 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Privacy in Graph Neural Networks: Attacks, Preservation, and Applications
Sep 19, 2023



Graph Neural Networks (GNNs) have gained significant attention owing to their ability to handle graph-structured data and the improvement in practical applications. However, many of these models prioritize high utility performance, such as accuracy, with a lack of privacy consideration, which is a major concern in modern society where privacy attacks are rampant. To address this issue, researchers have started to develop privacy-preserving GNNs. Despite this progress, there is a lack of a comprehensive overview of the attacks and the techniques for preserving privacy in the graph domain. In this survey, we aim to address this gap by summarizing the attacks on graph data according to the targeted information, categorizing the privacy preservation techniques in GNNs, and reviewing the datasets and applications that could be used for analyzing/solving privacy issues in GNNs. We also outline potential directions for future research in order to build better privacy-preserving GNNs.
Knowledge Graph Prompting for Multi-Document Question Answering
Aug 22, 2023



The 'pre-train, prompt, predict' paradigm of large language models (LLMs) has achieved remarkable success in open-domain question answering (OD-QA). However, few works explore this paradigm in the scenario of multi-document question answering (MD-QA), a task demanding a thorough understanding of the logical associations among the contents and structures of different documents. To fill this crucial gap, we propose a Knowledge Graph Prompting (KGP) method to formulate the right context in prompting LLMs for MD-QA, which consists of a graph construction module and a graph traversal module. For graph construction, we create a knowledge graph (KG) over multiple documents with nodes symbolizing passages or document structures (e.g., pages/tables), and edges denoting the semantic/lexical similarity between passages or intra-document structural relations. For graph traversal, we design an LM-guided graph traverser that navigates across nodes and gathers supporting passages assisting LLMs in MD-QA. The constructed graph serves as the global ruler that regulates the transitional space among passages and reduces retrieval latency. Concurrently, the LM-guided traverser acts as a local navigator that gathers pertinent context to progressively approach the question and guarantee retrieval quality. Extensive experiments underscore the efficacy of KGP for MD-QA, signifying the potential of leveraging graphs in enhancing the prompt design for LLMs. Our code is at https://github.com/YuWVandy/KG-LLM-MDQA.
Fairness and Diversity in Recommender Systems: A Survey
Jul 10, 2023



Recommender systems are effective tools for mitigating information overload and have seen extensive applications across various domains. However, the single focus on utility goals proves to be inadequate in addressing real-world concerns, leading to increasing attention to fairness-aware and diversity-aware recommender systems. While most existing studies explore fairness and diversity independently, we identify strong connections between these two domains. In this survey, we first discuss each of them individually and then dive into their connections. Additionally, motivated by the concepts of user-level and item-level fairness, we broaden the understanding of diversity to encompass not only the item level but also the user level. With this expanded perspective on user and item-level diversity, we re-interpret fairness studies from the viewpoint of diversity. This fresh perspective enhances our understanding of fairness-related work and paves the way for potential future research directions. Papers discussed in this survey along with public code links are available at https://github.com/YuyingZhao/Awesome-Fairness-and-Diversity-Papers-in-Recommender-Systems .
NeuroGraph: Benchmarks for Graph Machine Learning in Brain Connectomics
Jun 25, 2023Machine learning provides a valuable tool for analyzing high-dimensional functional neuroimaging data, and is proving effective in predicting various neurological conditions, psychiatric disorders, and cognitive patterns. In functional Magnetic Resonance Imaging (MRI) research, interactions between brain regions are commonly modeled using graph-based representations. The potency of graph machine learning methods has been established across myriad domains, marking a transformative step in data interpretation and predictive modeling. Yet, despite their promise, the transposition of these techniques to the neuroimaging domain remains surprisingly under-explored due to the expansive preprocessing pipeline and large parameter search space for graph-based datasets construction. In this paper, we introduce NeuroGraph, a collection of graph-based neuroimaging datasets that span multiple categories of behavioral and cognitive traits. We delve deeply into the dataset generation search space by crafting 35 datasets within both static and dynamic contexts, running in excess of 15 baseline methods for benchmarking. Additionally, we provide generic frameworks for learning on dynamic as well as static graphs. Our extensive experiments lead to several key observations. Notably, using correlation vectors as node features, incorporating larger number of regions of interest, and employing sparser graphs lead to improved performance. To foster further advancements in graph-based data driven Neuroimaging, we offer a comprehensive open source Python package that includes the datasets, baseline implementations, model training, and standard evaluation. The package is publicly accessible at https://anwar-said.github.io/anwarsaid/neurograph.html .
