 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Optimal Matrix Multiplicative Weight Update and Its Quantum Applications
Sep 10, 2025The Matrix Multiplicative Weight Update (MMWU) is a seminal online learning algorithm with numerous applications. Applied to the matrix version of the Learning from Expert Advice (LEA) problem on the $d$-dimensional spectraplex, it is well known that MMWU achieves the minimax-optimal regret bound of $O(\sqrt{T\log d})$, where $T$ is the time horizon. In this paper, we present an improved algorithm achieving the instance-optimal regret bound of $O(\sqrt{T\cdot S(X||d^{-1}I_d)})$, where $X$ is the comparator in the regret, $I_d$ is the identity matrix, and $S(\cdot||\cdot)$ denotes the quantum relative entropy. Furthermore, our algorithm has the same computational complexity as MMWU, indicating that the improvement in the regret bound is ``free''. Technically, we first develop a general potential-based framework for matrix LEA, with MMWU being its special case induced by the standard exponential potential. Then, the crux of our analysis is a new ``one-sided'' Jensen's trace inequality built on a Laplace transform technique, which allows the application of general potential functions beyond exponential to matrix LEA. Our algorithm is finally induced by an optimal potential function from the vector LEA problem, based on the imaginary error function. Complementing the above, we provide a memory lower bound for matrix LEA, and explore the applications of our algorithm in quantum learning theory. We show that it outperforms the state of the art for learning quantum states corrupted by depolarization noise, random quantum states, and Gibbs states. In addition, applying our algorithm to linearized convex losses enables predicting nonlinear quantum properties, such as purity, quantum virtual cooling, and R\'{e}nyi-$2$ correlation.
QCircuitNet: A Large-Scale Hierarchical Dataset for Quantum Algorithm Design
Oct 10, 2024



Quantum computing is an emerging field recognized for the significant speedup it offers over classical computing through quantum algorithms. However, designing and implementing quantum algorithms pose challenges due to the complex nature of quantum mechanics and the necessity for precise control over quantum states. Despite the significant advancements in AI, there has been a lack of datasets specifically tailored for this purpose. In this work, we introduce QCircuitNet, the first benchmark and test dataset designed to evaluate AI's capability in designing and implementing quantum algorithms in the form of quantum circuit codes. Unlike using AI for writing traditional codes, this task is fundamentally different and significantly more complicated due to highly flexible design space and intricate manipulation of qubits. Our key contributions include: 1. A general framework which formulates the key features of quantum algorithm design task for Large Language Models. 2. Implementation for a wide range of quantum algorithms from basic primitives to advanced applications, with easy extension to more quantum algorithms. 3. Automatic validation and verification functions, allowing for iterative evaluation and interactive reasoning without human inspection. 4. Promising potential as a training dataset through primitive fine-tuning results. We observed several interesting experimental phenomena: fine-tuning does not always outperform few-shot learning, and LLMs tend to exhibit consistent error patterns. QCircuitNet provides a comprehensive benchmark for AI-driven quantum algorithm design, offering advantages in model evaluation and improvement, while also revealing some limitations of LLMs in this domain.
Comparisons Are All You Need for Optimizing Smooth Functions
May 19, 2024When optimizing machine learning models, there are various scenarios where gradient computations are challenging or even infeasible. Furthermore, in reinforcement learning (RL), preference-based RL that only compares between options has wide applications, including reinforcement learning with human feedback in large language models. In this paper, we systematically study optimization of a smooth function $f\colon\mathbb{R}^n\to\mathbb{R}$ only assuming an oracle that compares function values at two points and tells which is larger. When $f$ is convex, we give two algorithms using $\tilde{O}(n/\epsilon)$ and $\tilde{O}(n^{2})$ comparison queries to find an $\epsilon$-optimal solution, respectively. When $f$ is nonconvex, our algorithm uses $\tilde{O}(n/\epsilon^2)$ comparison queries to find an $\epsilon$-approximate stationary point. All these results match the best-known zeroth-order algorithms with function evaluation queries in $n$ dependence, thus suggest that \emph{comparisons are all you need for optimizing smooth functions using derivative-free methods}. In addition, we also give an algorithm for escaping saddle points and reaching an $\epsilon$-second order stationary point of a nonconvex $f$, using $\tilde{O}(n^{1.5}/\epsilon^{2.5})$ comparison queries.
Quantum Langevin Dynamics for Optimization
Nov 27, 2023We initiate the study of utilizing Quantum Langevin Dynamics (QLD) to solve optimization problems, particularly those non-convex objective functions that present substantial obstacles for traditional gradient descent algorithms. Specifically, we examine the dynamics of a system coupled with an infinite heat bath. This interaction induces both random quantum noise and a deterministic damping effect to the system, which nudge the system towards a steady state that hovers near the global minimum of objective functions. We theoretically prove the convergence of QLD in convex landscapes, demonstrating that the average energy of the system can approach zero in the low temperature limit with an exponential decay rate correlated with the evolution time. Numerically, we first show the energy dissipation capability of QLD by retracing its origins to spontaneous emission. Furthermore, we conduct detailed discussion of the impact of each parameter. Finally, based on the observations when comparing QLD with classical Fokker-Plank-Smoluchowski equation, we propose a time-dependent QLD by making temperature and $\hbar$ time-dependent parameters, which can be theoretically proven to converge better than the time-independent case and also outperforms a series of state-of-the-art quantum and classical optimization algorithms in many non-convex landscapes.
