 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Many Worlds: Towards Open-Ended Discovery in Petri Dish NCA via Population-Based Training
Apr 13, 2026The generation of sustained, open-ended complexity from local interactions remains a fundamental challenge in artificial life. Differentiable multi-agent systems, such as Petri Dish Neural Cellular Automata (PD-NCA), exhibit rich self-organization driven purely by spatial competition; however, they are highly sensitive to hyperparameters and frequently collapse into uninteresting patterns and dynamics, such as frozen equilibria or structureless noise. In this paper, we introduce PBT-NCA, a meta-evolutionary algorithm that evolves a population of PD-NCAs subject to a composite objective that rewards both historical behavioral novelty and contemporary visual diversity. Driven by this continuous evolutionary pressure, PBT-NCA spontaneously generates a plethora of emergent lifelike phenomena over extended horizons-a hallmark of true open-endedness. Strikingly, the substrate autonomously discovers diverse morphological survival and self-organization strategies. We observe highly regular, coordinated periodic waves; spore-like scattering where homogeneous groups eject cell-like clusters to colonize distant territories; and fluid, shape-shifting macro-structures that migrate across the substrate, maintaining stable outer boundaries that enclose highly active interiors. By actively penalizing monocultures and dead states, PBT-NCA sustains a state of effective complexity that is neither globally ordered nor globally random, operating persistently at the "edge of chaos".
When Do We Need LLMs? A Diagnostic for Language-Driven Bandits
Apr 07, 2026We study Contextual Multi-Armed Bandits (CMABs) for non-episodic sequential decision making problems where the context includes both textual and numerical information (e.g., recommendation systems, dynamic portfolio adjustments, offer selection; all frequent problems in finance). While Large Language Models (LLMs) are increasingly applied to these settings, utilizing LLMs for reasoning at every decision step is computationally expensive and uncertainty estimates are difficult to obtain. To address this, we introduce LLMP-UCB, a bandit algorithm that derives uncertainty estimates from LLMs via repeated inference. However, our experiments demonstrate that lightweight numerical bandits operating on text embeddings (dense or Matryoshka) match or exceed the accuracy of LLM-based solutions at a fraction of their cost. We further show that embedding dimensionality is a practical lever on the exploration-exploitation balance, enabling cost--performance tradeoffs without prompt complexity. Finally, to guide practitioners, we propose a geometric diagnostic based on the arms' embedding to decide when to use LLM-driven reasoning versus a lightweight numerical bandit. Our results provide a principled deployment framework for cost-effective, uncertainty-aware decision systems with broad applicability across AI use cases in financial services.
Procedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
Intent Factored Generation: Unleashing the Diversity in Your Language Model
Jun 11, 2025Obtaining multiple meaningfully diverse, high quality samples from Large Language Models for a fixed prompt remains an open challenge. Current methods for increasing diversity often only operate at the token-level, paraphrasing the same response. This is problematic because it leads to poor exploration on reasoning problems and to unengaging, repetitive conversational agents. To address this we propose Intent Factored Generation (IFG), factorising the sampling process into two stages. First, we sample a semantically dense intent, e.g., a summary or keywords. Second, we sample the final response conditioning on both the original prompt and the intent from the first stage. This allows us to use a higher temperature during the intent step to promote conceptual diversity, and a lower temperature during the final generation to ensure the outputs are coherent and self-consistent. Additionally, we find that prompting the model to explicitly state its intent for each step of the chain-of-thought before generating the step is beneficial for reasoning tasks. We demonstrate our method's effectiveness across a diverse set of tasks. We show this method improves both pass@k and Reinforcement Learning from Verifier Feedback on maths and code tasks. For instruction-tuning, we combine IFG with Direct Preference Optimisation to increase conversational diversity without sacrificing reward. Finally, we achieve higher diversity while maintaining the quality of generations on a general language modelling task, using a new dataset of reader comments and news articles that we collect and open-source. In summary, we present a simple method of increasing the sample diversity of LLMs while maintaining performance. This method can be implemented by changing the prompt and varying the temperature during generation, making it easy to integrate into many algorithms for gains across various applications.