Fairness and Explainability: Bridging the Gap Towards Fair Model Explanations
Dec 07, 2022While machine learning models have achieved unprecedented success in real-world applications, they might make biased/unfair decisions for specific demographic groups and hence result in discriminative outcomes. Although research efforts have been devoted to measuring and mitigating bias, they mainly study bias from the result-oriented perspective while neglecting the bias encoded in the decision-making procedure. This results in their inability to capture procedure-oriented bias, which therefore limits the ability to have a fully debiasing method. Fortunately, with the rapid development of explainable machine learning, explanations for predictions are now available to gain insights into the procedure. In this work, we bridge the gap between fairness and explainability by presenting a novel perspective of procedure-oriented fairness based on explanations. We identify the procedure-based bias by measuring the gap of explanation quality between different groups with Ratio-based and Value-based Explanation Fairness. The new metrics further motivate us to design an optimization objective to mitigate the procedure-based bias where we observe that it will also mitigate bias from the prediction. Based on our designed optimization objective, we propose a Comprehensive Fairness Algorithm (CFA), which simultaneously fulfills multiple objectives - improving traditional fairness, satisfying explanation fairness, and maintaining the utility performance. Extensive experiments on real-world datasets demonstrate the effectiveness of our proposed CFA and highlight the importance of considering fairness from the explainability perspective. Our code is publicly available at https://github.com/YuyingZhao/FairExplanations-CFA .
Collaboration-Aware Graph Convolutional Networks for Recommendation Systems
Jul 03, 2022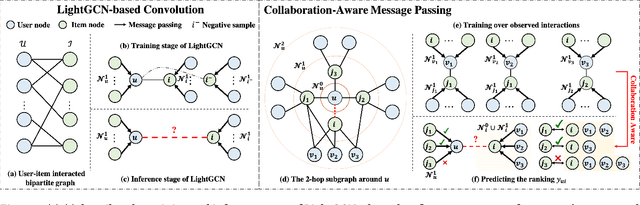
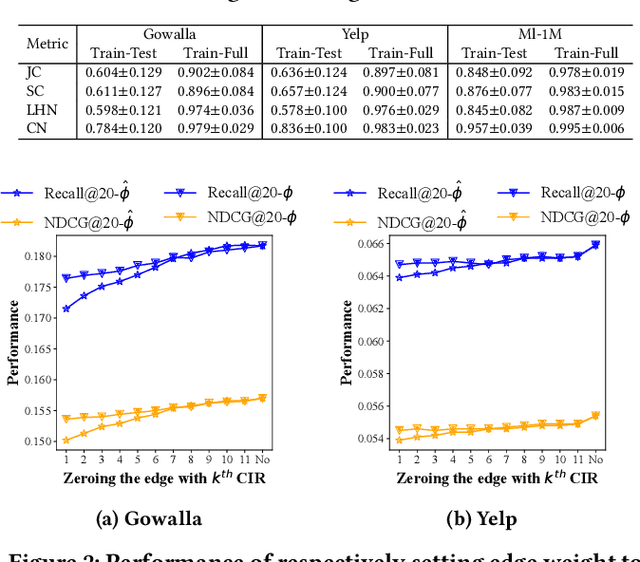
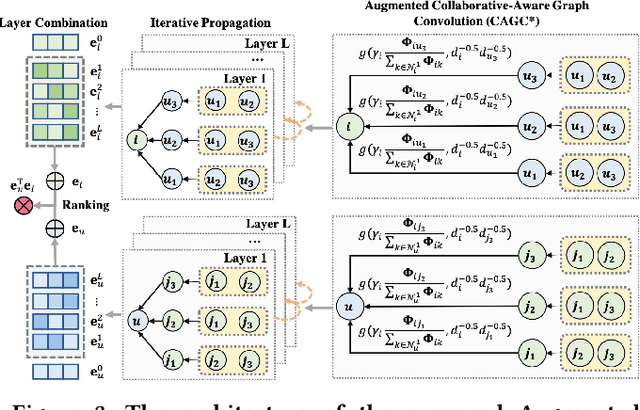
By virtue of the message-passing that implicitly injects collaborative effect into the embedding process, Graph Neural Networks (GNNs) have been successfully adopted in recommendation systems. Nevertheless, most of existing message-passing mechanisms in recommendation are directly inherited from GNNs without any recommendation-tailored modification. Although some efforts have been made towards simplifying GNNs to improve the performance/efficiency of recommendation, no study has comprehensively scrutinized how message-passing captures collaborative effect and whether the captured effect would benefit the prediction of user preferences over items. Therefore, in this work we aim to demystify the collaborative effect captured by message-passing in GNNs and develop new insights towards