Near-Optimal Quantum Coreset Construction Algorithms for Clustering
Jun 05, 2023
$k$-Clustering in $\mathbb{R}^d$ (e.g., $k$-median and $k$-means) is a fundamental machine learning problem. While near-linear time approximation algorithms were known in the classical setting for a dataset with cardinality $n$, it remains open to find sublinear-time quantum algorithms. We give quantum algorithms that find coresets for $k$-clustering in $\mathbb{R}^d$ with $\tilde{O}(\sqrt{nk}d^{3/2})$ query complexity. Our coreset reduces the input size from $n$ to $\mathrm{poly}(k\epsilon^{-1}d)$, so that existing $\alpha$-approximation algorithms for clustering can run on top of it and yield $(1 + \epsilon)\alpha$-approximation. This eventually yields a quadratic speedup for various $k$-clustering approximation algorithms. We complement our algorithm with a nearly matching lower bound, that any quantum algorithm must make $\Omega(\sqrt{nk})$ queries in order to achieve even $O(1)$-approximation for $k$-clustering.
Logarithmic-Regret Quantum Learning Algorithms for Zero-Sum Games
Apr 27, 2023

We propose the first online quantum algorithm for zero-sum games with $\tilde O(1)$ regret under the game setting. Moreover, our quantum algorithm computes an $\varepsilon$-approximate Nash equilibrium of an $m \times n$ matrix zero-sum game in quantum time $\tilde O(\sqrt{m+n}/\varepsilon^{2.5})$, yielding a quadratic improvement over classical algorithms in terms of $m, n$. Our algorithm uses standard quantum inputs and generates classical outputs with succinct descriptions, facilitating end-to-end applications. As an application, we obtain a fast quantum linear programming solver. Technically, our online quantum algorithm "quantizes" classical algorithms based on the optimistic multiplicative weight update method. At the heart of our algorithm is a fast quantum multi-sampling procedure for the Gibbs sampling problem, which may be of independent interest.
Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret
Feb 21, 2023While quantum reinforcement learning (RL) has attracted a surge of attention recently, its theoretical understanding is limited. In particular, it remains elusive how to design provably efficient quantum RL algorithms that can address the exploration-exploitation trade-off. To this end, we propose a novel UCRL-style algorithm that takes advantage of quantum computing for tabular Markov decision processes (MDPs) with $S$ states, $A$ actions, and horizon $H$, and establish an $\mathcal{O}(\mathrm{poly}(S, A, H, \log T))$ worst-case regret for it, where $T$ is the number of episodes. Furthermore, we extend our results to quantum RL with linear function approximation, which is capable of handling problems with large state spaces. Specifically, we develop a quantum algorithm based on value target regression (VTR) for linear mixture MDPs with $d$-dimensional linear representation and prove that it enjoys $\mathcal{O}(\mathrm{poly}(d, H, \log T))$ regret. Our algorithms are variants of UCRL/UCRL-VTR algorithms in classical RL, which also leverage a novel combination of lazy updating mechanisms and quantum estimation subroutines. This is the key to breaking the $\Omega(\sqrt{T})$-regret barrier in classical RL. To the best of our knowledge, this is the first work studying the online exploration in quantum RL with provable logarithmic worst-case regret.
Quantum Algorithms for Sampling Log-Concave Distributions and Estimating Normalizing Constants
Oct 12, 2022
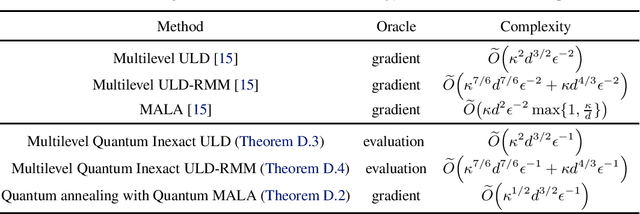
Given a convex function $f\colon\mathbb{R}^{d}\to\mathbb{R}$, the problem of sampling from a distribution $\propto e^{-f(x)}$ is called log-concave sampling. This task has wide applications in machine learning, physics, statistics, etc. In this work, we develop quantum algorithms for sampling log-concave distributions and for estimating their normalizing constants $\int_{\mathbb{R}^d}e^{-f(x)}\mathrm{d} x$. First, we use underdamped Langevin diffusion to develop quantum algorithms that match the query complexity (in terms of the condition number $\kappa$ and dimension $d$) of analogous classical algorithms that use gradient (first-order) queries, even though the quantum algorithms use only evaluation (zeroth-order) queries. For estimating normalizing constants, these algorithms also achieve quadratic speedup in the multiplicative error $\epsilon$. Second, we develop quantum Metropolis-adjusted Langevin algorithms with query complexity $\widetilde{O}(\kappa^{1/2}d)$ and $\widetilde{O}(\kappa^{1/2}d^{3/2}/\epsilon)$ for log-concave sampling and normalizing constant estimation, respectively, achieving polynomial speedups in $\kappa,d,\epsilon$ over the best known classical algorithms by exploiting quantum analogs of the Monte Carlo method and quantum walks. We also prove a $1/\epsilon^{1-o(1)}$ quantum lower bound for estimating normalizing constants, implying near-optimality of our quantum algorithms in $\epsilon$.
