 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Jul 11, 2024



Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population.
EAGLE: Efficient Adaptive Geometry-based Learning in Cross-view Understanding
Jun 03, 2024



Unsupervised Domain Adaptation has been an efficient approach to transferring the semantic segmentation model across data distributions. Meanwhile, the recent Open-vocabulary Semantic Scene understanding based on large-scale vision language models is effective in open-set settings because it can learn diverse concepts and categories. However, these prior methods fail to generalize across different camera views due to the lack of cross-view geometric modeling. At present, there are limited studies analyzing cross-view learning. To address this problem, we introduce a novel Unsupervised Cross-view Adaptation Learning approach to modeling the geometric structural change across views in Semantic Scene Understanding. First, we introduce a novel Cross-view Geometric Constraint on Unpaired Data to model structural changes in images and segmentation masks across cameras. Second, we present a new Geodesic Flow-based Correlation Metric to efficiently measure the geometric structural changes across camera views. Third, we introduce a novel view-condition prompting mechanism to enhance the view-information modeling of the open-vocabulary segmentation network in cross-view adaptation learning. The experiments on different cross-view adaptation benchmarks have shown the effectiveness of our approach in cross-view modeling, demonstrating that we achieve State-of-the-Art (SOTA) performance compared to prior unsupervised domain adaptation and open-vocabulary semantic segmentation methods.
FALCON: Fairness Learning via Contrastive Attention Approach to Continual Semantic Scene Understanding in Open World
Nov 27, 2023Continual Learning in semantic scene segmentation aims to continually learn new unseen classes in dynamic environments while maintaining previously learned knowledge. Prior studies focused on modeling the catastrophic forgetting and background shift challenges in continual learning. However, fairness, another major challenge that causes unfair predictions leading to low performance among major and minor classes, still needs to be well addressed. In addition, prior methods have yet to model the unknown classes well, thus resulting in producing non-discriminative features among unknown classes. This paper presents a novel Fairness Learning via Contrastive Attention Approach to continual learning in semantic scene understanding. In particular, we first introduce a new Fairness Contrastive Clustering loss to address the problems of catastrophic forgetting and fairness. Then, we propose an attention-based visual grammar approach to effectively model the background shift problem and unknown classes, producing better feature representations for different unknown classes. Through our experiments, our proposed approach achieves State-of-the-Art (SOTA) performance on different continual learning settings of three standard benchmarks, i.e., ADE20K, Cityscapes, and Pascal VOC. It promotes the fairness of the continual semantic segmentation model.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
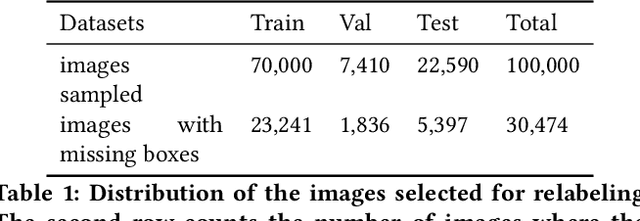
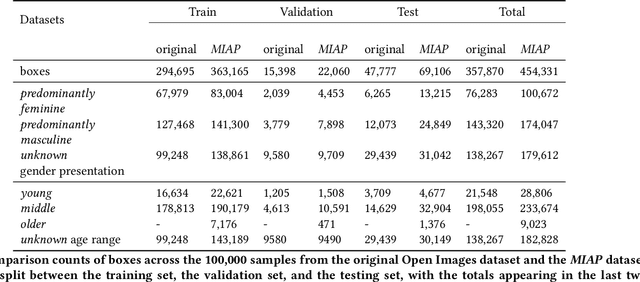
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
Large-Scale Visual Speech Recognition
Oct 01, 2018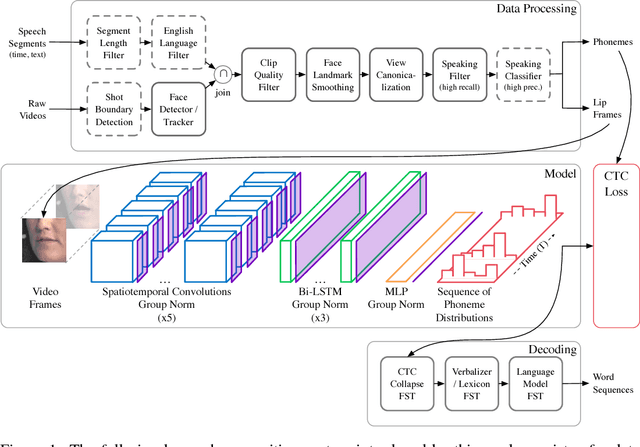
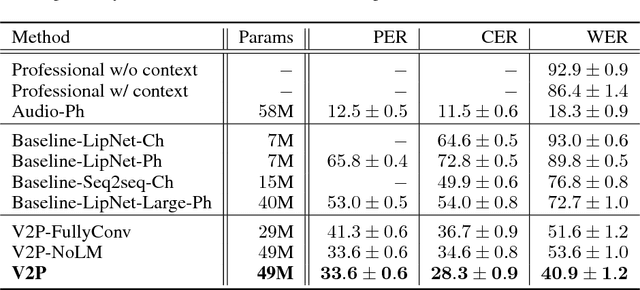


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.