 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020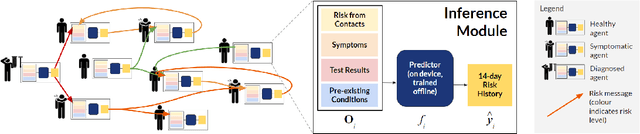
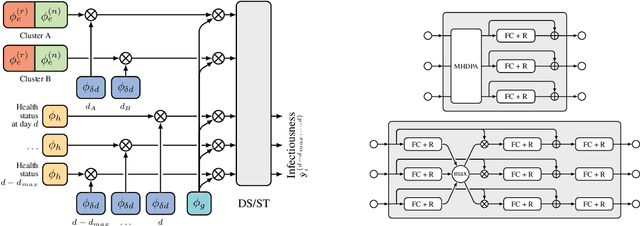
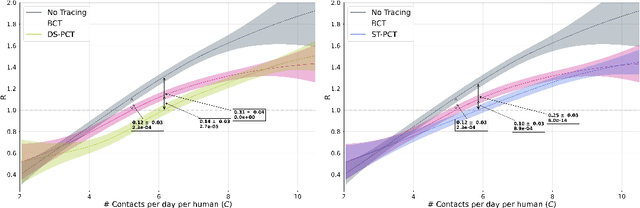
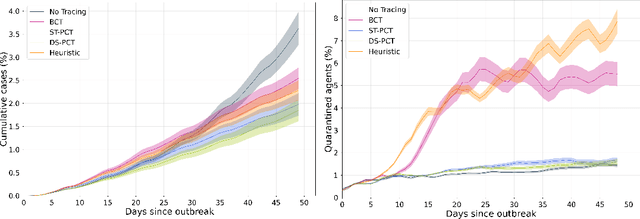
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
COVI White Paper
May 18, 2020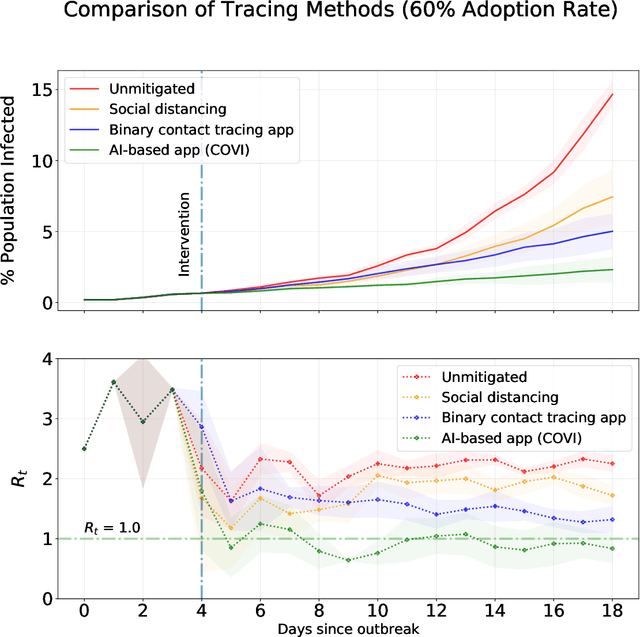
The SARS-CoV-2 (Covid-19) pandemic has caused significant strain on public health institutions around the world. Contact tracing is an essential tool to change the course of the Covid-19 pandemic. Manual contact tracing of Covid-19 cases has significant challenges that limit the ability of public health authorities to minimize community infections. Personalized peer-to-peer contact tracing through the use of mobile apps has the potential to shift the paradigm. Some countries have deployed centralized tracking systems, but more privacy-protecting decentralized systems offer much of the same benefit without concentrating data in the hands of a state authority or for-profit corporations. Machine learning methods can circumvent some of the limitations of standard digital tracing by incorporating many clues and their uncertainty into a more graded and precise estimation of infection risk. The estimated risk can provide early risk awareness, personalized recommendations and relevant information to the user. Finally, non-identifying risk data can inform epidemiological models trained jointly with the machine learning predictor. These models can provide statistical evidence for the importance of factors involved in disease transmission. They can also be used to monitor, evaluate and optimize health policy and (de)confinement scenarios according to medical and economic productivity indicators. However, such a strategy based on mobile apps and machine learning should proactively mitigate potential ethical and privacy risks, which could have substantial impacts on society (not only impacts on health but also impacts such as stigmatization and abuse of personal data). Here, we present an overview of the rationale, design, ethical considerations and privacy strategy of `COVI,' a Covid-19 public peer-to-peer contact tracing and risk awareness mobile application developed in Canada.
