 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Correlated Equilibria in General-Sum Extensive-Form Games: Fixed-Parameter Algorithms, Hardness, and Two-Sided Column-Generation
Mar 14, 2022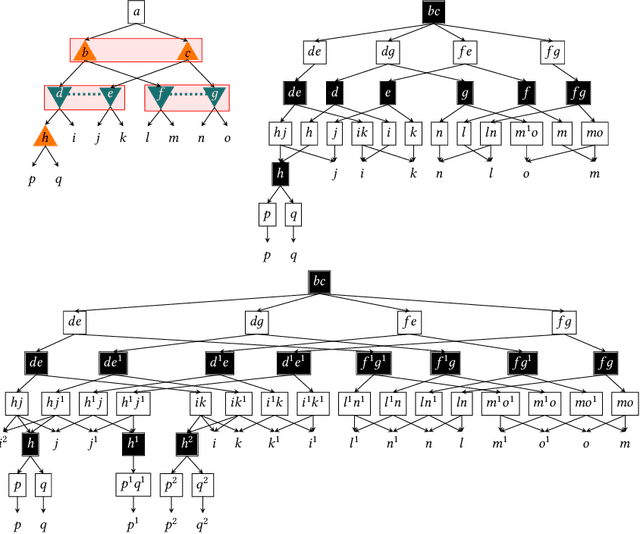
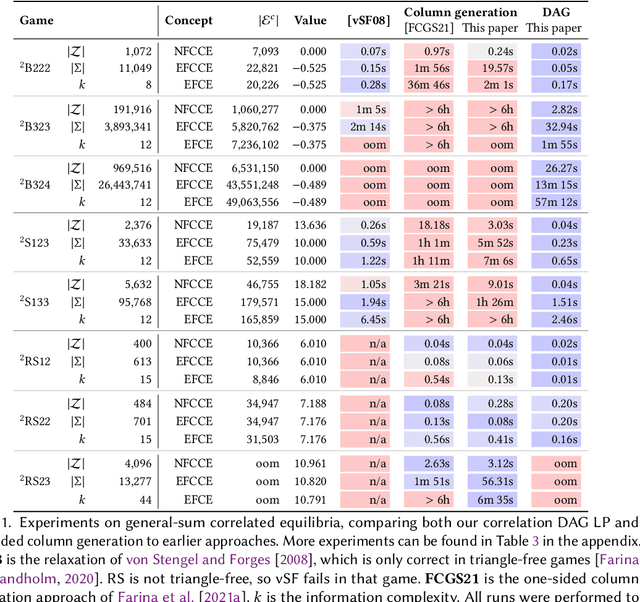
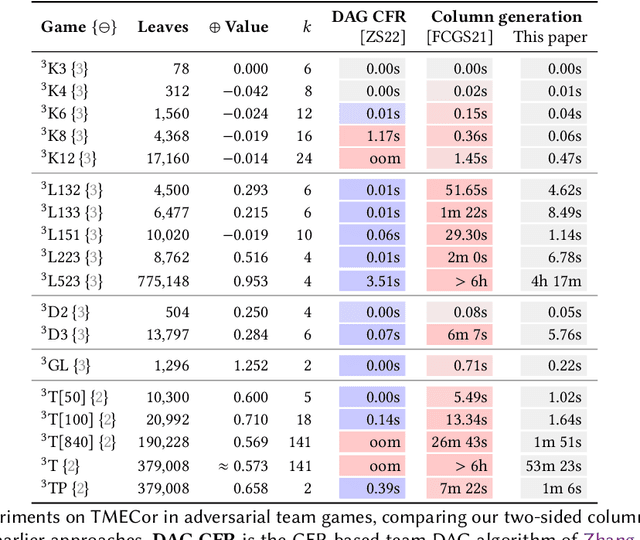
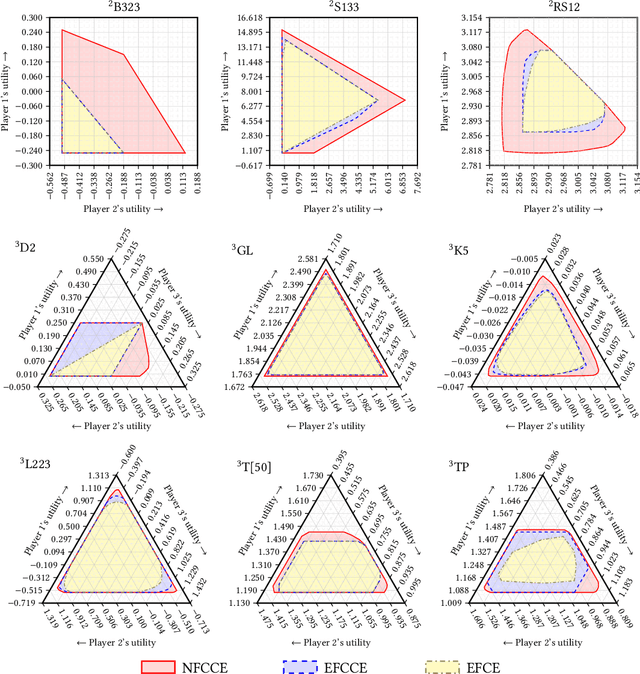
We study the problem of finding optimal correlated equilibria of various sorts: normal-form coarse correlated equilibrium (NFCCE), extensive-form coarse correlated equilibrium (EFCCE), and extensive-form correlated equilibrium (EFCE). This is NP-hard in the general case and has been studied in special cases, most notably triangle-free games, which include all two-player games with public chance moves. However, the general case is not well understood, and algorithms usually scale poorly. First, we introduce the correlation DAG, a representation of the space of correlated strategies whose size is dependent on the specific solution concept. It extends the team belief DAG of Zhang et al. to general-sum games. For each of the three solution concepts, its size depends exponentially only on a parameter related to the game's information structure. We also prove a fundamental complexity gap: while our size bounds for NFCCE are similar to those achieved in the case of team games by Zhang et al., this is impossible to achieve for the other two concepts under standard complexity assumptions. Second, we propose a two-sided column generation approach to compute optimal correlated strategies. Our algorithm improves upon the one-sided approach of Farina et al. by means of a new decomposition of correlated strategies which allows players to re-optimize