to avoid gaming and maintain competitive advantage. This opacity forces the decision subjects to rely on incomplete information when making strategic feature modifications. We capture such settings as a game of Bayesian persuasion, in which the decision-maker sends a signal, e.g., an action recommendation, to a decision subject to incentivize them to take desirable actions. We formulate the decision-maker's problem of finding the optimal Bayesian incentive-compatible (BIC) action recommendation policy as an optimization problem and characterize the solution via a linear program. Through this characterization, we observe that while the problem of finding the optimal BIC recommendation policy can be simplified dramatically, the computational complexity of solving this linear program is closely tied to (1) the relative size of the decision-subjects' action space, and (2) the number of features utilized by the underlying predictive model. Finally, we provide bounds on the performance of the optimal BIC recommendation policy and show that it can lead to arbitrarily better outcomes compared to standard baselines.
Towards Connecting Use Cases and Methods in Interpretable Machine Learning
Mar 10, 2021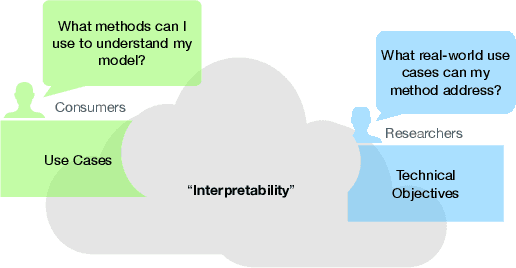

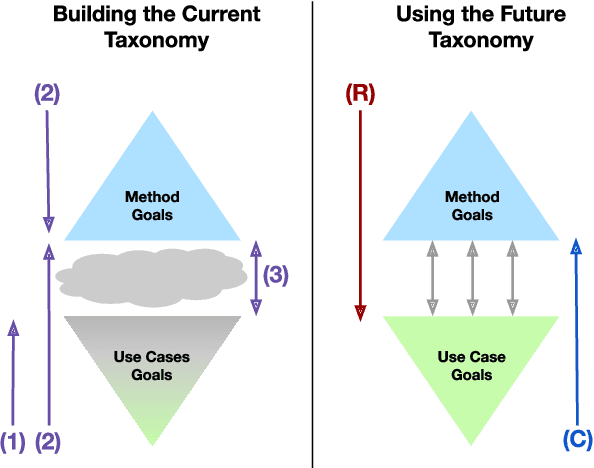
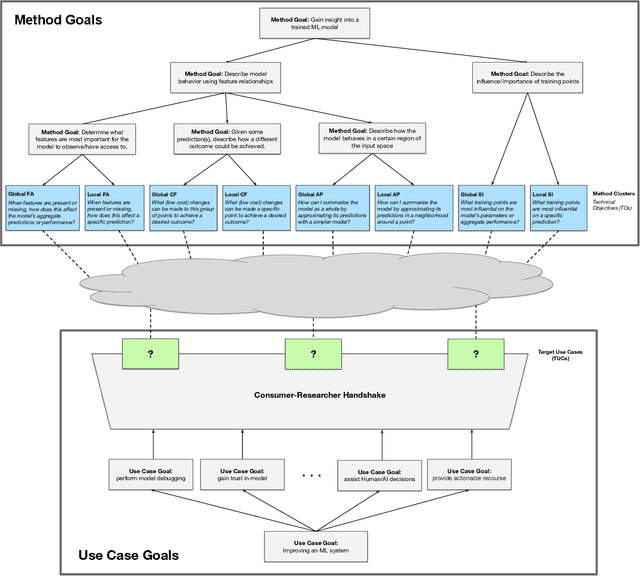
Despite increasing interest in the field of Interpretable Machine Learning (IML), a significant gap persists between the technical objectives targeted by researchers' methods and the high-level goals of consumers' use cases. In this work, we synthesize foundational work on IML methods and evaluation into an actionable taxonomy. This taxonomy serves as a tool to conceptualize the gap between researchers and consumers, illustrated by the lack of connections between its methods and use cases components. It also provides the foundation from which we describe a three-step workflow to better enable researchers and consumers to work together to discover what types of methods are useful for what use cases. Eventually, by building on the results generated from this workflow, a more complete version of the taxonomy will increasingly allow consumers to find relevant methods for their target use cases and researchers to identify applicable use cases for their proposed methods.
Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning
Nov 01, 2020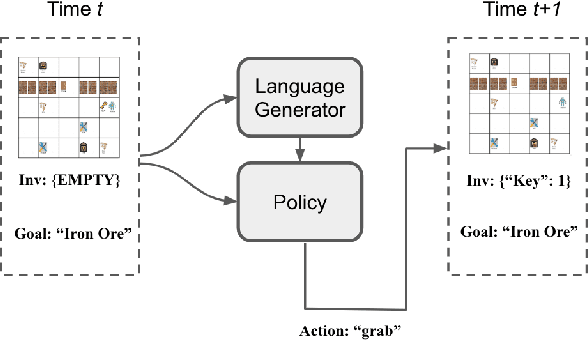
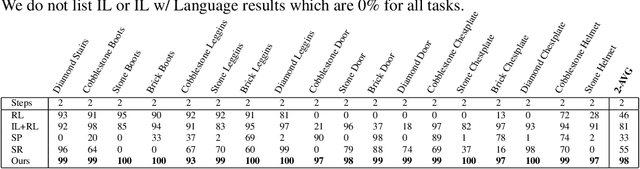
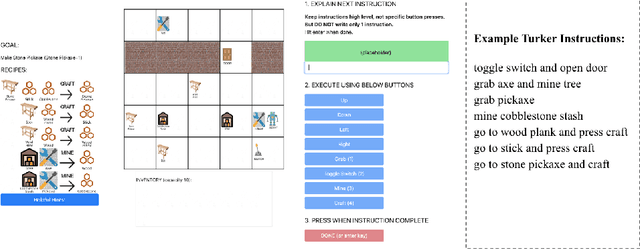