Curriculum in Gradient-Based Meta-Reinforcement Learning
Feb 19, 2020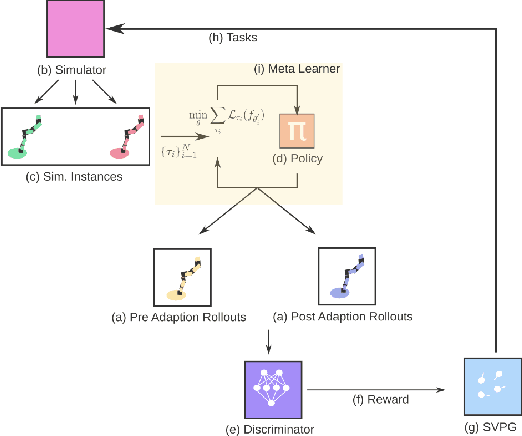
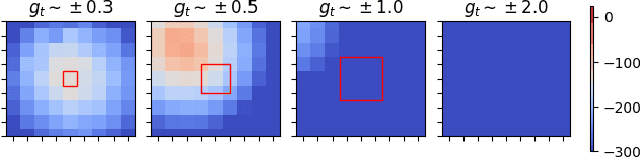
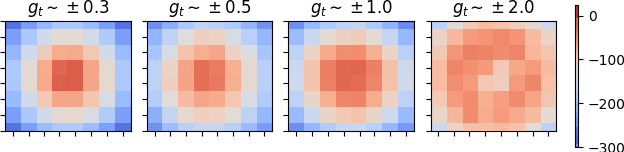
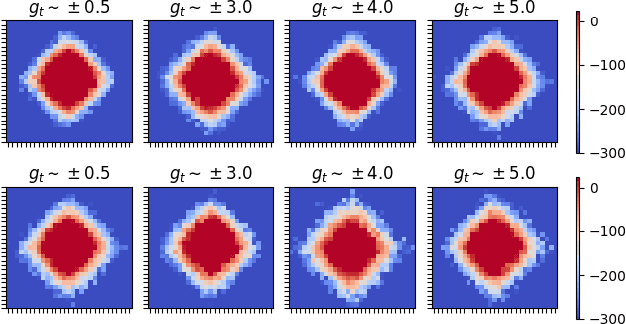
Gradient-based meta-learners such as Model-Agnostic Meta-Learning (MAML) have shown strong few-shot performance in supervised and reinforcement learning settings. However, specifically in the case of meta-reinforcement learning (meta-RL), we can show that gradient-based meta-learners are sensitive to task distributions. With the wrong curriculum, agents suffer the effects of meta-overfitting, shallow adaptation, and adaptation instability. In this work, we begin by highlighting intriguing failure cases of gradient-based meta-RL and show that task distributions can wildly affect algorithmic outputs, stability, and performance. To address this problem, we leverage insights from recent literature on domain randomization and propose meta Active Domain Randomization (meta-ADR), which learns a curriculum of tasks for gradient-based meta-RL in a similar as ADR does for sim2real transfer. We show that this approach induces more stable policies on a variety of simulated locomotion and navigation tasks. We assess in- and out-of-distribution generalization and find that the learned task distributions, even in an unstructured task space, greatly improve the adaptation performance of MAML. Finally, we motivate the need for better benchmarking in meta-RL that prioritizes \textit{generalization} over single-task adaption performance.