On Quantum Speedups for Nonconvex Optimization via Quantum Tunneling Walks
Sep 29, 2022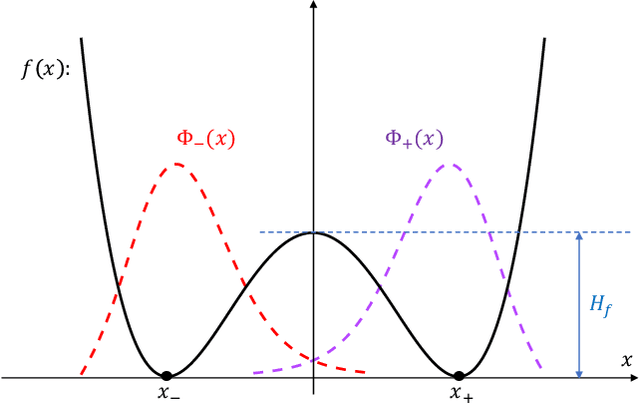

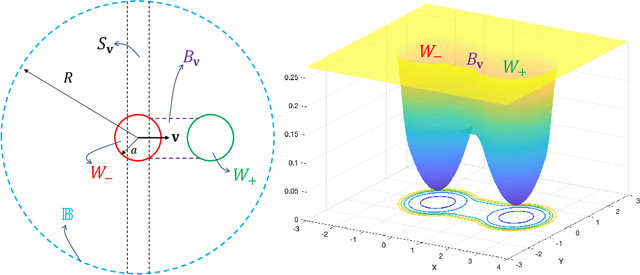
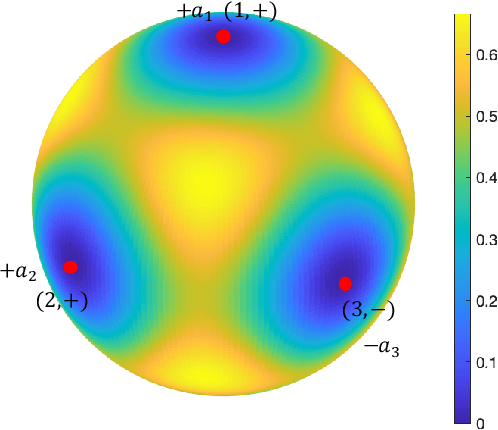
Classical algorithms are often not effective for solving nonconvex optimization problems where local minima are separated by high barriers. In this paper, we explore possible quantum speedups for nonconvex optimization by leveraging the global effect of quantum tunneling. Specifically, we introduce a quantum algorithm termed the quantum tunneling walk (QTW) and apply it to nonconvex problems where local minima are approximately global minima. We show that QTW achieves quantum speedup over classical stochastic gradient descents (SGD) when the barriers between different local minima are high but thin and the minima are flat. Based on this observation, we construct a specific double-well landscape, where classical algorithms cannot efficiently hit one target well knowing the other well but QTW can when given proper initial states near the known well. Finally, we corroborate our findings with numerical experiments.
Quantum Speedups of Optimizing Approximately Convex Functions with Applications to Logarithmic Regret Stochastic Convex Bandits
Sep 26, 2022We initiate the study of quantum algorithms for optimizing approximately convex functions. Given a convex set ${\cal K}\subseteq\mathbb{R}^{n}$ and a function $F\colon\mathbb{R}^{n}\to\mathbb{R}$ such that there exists a convex function $f\colon\mathcal{K}\to\mathbb{R}$ satisfying $\sup_{x\in{\cal K}}|F(x)-f(x)|\leq \epsilon/n$, our quantum algorithm finds an $x^{*}\in{\cal K}$ such that $F(x^{*})-\min_{x\in{\cal K}} F(x)\leq\epsilon$ using $\tilde{O}(n^{3})$ quantum evaluation queries to $F$. This achieves a polynomial quantum speedup compared to the best-known classical algorithms. As an application, we give a quantum algorithm for zeroth-order stochastic convex bandits with $\tilde{O}(n^{5}\log^{2} T)$ regret, an exponential speedup in $T$ compared to the classical $\Omega(\sqrt{T})$ lower bound. Technically, we achieve quantum speedup in $n$ by exploiting a quantum framework of simulated annealing and adopting a quantum version of the hit-and-run walk. Our speedup in $T$ for zeroth-order stochastic convex bandits is due to a quadratic quantum speedup in multiplicative error of mean estimation.