customizing message-passing for recommendation. First, we theoretically analyze how message-passing captures and leverages the collaborative effect in predicting user preferences. Then, to determine whether the captured collaborative effect would benefit the prediction of user preferences, we propose a recommendation-oriented topological metric, Common Interacted Ratio (CIR), which measures the level of interaction between a specific neighbor of a node with the rest of its neighborhood set. Inspired by our theoretical and empirical analysis, we propose a recommendation-tailored GNN, Augmented Collaboration-Aware Graph Convolutional Network (CAGCN*), that extends upon the LightGCN framework and is able to selectively pass information of neighbors based on their CIR via the Collaboration-Aware Graph Convolution. Experimental results on six benchmark datasets show that CAGCN* outperforms the most representative GNN-based recommendation model, LightGCN, by 9% in Recall@20 and also achieves more than 79% speedup. Our code is publicly available at https://github.com/YuWVandy/CAGCN.
On Structural Explanation of Bias in Graph Neural Networks
Jun 24, 2022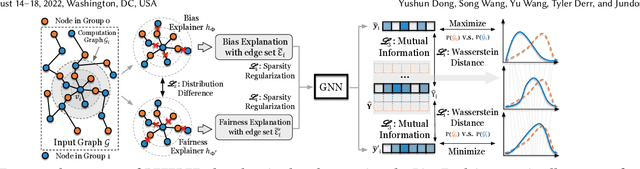
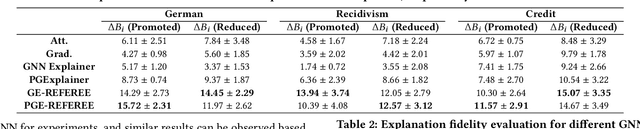
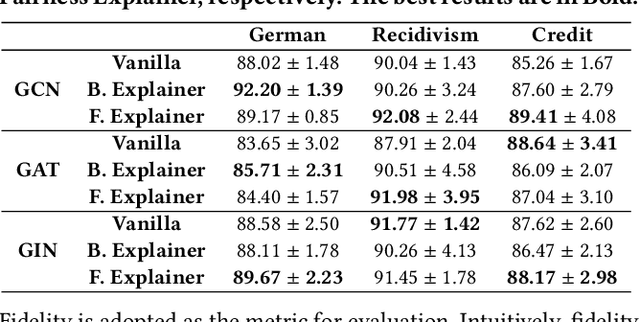
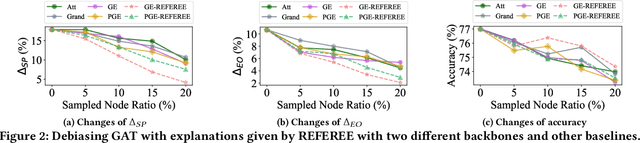
Graph Neural Networks (GNNs) have shown satisfying performance in various graph analytical problems. Hence, they have become the \emph{de facto} solution in a variety of decision-making scenarios. However, GNNs could yield biased results against certain demographic subgroups. Some recent works have empirically shown that the biased structure of the input network is a significant source of bias for GNNs. Nevertheless, no studies have systematically scrutinized which part of the input network structure leads to biased predictions for any given node. The low transparency on how the structure of the input network influences the bias in GNN outcome largely limits the safe adoption of GNNs in various decision-critical scenarios. In this paper, we study a novel research problem of structural explanation of bias in GNNs. Specifically, we propose a novel post-hoc explanation framework to identify two edge sets that can maximally account for the exhibited bias and maximally contribute to the fairness level of the GNN prediction for any given node, respectively. Such explanations not only provide a comprehensive understanding of bias/fairness of GNN predictions but also have practical significance in building an effective yet fair GNN model. Extensive experiments on real-world datasets validate the effectiveness of the proposed framework towards delivering effective structural explanations for the bias of GNNs. Open-source code can be found at https://github.com/yushundong/REFEREE.