SOReL and TOReL: Two Methods for Fully Offline Reinforcement Learning
May 28, 2025Sample efficiency remains a major obstacle for real world adoption of reinforcement learning (RL): success has been limited to settings where simulators provide access to essentially unlimited environment interactions, which in reality are typically costly or dangerous to obtain. Offline RL in principle offers a solution by exploiting offline data to learn a near-optimal policy before deployment. In practice, however, current offline RL methods rely on extensive online interactions for hyperparameter tuning, and have no reliable bound on their initial online performance. To address these two issues, we introduce two algorithms. Firstly, SOReL: an algorithm for safe offline reinforcement learning. Using only offline data, our Bayesian approach infers a posterior over environment dynamics to obtain a reliable estimate of the online performance via the posterior predictive uncertainty. Crucially, all hyperparameters are also tuned fully offline. Secondly, we introduce TOReL: a tuning for offline reinforcement learning algorithm that extends our information rate based offline hyperparameter tuning methods to general offline RL approaches. Our empirical evaluation confirms SOReL's ability to accurately estimate regret in the Bayesian setting whilst TOReL's offline hyperparameter tuning achieves competitive performance with the best online hyperparameter tuning methods using only offline data. Thus, SOReL and TOReL make a significant step towards safe and reliable offline RL, unlocking the potential for RL in the real world. Our implementations are publicly available: https://github.com/CWibault/sorel\_torel.
A Clean Slate for Offline Reinforcement Learning
Apr 15, 2025



Progress in offline reinforcement learning (RL) has been impeded by ambiguous problem definitions and entangled algorithmic designs, resulting in inconsistent implementations, insufficient ablations, and unfair evaluations. Although offline RL explicitly avoids environment interaction, prior methods frequently employ extensive, undocumented online evaluation for hyperparameter tuning, complicating method comparisons. Moreover, existing reference implementations differ significantly in boilerplate code, obscuring their core algorithmic contributions. We address these challenges by first introducing a rigorous taxonomy and a transparent evaluation protocol that explicitly quantifies online tuning budgets. To resolve opaque algorithmic design, we provide clean, minimalistic, single-file implementations of various model-free and model-based offline RL methods, significantly enhancing clarity and achieving substantial speed-ups. Leveraging these streamlined implementations, we propose Unifloral, a unified algorithm that encapsulates diverse prior approaches within a single, comprehensive hyperparameter space, enabling algorithm development in a shared hyperparameter space. Using Unifloral with our rigorous evaluation protocol, we develop two novel algorithms - TD3-AWR (model-free) and MoBRAC (model-based) - which substantially outperform established baselines. Our implementation is publicly available at https://github.com/EmptyJackson/unifloral.
Reinforcement Learning Controllers for Soft Robots using Learned Environments
Oct 25, 2024



Soft robotic manipulators offer operational advantage due to their compliant and deformable structures. However, their inherently nonlinear dynamics presents substantial challenges. Traditional analytical methods often depend on simplifying assumptions, while learning-based techniques can be computationally demanding and limit the control policies to existing data. This paper introduces a novel approach to soft robotic control, leveraging state-of-the-art policy gradient methods within parallelizable synthetic environments learned from data. We also propose a safety oriented actuation space exploration protocol via cascaded updates and weighted randomness. Specifically, our recurrent forward dynamics model is learned by generating a training dataset from a physically safe \textit{mean reverting} random walk in actuation space to explore the partially-observed state-space. We demonstrate a reinforcement learning approach towards closed-loop control through state-of-the-art actor-critic methods, which efficiently learn high-performance behaviour over long horizons. This approach removes the need for any knowledge regarding the robot's operation or capabilities and sets the stage for a comprehensive benchmarking tool in soft robotics control.