The TCGA Meta-Dataset Clinical Benchmark
Oct 18, 2019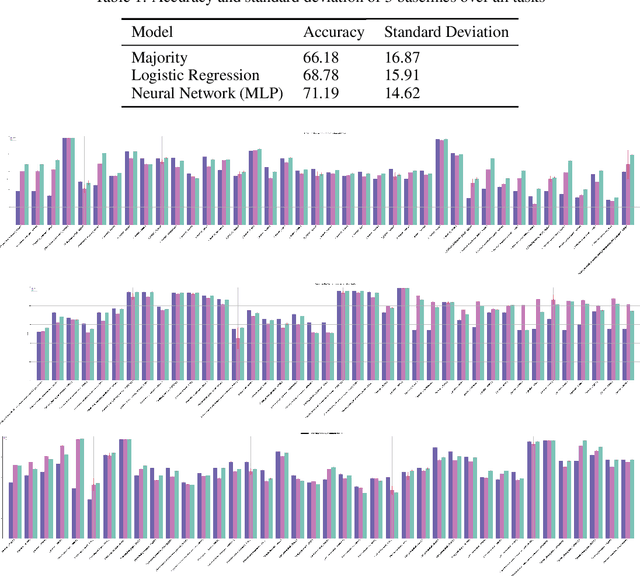
Machine learning is bringing a paradigm shift to healthcare by changing the process of disease diagnosis and prognosis in clinics and hospitals. This development equips doctors and medical staff with tools to evaluate their hypotheses and hence make more precise decisions. Although most current research in the literature seeks to develop techniques and methods for predicting one particular clinical outcome, this approach is far from the reality of clinical decision making in which you have to consider several factors simultaneously. In addition, it is difficult to follow the recent progress concretely as there is a lack of consistency in benchmark datasets and task definitions in the field of Genomics. To address the aforementioned issues, we provide a clinical Meta-Dataset derived from the publicly available data hub called The Cancer Genome Atlas Program (TCGA) that contains 174 tasks. We believe those tasks could be good proxy tasks to develop methods which can work on a few samples of gene expression data. Also, learning to predict multiple clinical variables using gene-expression data is an important task due to the variety of phenotypes in clinical problems and lack of samples for some of the rare variables. The defined tasks cover a wide range of clinical problems including predicting tumor tissue site, white cell count, histological type, family history of cancer, gender, and many others which we explain later in the paper. Each task represents an independent dataset. We use regression and neural network baselines for all the tasks using only 150 samples and compare their performance.
Torchmeta: A Meta-Learning library for PyTorch
Sep 14, 2019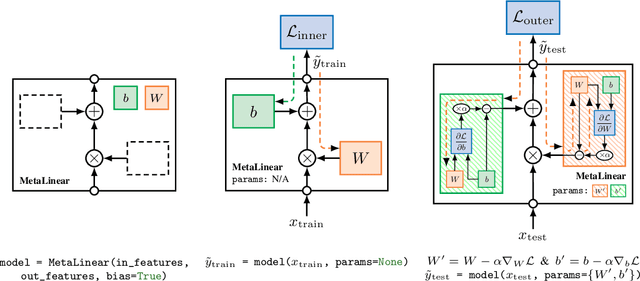