Improving Fairness in Graph Neural Networks via Mitigating Sensitive Attribute Leakage
Jun 09, 2022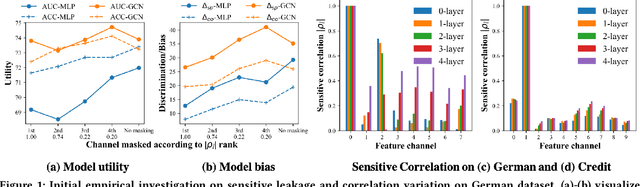
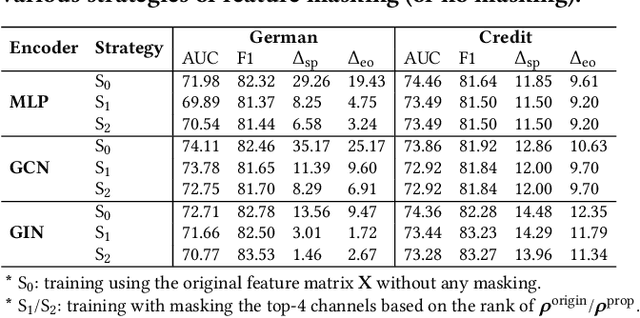
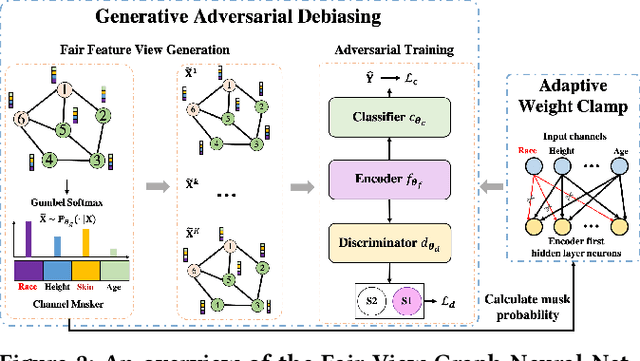

Graph Neural Networks (GNNs) have shown great power in learning node representations on graphs. However, they may inherit historical prejudices from training data, leading to discriminatory bias in predictions. Although some work has developed fair GNNs, most of them directly borrow fair representation learning techniques from non-graph domains without considering the potential problem of sensitive attribute leakage caused by feature propagation in GNNs. However, we empirically observe that feature propagation could vary the correlation of previously innocuous non-sensitive features to the sensitive ones. This can be viewed as a leakage of sensitive information which could further exacerbate discrimination in predictions. Thus, we design two feature masking strategies according to feature correlations to highlight the importance of considering feature propagation and correlation variation in alleviating discrimination. Motivated by our analysis, we propose Fair View Graph Neural Network (FairVGNN) to generate fair views of features by automatically identifying and masking sensitive-correlated features considering correlation variation after feature propagation. Given the learned fair views, we adaptively clamp weights of the encoder to avoid using sensitive-related features. Experiments on real-world datasets demonstrate that FairVGNN enjoys a better trade-off between model utility and fairness. Our code is publicly available at https://github.com/YuWVandy/FairVGNN.
