 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalDec-Bench: Benchmarking Hallucination Detector in Image Captioning
Mar 16, 2026Hallucination detection in captions (HalDec) assesses a vision-language model's ability to correctly align image content with text by identifying errors in captions that misrepresent the image. Beyond evaluation, effective hallucination detection is also essential for curating high-quality image-caption pairs used to train VLMs. However, the generalizability of VLMs as hallucination detectors across different captioning models and hallucination types remains unclear due to the lack of a comprehensive benchmark. In this work, we introduce HalDec-Bench, a benchmark designed to evaluate hallucination detectors in a principled and interpretable manner. HalDec-Bench contains captions generated by diverse VLMs together with human annotations indicating the presence of hallucinations, detailed hallucination-type categories, and segment-level labels. The benchmark provides tasks with a wide range of difficulty levels and reveals performance differences across models that are not visible in existing multimodal reasoning or alignment benchmarks. Our analysis further uncovers two key findings. First, detectors tend to recognize sentences appearing at the beginning of a response as correct, regardless of their actual correctness. Second, our experiments suggest that dataset noise can be substantially reduced by using strong VLMs as filters while employing recent VLMs as caption generators. Our project page is available at https://dahlian00.github.io/HalDec-Bench-Page/.
Am I More Pointwise or Pairwise? Revealing Position Bias in Rubric-Based LLM-as-a-Judge
Feb 02, 2026Large language models (LLMs) are now widely used to evaluate the quality of text, a field commonly referred to as LLM-as-a-judge. While prior works mainly focus on point-wise and pair-wise evaluation paradigms. Rubric-based evaluation, where LLMs select a score from multiple rubrics, has received less analysis. In this work, we show that rubric-based evaluation implicitly resembles a multi-choice setting and therefore has position bias: LLMs prefer score options appearing at specific positions in the rubric list. Through controlled experiments across multiple models and datasets, we demonstrate consistent position bias. To mitigate this bias, we propose a balanced permutation strategy that evenly distributes each score option across positions. We show that aggregating scores across balanced permutations not only reveals latent position bias, but also improves correlation between the LLM-as-a-Judge and human. Our results suggest that rubric-based LLM-as-a-Judge is not inherently point-wise and that simple permutation-based calibration can substantially improve its reliability.
WarrantScore: Modeling Warrants between Claims and Evidence for Substantiation Evaluation in Peer Reviews
Jan 24, 2026The scientific peer-review process is facing a shortage of human resources due to the rapid growth in the number of submitted papers. The use of language models to reduce the human cost of peer review has been actively explored as a potential solution to this challenge. A method has been proposed to evaluate the level of substantiation in scientific reviews in a manner that is interpretable by humans. This method extracts the core components of an argument, claims and evidence, and assesses the level of substantiation based on the proportion of claims supported by evidence. The level of substantiation refers to the extent to which claims are based on objective facts. However, when assessing the level of substantiation, simply detecting the presence or absence of supporting evidence for a claim is insufficient; it is also necessary to accurately assess the logical inference between a claim and its evidence. We propose a new evaluation metric for scientific review comments that assesses the logical inference between claims and evidence. Experimental results show that the proposed method achieves a higher correlation with human scores than conventional methods, indicating its potential to better support the efficiency of the peer-review process.
Evaluating the Capability of Video Question Generation for Expert Knowledge Elicitation
Dec 17, 2025Skilled human interviewers can extract valuable information from experts. This raises a fundamental question: what makes some questions more effective than others? To address this, a quantitative evaluation of question-generation models is essential. Video question generation (VQG) is a topic for video question answering (VideoQA), where questions are generated for given answers. Their evaluation typically focuses on the ability to answer questions, rather than the quality of generated questions. In contrast, we focus on the question quality in eliciting unseen knowledge from human experts. For a continuous improvement of VQG models, we propose a protocol that evaluates the ability by simulating question-answering communication with experts using a question-to-answer retrieval. We obtain the retriever by constructing a novel dataset, EgoExoAsk, which comprises 27,666 QA pairs generated from Ego-Exo4D's expert commentary annotation. The EgoExoAsk training set is used to obtain the retriever, and the benchmark is constructed on the validation set with Ego-Exo4D video segments. Experimental results demonstrate our metric reasonably aligns with question generation settings: models accessing richer context are evaluated better, supporting that our protocol works as intended. The EgoExoAsk dataset is available in https://github.com/omron-sinicx/VQG4ExpertKnowledge .