their sequence-form strategies with respect to correlation plans which were previously added to the support. Our techniques outperform the prior state of the art for computing optimal general-sum correlated equilibria. For team games, the two-sided column generation approach vastly outperforms standard column generation approaches, making it the state of the art algorithm when the parameter is large. Along the way we also introduce two new benchmark games: a trick-taking game that emulates the endgame phase of the card game bridge, and a ride-sharing game.
Differentiable Economics for Randomized Affine Maximizer Auctions
Feb 06, 2022



A recent approach to automated mechanism design, differentiable economics, represents auctions by rich function approximators and optimizes their performance by gradient descent. The ideal auction architecture for differentiable economics would be perfectly strategyproof, support multiple bidders and items, and be rich enough to represent the optimal (i.e. revenue-maximizing) mechanism. So far, such an architecture does not exist. There are single-bidder approaches (MenuNet, RochetNet) which are always strategyproof and can represent optimal mechanisms. RegretNet is multi-bidder and can approximate any mechanism, but is only approximately strategyproof. We present an architecture that supports multiple bidders and is perfectly strategyproof, but cannot necessarily represent the optimal mechanism. This architecture is the classic affine maximizer auction (AMA), modified to offer lotteries. By using the gradient-based optimization tools of differentiable economics, we can now train lottery AMAs, competing with or outperforming prior approaches in revenue.