ChemicalX: A Deep Learning Library for Drug Pair Scoring
Feb 14, 2022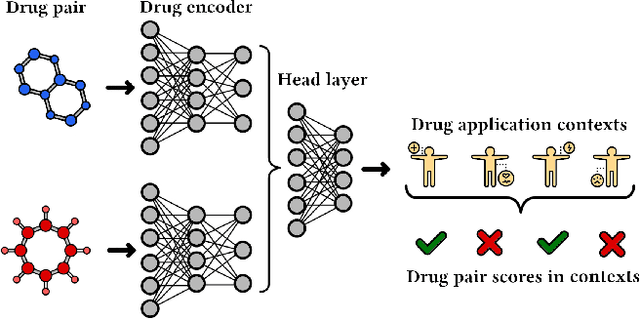
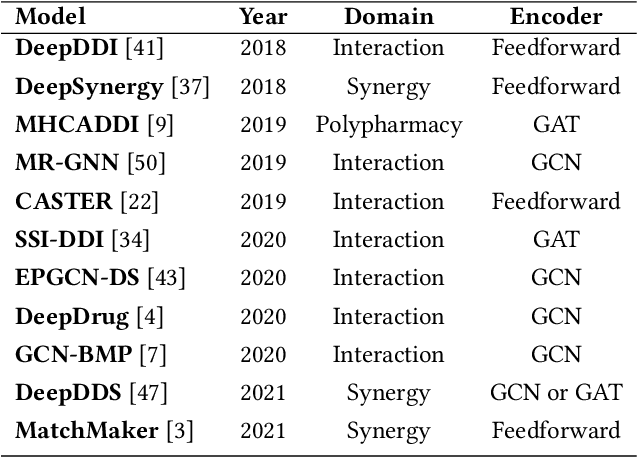
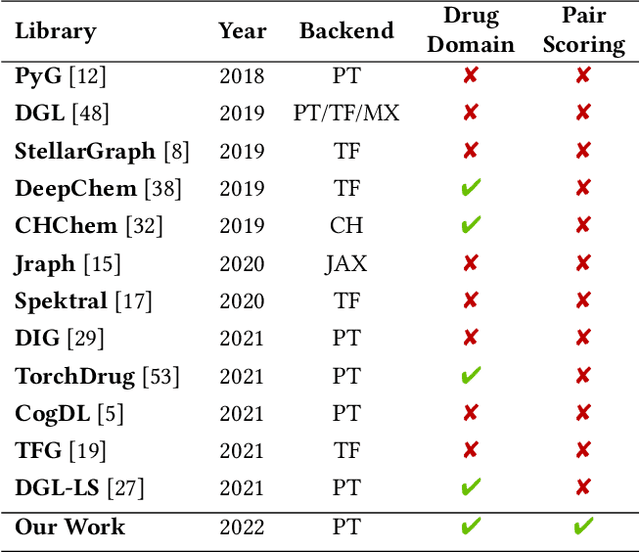
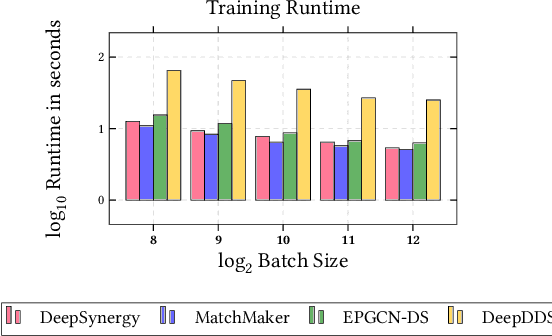
In this paper, we introduce ChemicalX, a PyTorch-based deep learning library designed for providing a range of state of the art models to solve the drug pair scoring task. The primary objective of the library is to make deep drug pair scoring models accessible to machine learning researchers and practitioners in a streamlined framework.The design of ChemicalX reuses existing high level model training utilities, geometric deep learning, and deep chemistry layers from the PyTorch ecosystem. Our system provides neural network layers, custom pair scoring architectures, data loaders, and batch iterators for end users. We showcase these features with example code snippets and case studies to highlight the characteristics of ChemicalX. A range of experiments on real world drug-drug interaction, polypharmacy side effect, and combination synergy prediction tasks demonstrate that the models available in ChemicalX are effective at solving the pair scoring task. Finally, we show that ChemicalX could be used to train and score machine learning models on large drug pair datasets with hundreds of thousands of compounds on commodity hardware.