The constant introduction of standardized benchmarks in the literature has helped accelerating the recent advances in meta-learning research. They offer a way to get a fair comparison between different algorithms, and the wide range of datasets available allows full control over the complexity of this evaluation. However, for a large majority of code available online, the data pipeline is often specific to one dataset, and testing on another dataset requires significant rework. We introduce Torchmeta, a library built on top of PyTorch that enables seamless and consistent evaluation of meta-learning algorithms on multiple datasets, by providing data-loaders for most of the standard benchmarks in few-shot classification and regression, with a new meta-dataset abstraction. It also features some extensions for PyTorch to simplify the development of models compatible with meta-learning algorithms. The code is available here: https://github.com/tristandeleu/pytorch-meta
Learning Powerful Policies by Using Consistent Dynamics Model
Jun 11, 2019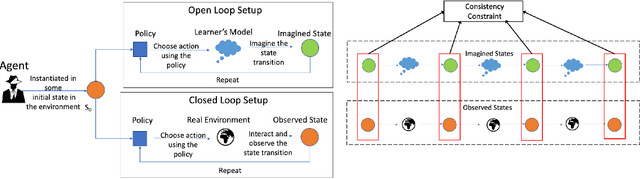
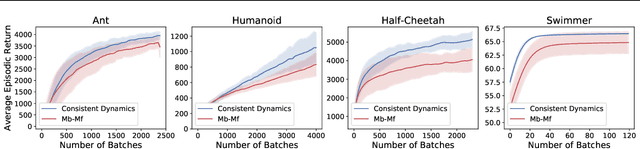
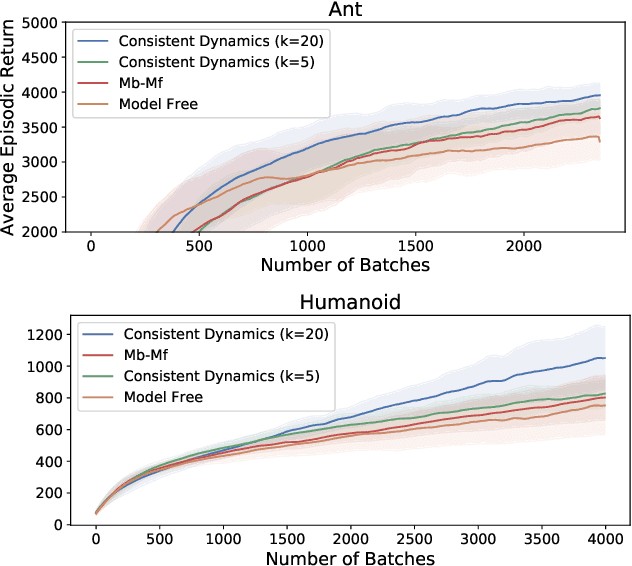
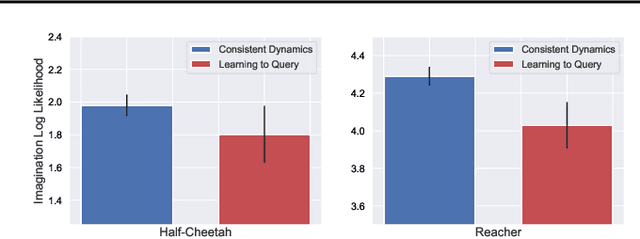
Model-based Reinforcement Learning approaches have the promise of being sample efficient. Much of the progress in learning dynamics models in RL has been made by learning models via supervised learning. But traditional model-based approaches lead to `compounding errors' when the model is unrolled step by step. Essentially, the state transitions that the learner predicts (by unrolling the model for multiple steps) and the state transitions that the learner experiences (by acting in the environment) may not be consistent. There is enough evidence that humans build a model of the environment, not only by observing the environment but also by interacting with the environment. Interaction with the environment allows humans to