Anytime PSRO for Two-Player Zero-Sum Games
Jan 28, 2022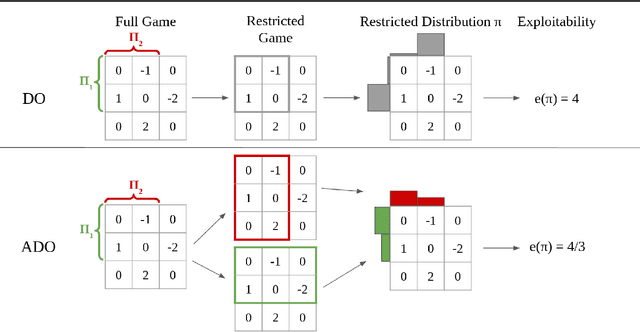

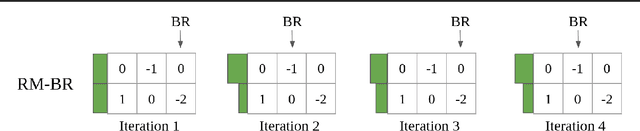

Policy space response oracles (PSRO) is a multi-agent reinforcement learning algorithm that has achieved state-of-the-art performance in very large two-player zero-sum games. PSRO is based on the tabular double oracle (DO) method, an algorithm that is guaranteed to converge to a Nash equilibrium, but may increase exploitability from one iteration to the next. We propose anytime double oracle (ADO), a tabular double oracle algorithm for 2-player zero-sum games that is guaranteed to converge to a Nash equilibrium while decreasing exploitability from one iteration to the next. Unlike DO, in which the restricted distribution is based on the restricted game formed by each player's strategy sets, ADO finds the restricted distribution for each player that minimizes its exploitability against any policy in the full, unrestricted game. We also propose a method of finding this restricted distribution via a no-regret algorithm updated against best responses, called RM-BR DO. Finally, we propose anytime PSRO (APSRO), a version of ADO that calculates best responses via reinforcement learning. In experiments on Leduc poker and random normal form games, we show that our methods achieve far lower exploitability than DO and PSRO and decrease exploitability monotonically.
Improved Learning Bounds for Branch-and-Cut
Nov 18, 2021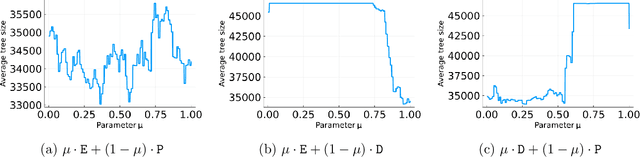
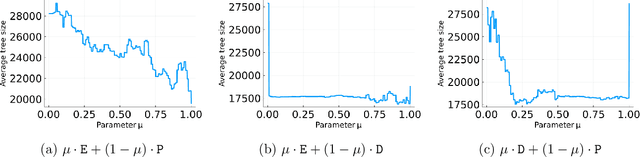
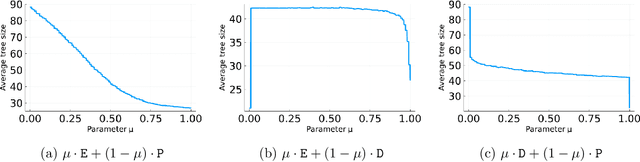
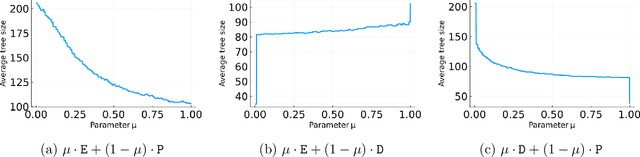
Branch-and-cut is the most widely used algorithm for solving integer programs, employed by commercial solvers like CPLEX and Gurobi. Branch-and-cut has a wide variety of tunable parameters that have a huge impact on the size of the search tree that it builds, but are challenging to tune by hand. An increasingly popular approach is to use machine learning to tune these parameters: using a training set of integer programs from the application domain at hand, the goal is to find a configuration with strong predicted performance on future, unseen integer programs from the same domain. If the training set is too small, a configuration may have good performance over the training set but poor performance on future integer programs. In this paper, we prove sample complexity guarantees for this procedure, which bound how large the training set should be to ensure that for any configuration, its average performance over the training set is close to its expected future performance. Our guarantees apply to parameters that control the most important aspects of branch-and-cut: node selection, branching constraint selection, and cutting plane selection, and are sharper and more general than those found in prior research.