* soft manipulator, reinforcement learning, learned controllers
Towards Reinforcement Learning Controllers for Soft Robots using Learned Environments
Oct 24, 2024Soft robotic manipulators offer operational advantage due to their compliant and deformable structures. However, their inherently nonlinear dynamics presents substantial challenges. Traditional analytical methods often depend on simplifying assumptions, while learning-based techniques can be computationally demanding and limit the control policies to existing data. This paper introduces a novel approach to soft robotic control, leveraging state-of-the-art policy gradient methods within parallelizable synthetic environments learned from data. We also propose a safety oriented actuation space exploration protocol via cascaded updates and weighted randomness. Specifically, our recurrent forward dynamics model is learned by generating a training dataset from a physically safe \textit{mean reverting} random walk in actuation space to explore the partially-observed state-space. We demonstrate a reinforcement learning approach towards closed-loop control through state-of-the-art actor-critic methods, which efficiently learn high-performance behaviour over long horizons. This approach removes the need for any knowledge regarding the robot's operation or capabilities and sets the stage for a comprehensive benchmarking tool in soft robotics control.
* soft manipulator, reinforcement learning, learned controllers
Mobile 3D Printing Robot Simulation with Viscoelastic Fluids
Oct 08, 2021
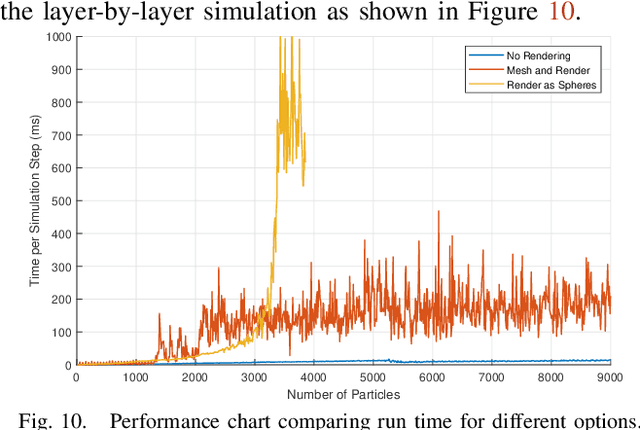
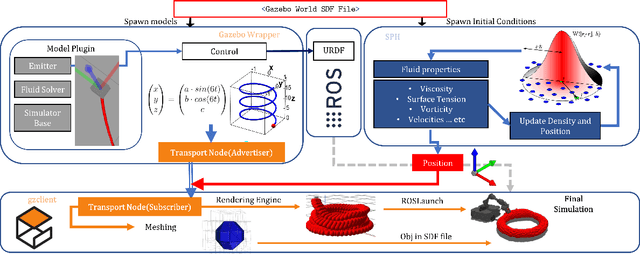
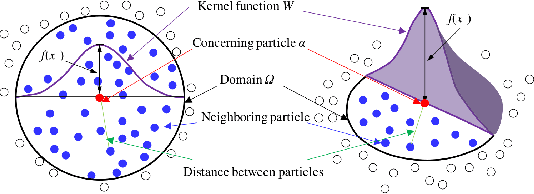
The system design and algorithm development of mobile 3D printing robots need a realistic simulation. They require a mobile robot simulation platform to interoperate with a physics-based material simulation for handling interactions between the time-variant deformable 3D printing materials and other simulated rigid bodies in the environment, which is not available for roboticists yet. To bridge this gap and enable the real-time simulation of mobile 3D printing processes, we develop a simulation framework that includes particle-based viscoelastic fluid simulation and particle-to-mesh conversion in the widely adopted Gazebo robotics simulator, avoiding the bottlenecks of traditional additive manufacturing simulation approaches. This framework is the first of its kind that enables the simulation of robot arms or mobile manipulators together with viscoelastic fluids. The method is tested using various material properties and multiple collaborating robots to demonstrate its simulation ability for the robots to plan and control the printhead trajectories and to visually sense at the same time the printed fluid materials as a free-form mesh. The scalability as a function of available material particles in the simulation was also studied. A simulation with an average of 5 FPS was achieved on a regular desktop computer.