carry out experiments: taking actions that help uncover true causal relationships which can be used for building better dynamics models. Analogously, we would expect such interactions to be helpful for a learning agent while learning to model the environment dynamics. In this paper, we build upon this intuition by using an auxiliary cost function to ensure consistency between what the agent observes (by acting in the real world) and what it imagines (by acting in the `learned' world). We consider several tasks - Mujoco based control tasks and Atari games - and show that the proposed approach helps to train powerful policies and better dynamics models.
Gradient-Based Neural DAG Learning
Jun 05, 2019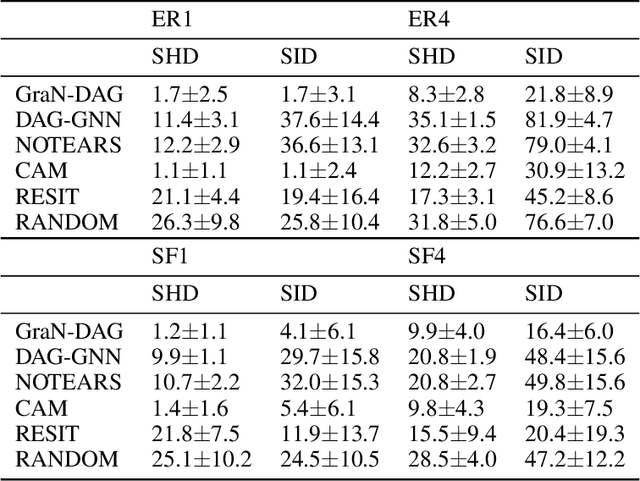
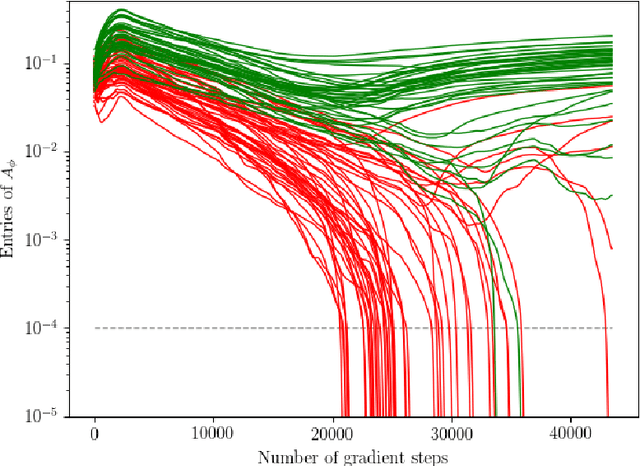
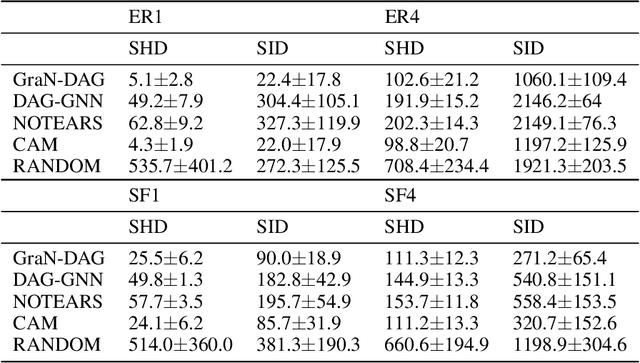
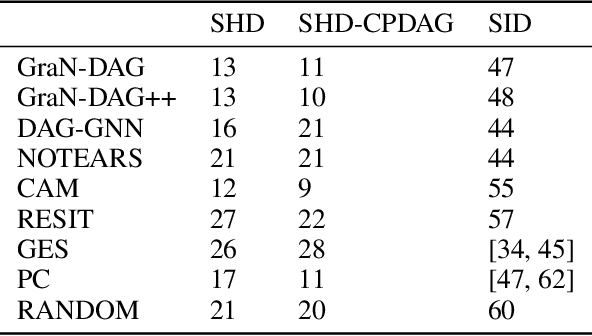
We propose a novel score-based approach to learning a directed acyclic graph (DAG) from observational data. We adapt a recently proposed continuous constrained optimization formulation to allow for nonlinear relationships between variables using neural networks. This extension allows to model complex interactions while being more global in its search compared to other greedy approaches. In addition to comparing our method to existing continuous optimization methods, we provide missing empirical comparisons to nonlinear greedy search methods. On both synthetic and real-world data sets, this new method outperforms current continuous methods on most tasks while being competitive with existing greedy search methods on important metrics for causal inference.
A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms
Feb 04, 2019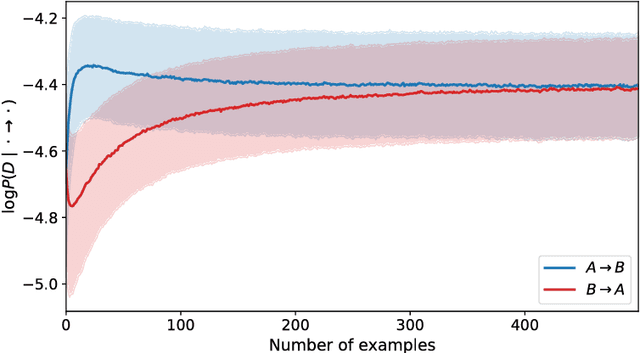
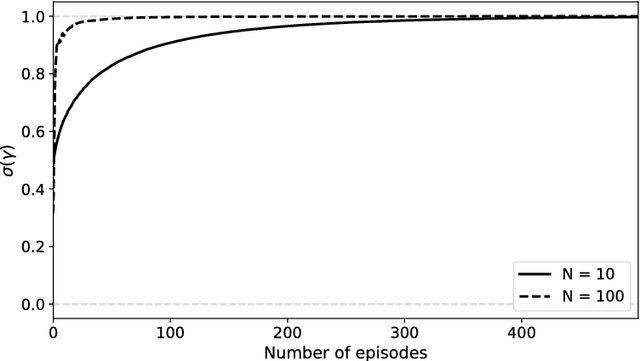
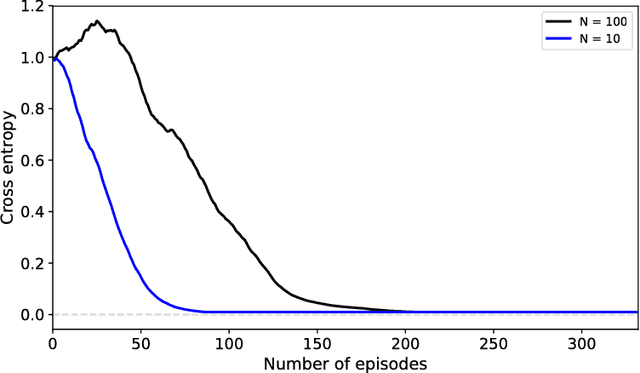

We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.