Near-Optimal No-Regret Learning for Correlated Equilibria in Multi-Player General-Sum Games
Nov 11, 2021

Recently, Daskalakis, Fishelson, and Golowich (DFG) (NeurIPS`21) showed that if all agents in a multi-player general-sum normal-form game employ Optimistic Multiplicative Weights Update (OMWU), the external regret of every player is $O(\textrm{polylog}(T))$ after $T$ repetitions of the game. We extend their result from external regret to internal regret and swap regret, thereby establishing uncoupled learning dynamics that converge to an approximate correlated equilibrium at the rate of $\tilde{O}(T^{-1})$. This substantially improves over the prior best rate of convergence for correlated equilibria of $O(T^{-3/4})$ due to Chen and Peng (NeurIPS`20), and it is optimal -- within the no-regret framework -- up to polylogarithmic factors in $T$. To obtain these results, we develop new techniques for establishing higher-order smoothness for learning dynamics involving fixed point operations. Specifically, we establish that the no-internal-regret learning dynamics of Stoltz and Lugosi (Mach Learn`05) are equivalently simulated by no-external-regret dynamics on a combinatorial space. This allows us to trade the computation of the stationary distribution on a polynomial-sized Markov chain for a (much more well-behaved) linear transformation on an exponential-sized set, enabling us to leverage similar techniques as DGF to near-optimally bound the internal regret. Moreover, we establish an $O(\textrm{polylog}(T))$ no-swap-regret bound for the classic algorithm of Blum and Mansour (BM) (JMLR`07). We do so by introducing a technique based on the Cauchy Integral Formula that circumvents the more limited combinatorial arguments of DFG. In addition to shedding clarity on the near-optimal regret guarantees of BM, our arguments provide insights into the various ways in which the techniques by DFG can be extended and leveraged in the analysis of more involved learning algorithms.
Sample Complexity of Tree Search Configuration: Cutting Planes and Beyond
Jun 08, 2021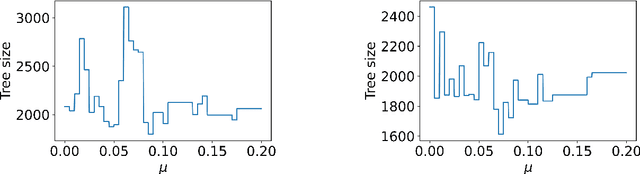
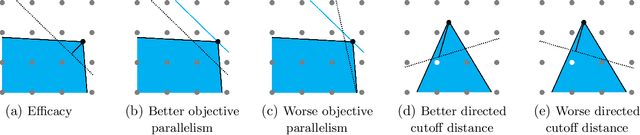
Cutting-plane methods have enabled remarkable successes in integer programming over the last few decades. State-of-the-art solvers integrate a myriad of cutting-plane techniques to speed up the underlying tree-search algorithm used to find optimal solutions. In this paper we prove the first guarantees for learning high-performing cut-selection policies tailored to the instance distribution at hand using samples. We first bound the sample complexity of learning cutting planes from the canonical family of Chv\'atal-Gomory cuts. Our bounds handle any number of waves of any number of cuts and are fine tuned to the magnitudes of the constraint coefficients. Next, we prove sample complexity bounds for more sophisticated cut selection policies that use a combination of scoring rules to choose from a family of cuts. Finally, beyond the realm of cutting planes for integer programming, we develop a general abstraction of tree search that captures key components such as node selection and variable selection. For this abstraction, we bound the sample complexity of learning a good policy for building the search tree.