Assessing the Capabilities of LLMs in Humor:A Multi-dimensional Analysis of Oogiri Generation and Evaluation
Nov 12, 2025



Computational humor is a frontier for creating advanced and engaging natural language processing (NLP) applications, such as sophisticated dialogue systems. While previous studies have benchmarked the humor capabilities of Large Language Models (LLMs), they have often relied on single-dimensional evaluations, such as judging whether something is simply ``funny.'' This paper argues that a multifaceted understanding of humor is necessary and addresses this gap by systematically evaluating LLMs through the lens of Oogiri, a form of Japanese improvisational comedy games. To achieve this, we expanded upon existing Oogiri datasets with data from new sources and then augmented the collection with Oogiri responses generated by LLMs. We then manually annotated this expanded collection with 5-point absolute ratings across six dimensions: Novelty, Clarity, Relevance, Intelligence, Empathy, and Overall Funniness. Using this dataset, we assessed the capabilities of state-of-the-art LLMs on two core tasks: their ability to generate creative Oogiri responses and their ability to evaluate the funniness of responses using a six-dimensional evaluation. Our results show that while LLMs can generate responses at a level between low- and mid-tier human performance, they exhibit a notable lack of Empathy. This deficit in Empathy helps explain their failure to replicate human humor assessment. Correlation analyses of human and model evaluation data further reveal a fundamental divergence in evaluation criteria: LLMs prioritize Novelty, whereas humans prioritize Empathy. We release our annotated corpus to the community to pave the way for the development of more emotionally intelligent and sophisticated conversational agents.
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images
Dec 23, 2024



Building a large-scale figure QA dataset requires a considerable amount of work, from gathering and selecting figures to extracting attributes like text, numbers, and colors, and generating QAs. Although recent developments in LLMs have led to efforts to synthesize figures, most of these focus primarily on QA generation. Additionally, creating figures directly using LLMs often encounters issues such as code errors, similar-looking figures, and repetitive content in figures. To address this issue, we present SBSFigures (Stage-by-Stage Synthetic Figures), a dataset for pre-training figure QA. Our proposed pipeline enables the creation of chart figures with complete annotations of the visualized data and dense QA annotations without any manual annotation process. Our stage-by-stage pipeline makes it possible to create diverse topic and appearance figures efficiently while minimizing code errors. Our SBSFigures demonstrate a strong pre-training effect, making it possible to achieve efficient training with a limited amount of real-world chart data starting from our pre-trained weights.
Pruning Multilingual Large Language Models for Multilingual Inference
Sep 25, 2024Multilingual large language models (MLLMs), trained on multilingual balanced data, demonstrate better zero-shot learning performance in non-English languages compared to large language models trained on English-dominant data. However, the disparity in performance between English and non-English languages remains a challenge yet to be fully addressed. A distinctive characteristic of MLLMs is their high-quality translation capabilities, indicating an acquired proficiency in aligning between languages. This study explores how to enhance the zero-shot performance of MLLMs in non-English languages by leveraging their alignment capability between English and non-English languages. To achieve this, we first analyze the behavior of MLLMs when performing translation and reveal that there are large magnitude features that play a critical role in the translation process. Inspired by these findings, we retain the weights associated with operations involving the large magnitude features and prune other weights to force MLLMs to rely on these features for tasks beyond translation. We empirically demonstrate that this pruning strategy can enhance the MLLMs' performance in non-English language.
COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark
Aug 05, 2024Procedural video understanding is gaining attention in the vision and language community. Deep learning-based video analysis requires extensive data. Consequently, existing works often use web videos as training resources, making it challenging to query instructional contents from raw video observations. To address this issue, we propose a new dataset, COM Kitchens. The dataset consists of unedited overhead-view videos captured by smartphones, in which participants performed food preparation based on given recipes. Fixed-viewpoint video datasets often lack environmental diversity due to high camera setup costs. We used modern wide-angle smartphone lenses to cover cooking counters from sink to cooktop in an overhead view, capturing activity without in-person assistance. With this setup, we collected a diverse dataset by distributing smartphones to participants. With this dataset, we propose the novel video-to-text retrieval task Online Recipe Retrieval (OnRR) and new video captioning domain Dense Video Captioning on unedited Overhead-View videos (DVC-OV). Our experiments verified the capabilities and limitations of current web-video-based SOTA methods in handling these tasks.
Construction of a Quality Estimation Dataset for Automatic Evaluation of Japanese Grammatical Error Correction
Jan 20, 2022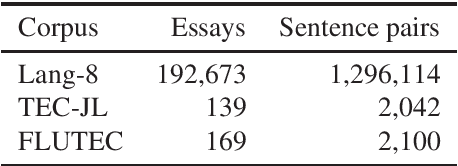
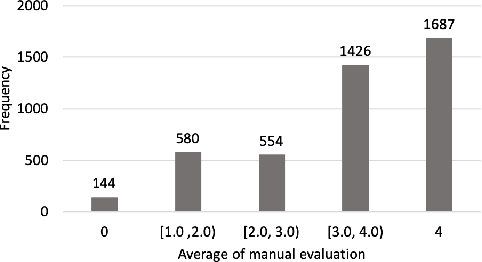

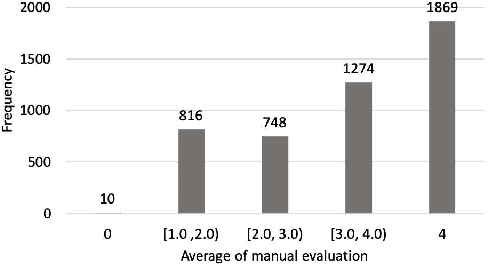
In grammatical error correction (GEC), automatic evaluation is an important factor for research and development of GEC systems. Previous studies on automatic evaluation have demonstrated that quality estimation models built from datasets with manual evaluation can achieve high performance in automatic evaluation of English GEC without using reference sentences.. However, quality estimation models have not yet been studied in Japanese, because there are no datasets for constructing quality estimation models. Therefore, in this study, we created a quality estimation dataset with manual evaluation to build an automatic evaluation model for Japanese GEC. Moreover, we conducted a meta-evaluation to verify the dataset's usefulness in building the Japanese quality estimation model.
Keyframe Segmentation and Positional Encoding for Video-guided Machine Translation Challenge 2020
Jun 23, 2020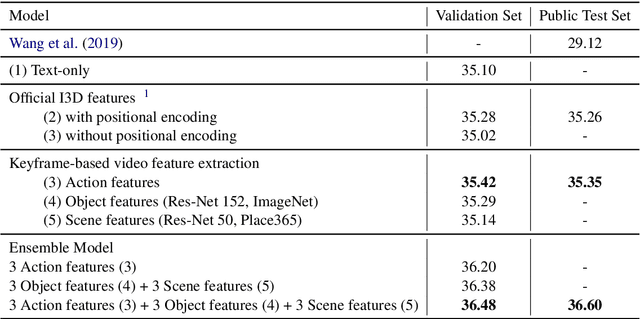

Video-guided machine translation as one of multimodal neural machine translation tasks targeting on generating high-quality text translation by tangibly engaging both video and text. In this work, we presented our video-guided machine translation system in approaching the Video-guided Machine Translation Challenge 2020. This system employs keyframe-based video feature extractions along with the video feature positional encoding. In the evaluation phase, our system scored 36.60 corpus-level BLEU-4 and achieved the 1st place on the Video-guided Machine Translation Challenge 2020.