The effects of negative adaptation in Model-Agnostic Meta-Learning
Dec 05, 2018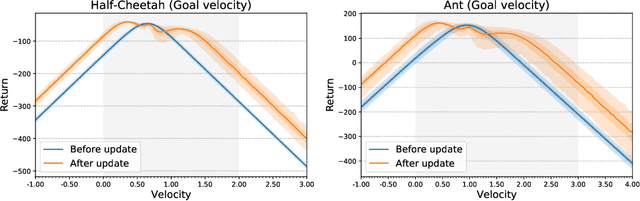
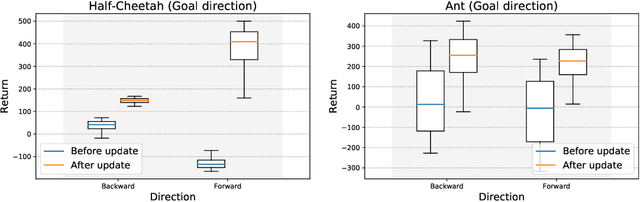
The capacity of meta-learning algorithms to quickly adapt to a variety of tasks, including ones they did not experience during meta-training, has been a key factor in the recent success of these methods on few-shot learning problems. This particular advantage of using meta-learning over standard supervised or reinforcement learning is only well founded under the assumption that the adaptation phase does improve the performance of our model on the task of interest. However, in the classical framework of meta-learning, this constraint is only mildly enforced, if not at all, and we only see an improvement on average over a distribution of tasks. In this paper, we show that the adaptation in an algorithm like MAML can significantly decrease the performance of an agent in a meta-reinforcement learning setting, even on a range of meta-training tasks.
Learning Operations on a Stack with Neural Turing Machines
Dec 02, 2016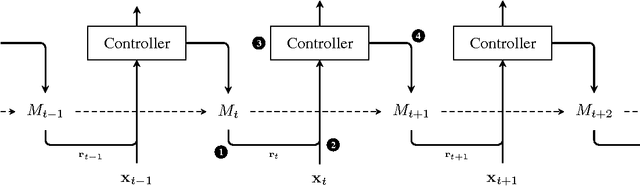
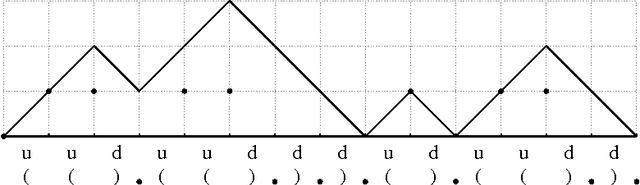
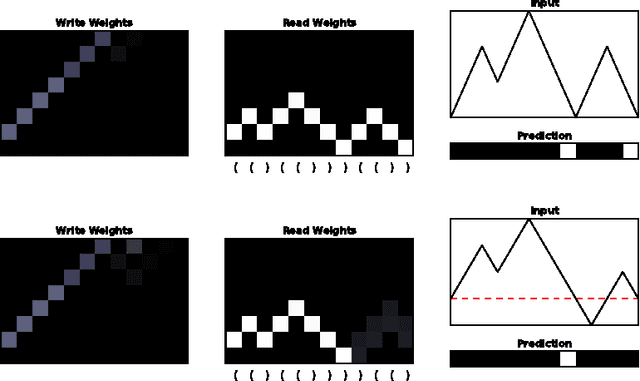
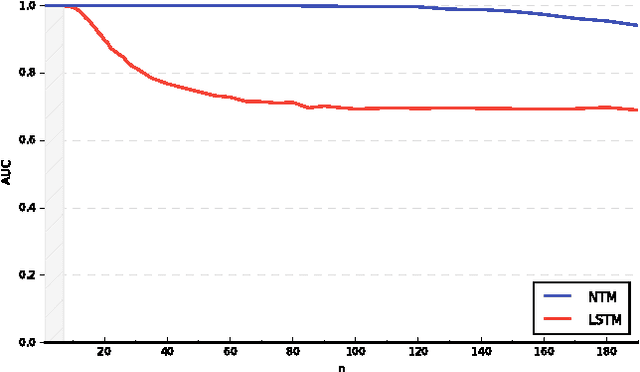
Multiple extensions of Recurrent Neural Networks (RNNs) have been proposed recently to address the difficulty of storing information over long time periods. In this paper, we experiment with the capacity of Neural Turing Machines (NTMs) to deal with these long-term dependencies on well-balanced strings of parentheses. We show that not only does the NTM emulate a stack with its heads and learn an algorithm to recognize such words, but it is also capable of strongly generalizing to much longer sequences.