Better Regularization for Sequential Decision Spaces: Fast Convergence Rates for Nash, Correlated, and Team Equilibria
May 27, 2021
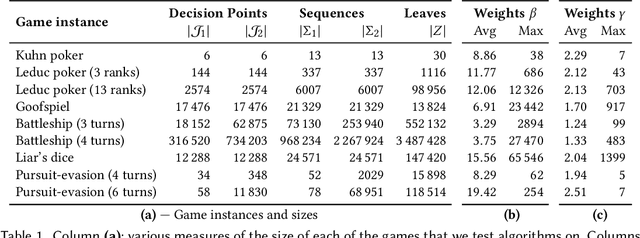
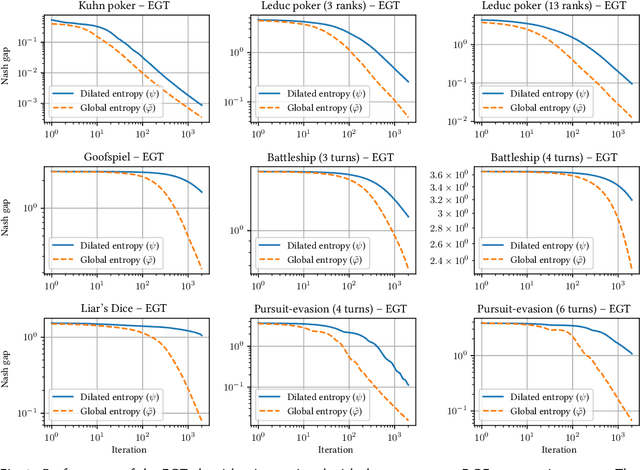
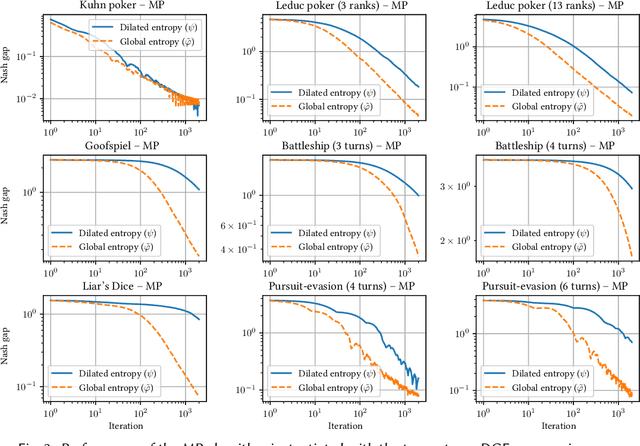
We study the application of iterative first-order methods to the problem of computing equilibria of large-scale two-player extensive-form games. First-order methods must typically be instantiated with a regularizer that serves as a distance-generating function for the decision sets of the players. For the case of two-player zero-sum games, the state-of-the-art theoretical convergence rate for Nash equilibrium is achieved by using the dilated entropy function. In this paper, we introduce a new entropy-based distance-generating function for two-player zero-sum games, and show that this function achieves significantly better strong convexity properties than the dilated entropy, while maintaining the same easily-implemented closed-form proximal mapping. Extensive numerical simulations show that these superior theoretical properties translate into better numerical performance as well. We then generalize our new entropy distance function, as well as general dilated distance functions, to the scaled extension operator. The scaled extension operator is a way to recursively construct convex sets, which generalizes the decision polytope of extensive-form games, as well as the convex polytopes corresponding to correlated and team equilibria. By instantiating first-order methods with our regularizers, we develop the first accelerated first-order methods for computing correlated equilibra and ex-ante coordinated team equilibria. Our methods have a guaranteed $1/T$ rate of convergence, along with linear-time proximal updates.
