 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Factored Generation: Unleashing the Diversity in Your Language Model
Jun 11, 2025Obtaining multiple meaningfully diverse, high quality samples from Large Language Models for a fixed prompt remains an open challenge. Current methods for increasing diversity often only operate at the token-level, paraphrasing the same response. This is problematic because it leads to poor exploration on reasoning problems and to unengaging, repetitive conversational agents. To address this we propose Intent Factored Generation (IFG), factorising the sampling process into two stages. First, we sample a semantically dense intent, e.g., a summary or keywords. Second, we sample the final response conditioning on both the original prompt and the intent from the first stage. This allows us to use a higher temperature during the intent step to promote conceptual diversity, and a lower temperature during the final generation to ensure the outputs are coherent and self-consistent. Additionally, we find that prompting the model to explicitly state its intent for each step of the chain-of-thought before generating the step is beneficial for reasoning tasks. We demonstrate our method's effectiveness across a diverse set of tasks. We show this method improves both pass@k and Reinforcement Learning from Verifier Feedback on maths and code tasks. For instruction-tuning, we combine IFG with Direct Preference Optimisation to increase conversational diversity without sacrificing reward. Finally, we achieve higher diversity while maintaining the quality of generations on a general language modelling task, using a new dataset of reader comments and news articles that we collect and open-source. In summary, we present a simple method of increasing the sample diversity of LLMs while maintaining performance. This method can be implemented by changing the prompt and varying the temperature during generation, making it easy to integrate into many algorithms for gains across various applications.
Towards Reliable Identification of Diffusion-based Image Manipulations
Jun 05, 2025Changing facial expressions, gestures, or background details may dramatically alter the meaning conveyed by an image. Notably, recent advances in diffusion models greatly improve the quality of image manipulation while also opening the door to misuse. Identifying changes made to authentic images, thus, becomes an important task, constantly challenged by new diffusion-based editing tools. To this end, we propose a novel approach for ReliAble iDentification of inpainted AReas (RADAR). RADAR builds on existing foundation models and combines features from different image modalities. It also incorporates an auxiliary contrastive loss that helps to isolate manipulated image patches. We demonstrate these techniques to significantly improve both the accuracy of our method and its generalisation to a large number of diffusion models. To support realistic evaluation, we further introduce BBC-PAIR, a new comprehensive benchmark, with images tampered by 28 diffusion models. Our experiments show that RADAR achieves excellent results, outperforming the state-of-the-art in detecting and localising image edits made by both seen and unseen diffusion models. Our code, data and models will be publicly available at alex-costanzino.github.io/radar.
Topology Distance: A Topology-Based Approach For Evaluating Generative Adversarial Networks
Feb 27, 2020
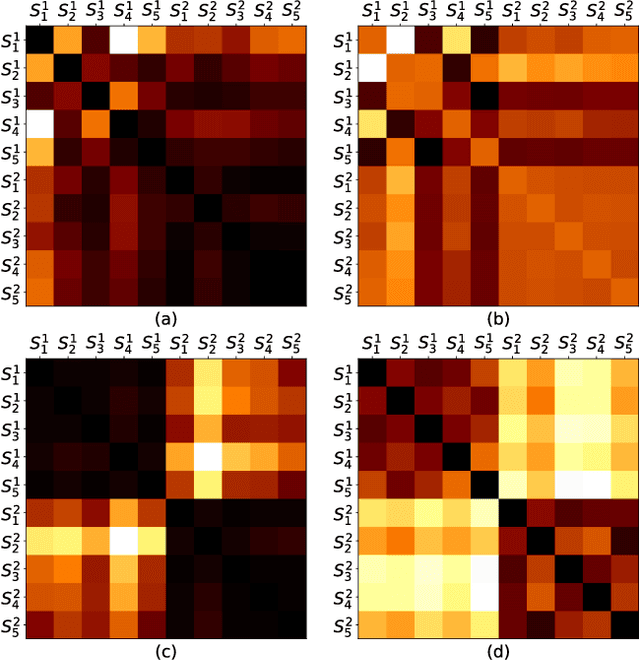
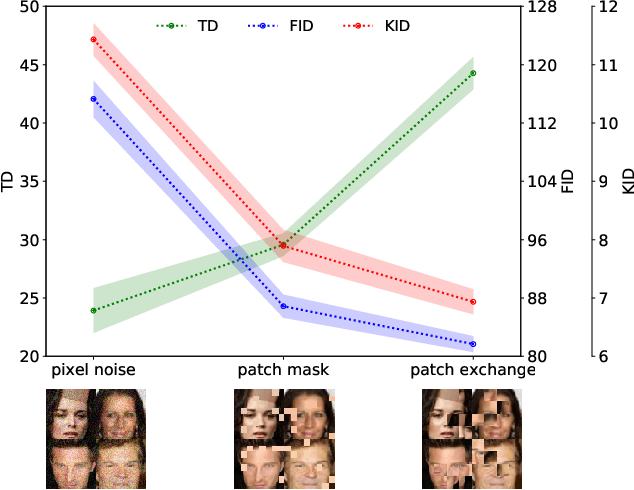
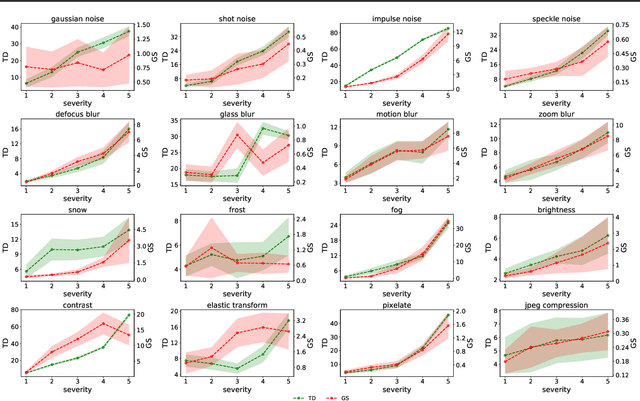
Automatic evaluation of the goodness of Generative Adversarial Networks (GANs) has been a challenge for the field of machine learning. In this work, we propose a distance complementary to existing measures: Topology Distance (TD), the main idea behind which is to compare the geometric and topological features of the latent manifold of real data with those of generated data. More specifically, we build Vietoris-Rips complex on image features, and define TD based on the differences in persistent-homology groups of the two manifolds. We compare TD with the most commonly used and relevant measures in the field, including Inception Score (IS), Frechet Inception Distance (FID), Kernel Inception Distance (KID) and Geometry Score (GS), in a range of experiments on various datasets. We demonstrate the unique advantage and superiority of our proposed approach over the aforementioned metrics. A combination of our empirical results and the theoretical argument we propose in favour of TD, strongly supports the claim that TD is a powerful candidate metric that researchers can employ when aiming to automatically evaluate the goodness of GANs' learning.