Complex, multi-task problems have proven to be difficult to solve efficiently in a sparse-reward reinforcement learning setting. In order to be sample efficient, multi-task learning requires reuse and sharing of low-level policies. To facilitate the automatic decomposition of hierarchical tasks, we propose the use of step-by-step human demonstrations in the form of natural language instructions and action trajectories. We introduce a dataset of such demonstrations in a crafting-based grid world. Our model consists of a high-level language generator and low-level policy, conditioned on language. We find that human demonstrations help solve the most complex tasks. We also find that incorporating natural language allows the model to generalize to unseen tasks in a zero-shot setting and to learn quickly from a few demonstrations. Generalization is not only reflected in the actions of the agent, but also in the generated natural language instructions in unseen tasks. Our approach also gives our trained agent interpretable behaviors because it is able to generate a sequence of high-level descriptions of its actions.
Novelty Detection via Network Saliency in Visual-based Deep Learning
Jun 09, 2019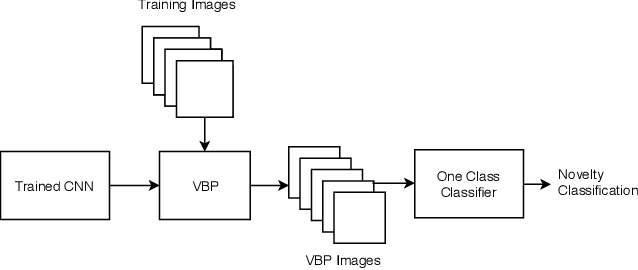
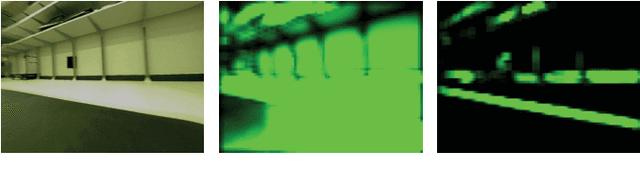


Machine-learning driven safety-critical autonomous systems, such as self-driving cars, must be able to detect situations where its trained model is not able to make a trustworthy prediction. Often viewed as a black-box, it is non-obvious to determine when a model will make a safe decision and when it will make an erroneous, perhaps life-threatening one. Prior work on novelty detection deal with highly structured data and do not translate well to dynamic, real-world situations. This paper proposes a multi-step framework for the detection of novel scenarios in vision-based autonomous systems by leveraging information learned by the trained prediction model and a new image similarity metric. We demonstrate the efficacy of this method through experiments on a real-world driving dataset as well as on our in-house indoor racing environment.