Bandit Linear Optimization for Sequential Decision Making and Extensive-Form Games
Mar 08, 2021
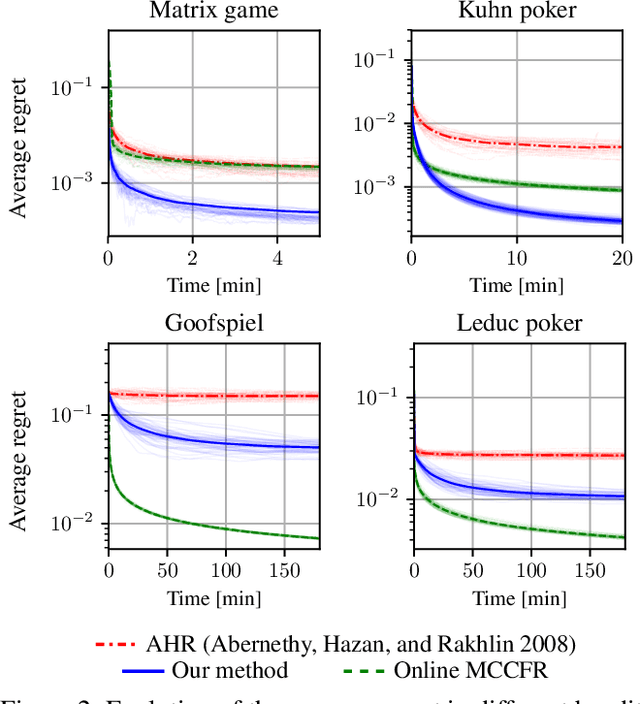
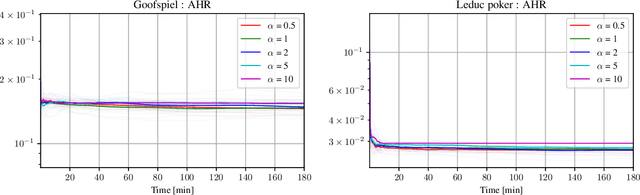
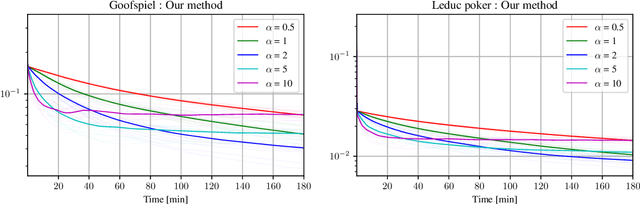
Tree-form sequential decision making (TFSDM) extends classical one-shot decision making by modeling tree-form interactions between an agent and a potentially adversarial environment. It captures the online decision-making problems that each player faces in an extensive-form game, as well as Markov decision processes and partially-observable Markov decision processes where the agent conditions on observed history. Over the past decade, there has been considerable effort into designing online optimization methods for TFSDM. Virtually all of that work has been in the full-feedback setting, where the agent has access to counterfactuals, that is, information on what would have happened had the agent chosen a different action at any decision node. Little is known about the bandit setting, where that assumption is reversed (no counterfactual information is available), despite this latter setting being well understood for almost 20 years in one-shot decision making. In this paper, we give the first algorithm for the bandit linear optimization problem for TFSDM that offers both (i) linear-time iterations (in the size of the decision tree) and (ii) $O(\sqrt{T})$ cumulative regret in expectation compared to any fixed strategy, at all times $T$. This is made possible by new results that we derive, which may have independent uses as well: 1) geometry of the dilated entropy regularizer, 2) autocorrelation matrix of the natural sampling scheme for sequence-form strategies, 3) construction of an unbiased estimator for linear losses for sequence-form strategies, and 4) a refined regret analysis for mirror descent when using the dilated entropy regularizer.