Imbalanced Graph Classification via Graph-of-Graph Neural Networks
Dec 01, 2021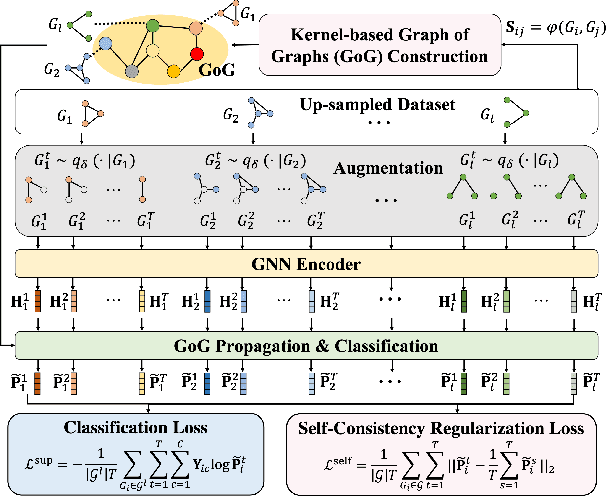
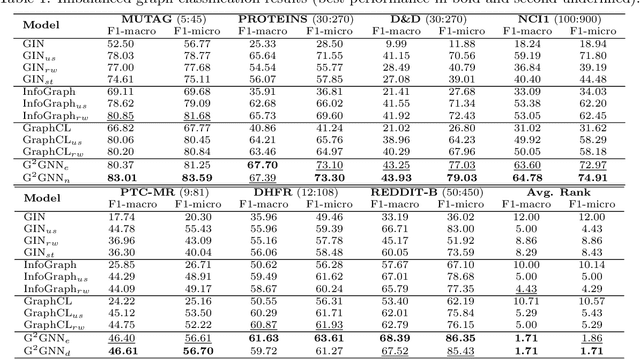
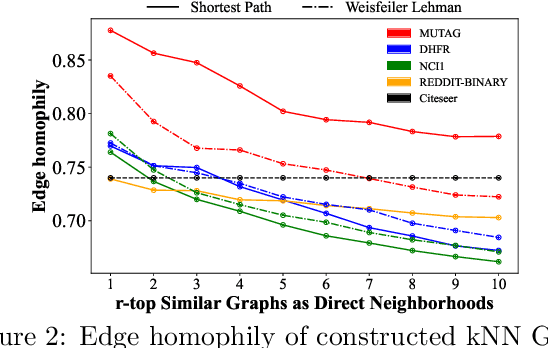
Graph Neural Networks (GNNs) have achieved unprecedented success in learning graph representations to identify categorical labels of graphs. However, most existing graph classification problems with GNNs follow a balanced data splitting protocol, which is misaligned with many real-world scenarios in which some classes have much fewer labels than others. Directly training GNNs under this imbalanced situation may lead to uninformative representations of graphs in minority classes, and compromise the overall performance of downstream classification, which signifies the importance of developing effective GNNs for handling imbalanced graph classification. Existing methods are either tailored for non-graph structured data or designed specifically for imbalance node classification while few focus on imbalance graph classification. To this end, we introduce a novel framework, Graph-of-Graph Neural Networks (G$^2$GNN), which alleviates the graph imbalance issue by deriving extra supervision globally from neighboring graphs and locally from graphs themselves. Globally, we construct a graph of graphs (GoG) based on kernel similarity and perform GoG propagation to aggregate neighboring graph representations, which are initially obtained by node-level propagation with pooling via a GNN encoder. Locally, we employ topological augmentation via masking nodes or dropping edges to improve the model generalizability in discerning topology of unseen testing graphs. Extensive graph classification experiments conducted on seven benchmark datasets demonstrate our proposed G$^2$GNN outperforms numerous baselines by roughly 5\% in both F1-macro and F1-micro scores. The implementation of G$^2$GNN is available at \href{https://github.com/YuWVandy/G2GNN}{https://github.com/YuWVandy/G2GNN}.