Model-Free Online Learning in Unknown Sequential Decision Making Problems and Games
Mar 08, 2021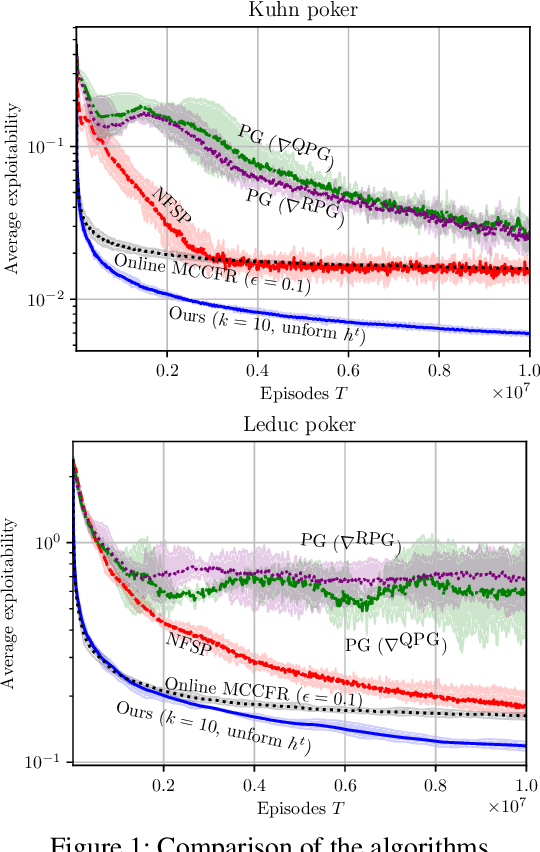

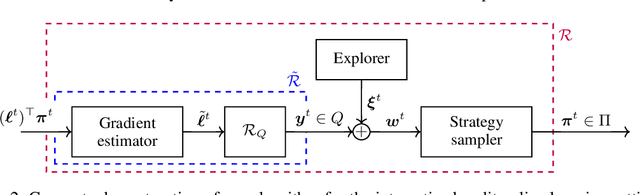
Regret minimization has proved to be a versatile tool for tree-form sequential decision making and extensive-form games. In large two-player zero-sum imperfect-information games, modern extensions of counterfactual regret minimization (CFR) are currently the practical state of the art for computing a Nash equilibrium. Most regret-minimization algorithms for tree-form sequential decision making, including CFR, require (i) an exact model of the player's decision nodes, observation nodes, and how they are linked, and (ii) full knowledge, at all times t, about the payoffs -- even in parts of the decision space that are not encountered at time t. Recently, there has been growing interest towards relaxing some of those restrictions and making regret minimization applicable to settings for which reinforcement learning methods have traditionally been used -- for example, those in which only black-box access to the environment is available. We give the first, to our knowledge, regret-minimization algorithm that guarantees sublinear regret with high probability even when requirement (i) -- and thus also (ii) -- is dropped. We formalize an online learning setting in which the strategy space is not known to the agent and gets revealed incrementally whenever the agent encounters new decision points. We give an efficient algorithm that achieves $O(T^{3/4})$ regret with high probability for that setting, even when the agent faces an adversarial environment. Our experiments show it significantly outperforms the prior algorithms for the problem, which do not have such guarantees. It can be used in any application for which regret minimization is useful: approximating Nash equilibrium or quantal response equilibrium, approximating coarse correlated equilibrium in multi-player games, learning a best response, learning safe opponent exploitation, and online play against an unknown opponent/environment.
Generalization in portfolio-based algorithm selection
Dec 24, 2020
Portfolio-based algorithm selection has seen tremendous practical success over the past two decades. This algorithm configuration procedure works by first selecting a portfolio of diverse algorithm parameter settings, and then, on a given problem instance, using an algorithm selector to choose a parameter setting from the portfolio with strong predicted performance. Oftentimes, both the portfolio and the algorithm selector are chosen using a training set of typical problem instances from the application domain at hand. In this paper, we provide the first provable guarantees for portfolio-based algorithm selection. We analyze how large the training set should be to ensure that the resulting algorithm selector's average performance over the training set is close to its future (expected) performance. This involves analyzing three key reasons why these two quantities may diverge: 1) the learning-theoretic complexity of the algorithm selector, 2) the size of the portfolio, and 3) the learning-theoretic complexity of the algorithm's performance as a function of its parameters. We introduce an end-to-end learning-theoretic analysis of the portfolio construction and algorithm selection together. We prove that if the portfolio is large, overfitting is inevitable, even with an extremely simple algorithm selector. With experiments, we illustrate a tradeoff exposed by our theoretical analysis: as we increase the portfolio size, we can hope to include a well-suited parameter setting for every possible problem instance, but it becomes impossible to avoid overfitting.